-
セキュリティ情報およびイベント管理 (SIEM) 統合と開始
-
Citrix Analytics アドオンアプリケーションによる Splunk アーキテクチャ
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
Splunk と Citrix Analytics アドオンアプリケーションのアーキテクチャ
Splunk は、以下の 3 つの層で構成されるアーキテクチャに従います。
- 収集
- インデックス作成
- 検索
Splunk は、データを Splunk に簡単に取り込み、インデックスを作成して検索可能にするのに役立つ幅広いデータ収集メカニズムをサポートしています。この層は、ヘビーフォワーダーまたはユニバーサルフォワーダーに他なりません。
アドオンアプリケーションは、ユニバーサルフォワーダー層ではなく、ヘビーフォワーダー層にインストールする必要があります。これは、適切に構造化されたデータ (json、csv、tsv など) のいくつかの例外を除き、ユニバーサルフォワーダーはログソースをイベントに解析しないため、ログの形式を理解する必要があるアクションを実行できないためです。
また、Python の簡易版が同梱されているため、完全な Splunk スタックを必要とするモジュラー入力アプリケーションとは互換性がありません。ヘビーフォワーダーは、収集層に他なりません。
ユニバーサルフォワーダーとヘビーフォワーダーの主な違いは、ヘビーフォワーダーが完全な解析パイプラインを含み、実際にディスクにイベントを書き込んでインデックスを作成することなく、インデクサーが実行するのと同一の機能を実行することです。これにより、ヘビーフォワーダーは、データのマスキング、フィルタリング、イベントデータに基づくルーティングなど、個々のイベントを理解し、それに基づいて動作できます。アドオンアプリケーションは完全な Splunk Enterprise インストールであるため、適切なデータ収集のために完全な Python スタックを必要とするモジュラー入力をホストしたり、Splunk HTTP Event Collector (HEC) のエンドポイントとして機能したりできます。
データが収集されると、インデックスが作成または処理され、検索可能な方法で保存されます。
顧客がデータを探索する主な方法は検索です。検索はレポートとして保存し、ダッシュボードパネルの作成に使用できます。検索はデータから情報を抽出します。
一般的に、Splunk アドオンアプリケーションは収集層 (Splunk Enterprise レベル) にデプロイされ、ダッシュボードアプリケーションは検索層 (Splunk Cloud レベル) にデプロイされます。シンプルなオンプレミス環境では、これら 3 つの層すべてを単一の Splunk ホストに配置できます (シングルサーバーデプロイメントとして知られています)。
収集層は、Splunk 用アドオンアプリケーションを使用するはるかに優れた方法です。アドオンアプリケーションをインストールする方法は 2 つあります。顧客環境下の収集層にインストールするか、Splunk Cloud インスタンス下の入力データマネージャーにインストールできます。
アドオンアプリケーションを使用した Splunk デプロイメントアーキテクチャを理解するには、次の図を参照してください。
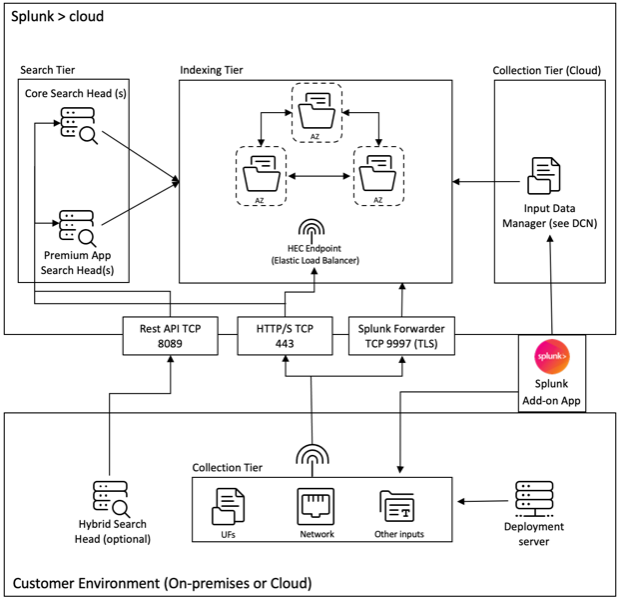
上記の図に示されている入力データマネージャー (IDM) は、スクリプト化されたモジュラー入力のみをサポートする、Splunk Cloud が管理するデータ収集ノード (DCN) の実装です。それ以上のデータ収集のニーズについては、Splunk ヘビーフォワーダーを使用して、環境に DCN をデプロイおよび管理できます。
Splunk は、さまざまなソースからデータを収集、インデックス作成、検索することを可能にします。データを収集する 1 つの方法は API を介することであり、これにより Splunk は他のシステムやアプリケーションに保存されているデータにアクセスできます。これらの API には、クエリメカニズムとして REST、Web サービス、JMS、および/または JDBC が含まれる場合があります。Splunk およびサードパーティ開発者は、Splunk モジュラー入力フレームワークを介した API インタラクションを可能にするさまざまなアプリケーションを提供しています。これらのアプリケーションは通常、適切に機能するために完全な Splunk Enterprise ソフトウェアのインストールを必要とします。
API を介したデータ収集を容易にするために、ヘビーフォワーダーを DCN としてデプロイするのが一般的です。ヘビーフォワーダーは、完全な解析パイプラインを含み、個々のイベントを理解してそれに基づいて動作できるため、ユニバーサルフォワーダーよりも強力なエージェントです。これにより、API を介してデータを収集し、Splunk インスタンスに転送してインデックスを作成する前に処理できます。
Splunk Cloud デプロイメントのハイレベルアーキテクチャの詳細については、Splunk Validated Architectures を参照してください。
共有
共有
この記事の概要
This Preview product documentation is Citrix Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Citrix Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Citrix product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.