アラートと通知
アラートは、ディレクターのダッシュボードやその他の高レベルビューに、警告および重大なアラートシンボルとともに表示されます。アラートは、Premiumライセンスサイトで利用できます。アラートは1分ごとに自動的に更新されます。また、オンデマンドでアラートを更新することもできます。
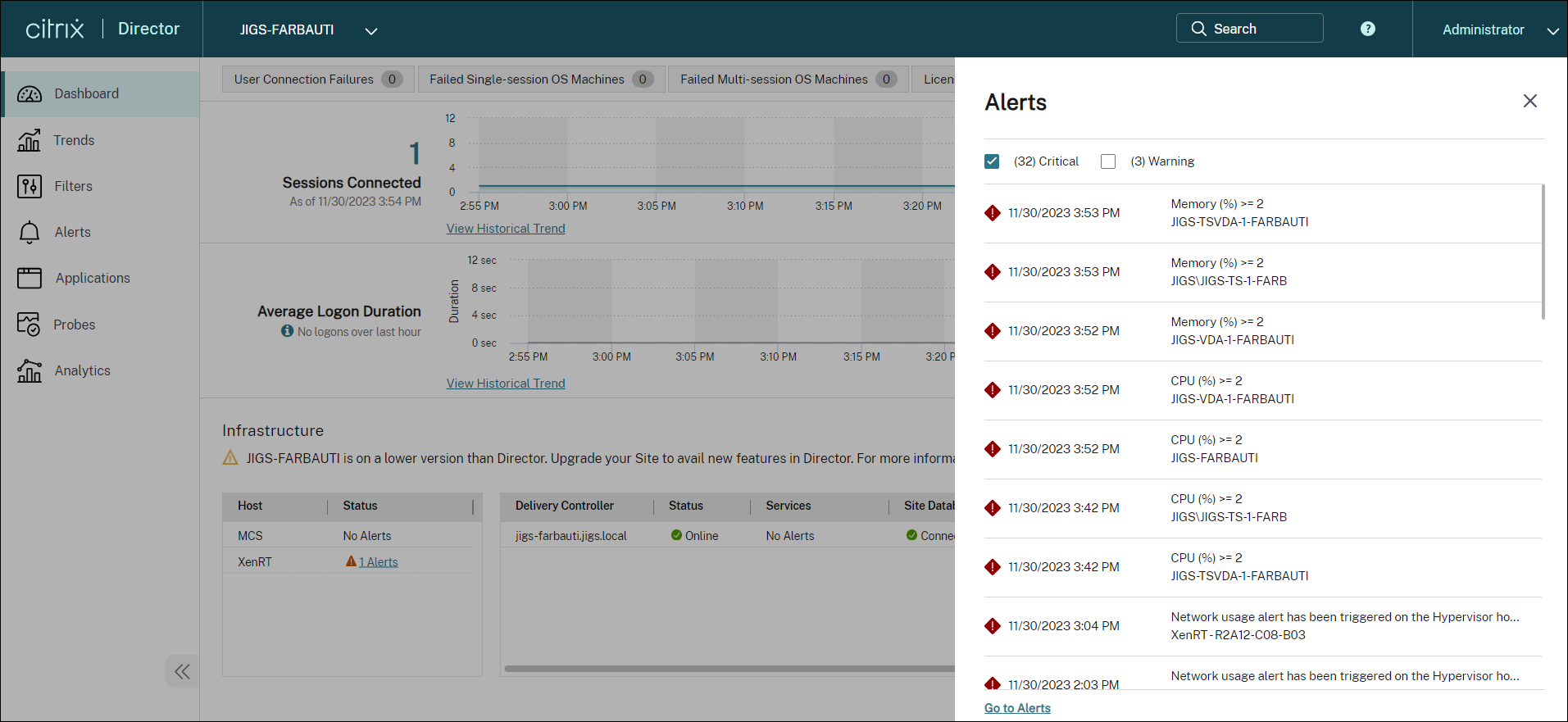
警告アラート(琥珀色の三角形)は、条件の警告しきい値に達したか、それを超えたことを示します。
重大なアラート(赤い円)は、条件の重大なしきい値に達したか、それを超えたことを示します。
アラートに関する詳細情報は、サイドバーからアラートを選択するか、サイドバーの下部にある [アラートに移動] リンクをクリックするか、ディレクターページの上部から [アラート] を選択することで表示できます。
アラートビューでは、アラートをフィルタリングおよびエクスポートできます。たとえば、先月の特定のデリバリーグループの失敗したマルチセッションOSマシン、または特定のユーザーのすべてのアラートなどです。詳細については、「レポートのエクスポート」を参照してください。
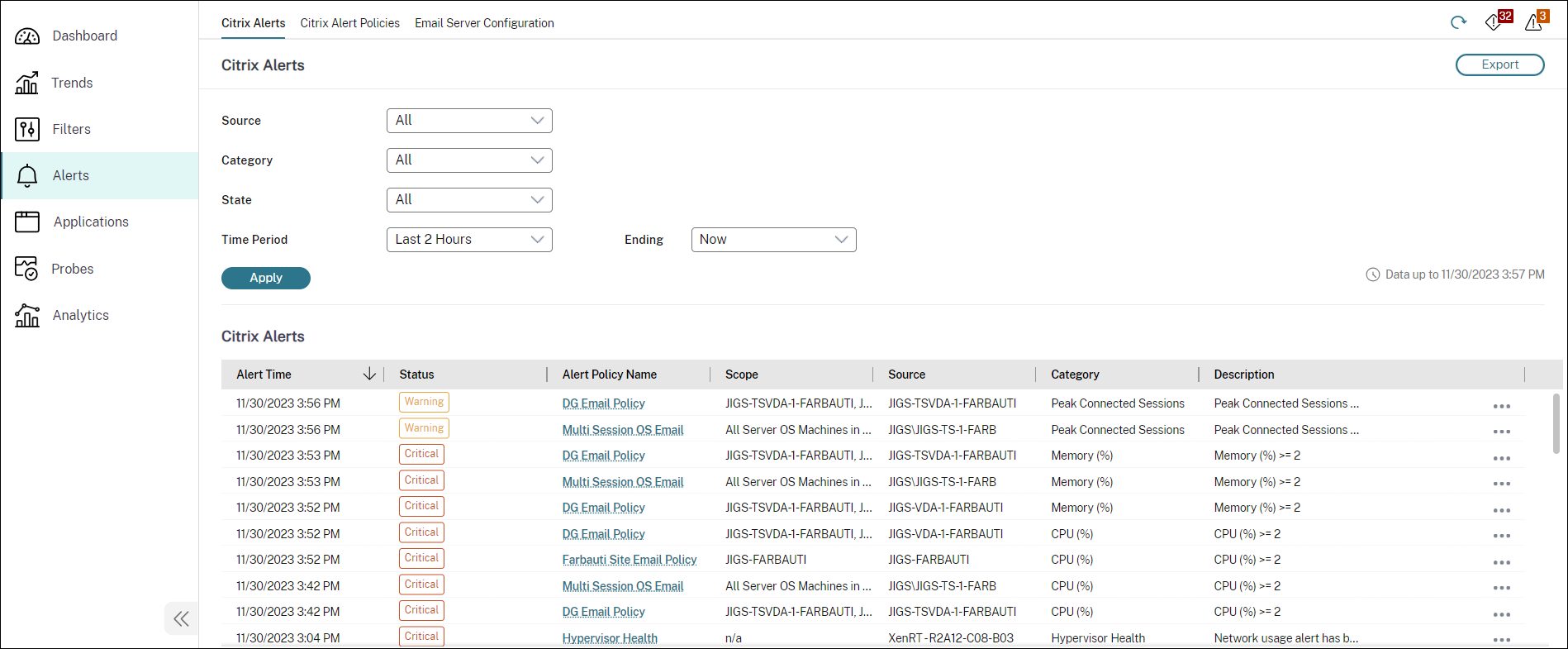
Citrix®アラート
Citrixアラートは、Citrixコンポーネントから発生し、ディレクターで監視されるアラートです。Citrixアラートは、ディレクターの [アラート] > [Citrixアラートポリシー] で構成できます。構成の一部として、アラートが設定したしきい値を超えた場合に、個人およびグループに電子メールで通知を送信するように設定できます。Citrixアラートの設定の詳細については、「アラートポリシーの作成」を参照してください。
注:
ファイアウォール、プロキシ、またはMicrosoft Exchange Serverが電子メールアラートをブロックしないようにしてください。
スマートアラートポリシー
- 事前定義されたしきい値を持つ組み込みアラートポリシーのセットは、デリバリーグループおよびマルチセッションOS VDAスコープで利用できます。この機能には、Delivery Controllerバージョン7.18以降が必要です。組み込みアラートポリシーのしきい値パラメーターは、[アラート] > [Citrixアラートポリシー] で変更できます。
- これらのポリシーは、サイトに少なくとも1つのアラートターゲット(デリバリーグループまたはマルチセッションOS VDA)が定義されている場合に作成されます。さらに、これらの組み込みアラートは、新しいデリバリーグループまたはマルチセッションOS VDAに自動的に追加されます。
ディレクターとサイトをアップグレードした場合、以前のディレクターインスタンスからのアラートポリシーは引き継がれます。組み込みアラートポリシーは、Monitorデータベースに対応するアラートルールが存在しない場合にのみ作成されます。
組み込みアラートポリシーのしきい値については、「アラートポリシーの条件」セクションを参照してください。
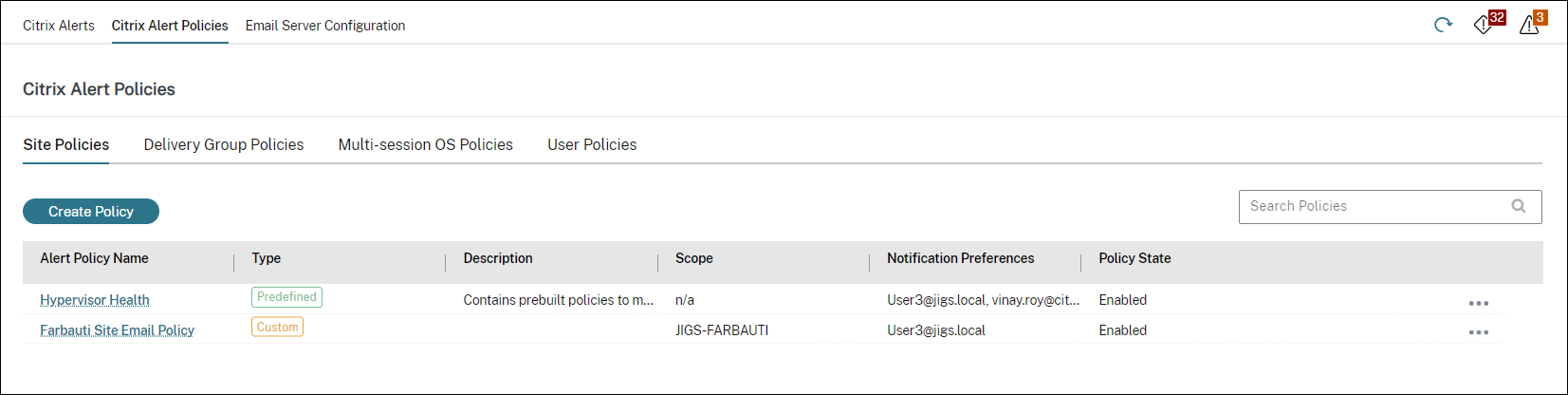
高度なアラートポリシー
- ディレクターのプロアクティブな通知およびアラート機能は、**高度なアラートポリシー**という新しいアラートフレームワークを含むように強化されています。この機能を使用すると、各要素または条件の詳細な情報を含めてアラートを作成できるため、アラートスコープの制御が強化されます。現在、これらのポリシーには、コスト削減とインフラストラクチャに関するアラートが含まれています。
- データソース駆動型アラートである高度なアラートポリシーの導入により、複数条件スコープフィルタリングを使用できます。
この機能は、過剰なアラートを削減するのに役立ち、応答性や重要な問題への対処の有効性の低下につながる可能性があります。このポリシーは、アラートポリシーの有効性と管理者からのエンゲージメントを測定するのに役立ちます。
- 高度なアラートポリシーは、**[アラート]** \> **[高度なアラートポリシー]** \> **[ポリシーの作成]** セクションから作成できます。
- 次のデータソースのいずれかを選択できます。
- マシン
- Provisioning Service
- StoreFront™
- Delivery Controller™
コスト削減のためのアラート
- コストを最適化するのに役立つコスト削減のためのアラートを作成できます。現在、マシン用のアラートを作成できます。
マシンでアラートを作成するには、次の手順を実行します。
- [アラート] タブ > [高度なアラートポリシー] をクリックします。[高度なアラートポリシー] ページが表示されます。
-
[ポリシーの作成] をクリックします。[高度なアラートポリシーの作成] セクションが表示されます。 - 1. データソースドロップダウンリストから [マシン] を選択します。コスト削減条件と対応する条件タイプが表示されます。
- 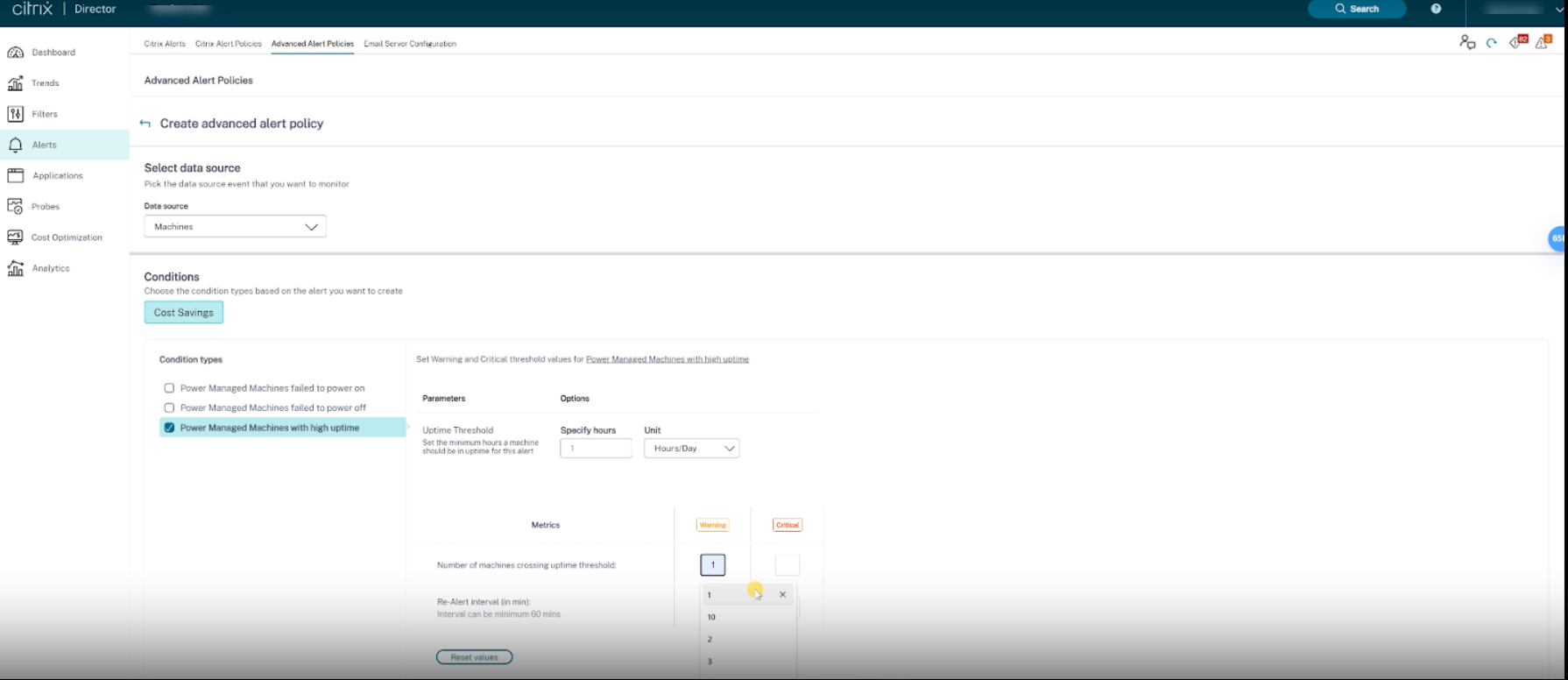 - 1. 必要に応じて、次の条件タイプを選択します。 - 電源管理対象マシンが起動に失敗しました - 電源管理対象マシンがシャットダウンに失敗しました - 稼働時間の長い電源管理対象マシン
-
- 選択した各条件について、特定のパラメーターと対応するオプションを選択します。
-
- 選択した条件タイプについて、警告および重大なメトリックを設定します。
-
稼働時間の長い電源管理対象マシンについて:
- 稼働時間しきい値を超過するマシンの数
- 再アラート間隔(分単位)。間隔は最小60分です。
-
電源管理対象マシンが起動に失敗した場合と電源管理対象マシンがシャットダウンに失敗した場合について:
- 稼働時間しきい値を超過するマシンの数
- サンプリング間隔(分単位)。間隔は30分の倍数です。
- 再アラート間隔(分単位)。再アラートは60分の倍数です。
- 必要に応じて、選択したアラートの再アラート間隔をスケジュールします。
- アラートのスコープを定義します。
-
通知チャネルを設定します。これは電子メールまたはWebhookにすることができます。
-
次のチェックボックスを選択できます。
- WebhookにJSONペイロードを添付ファイルとして含める
- 電子メールにCSVファイルを添付ファイルとして含める
詳細については、「アラートコンテンツの機能強化」を参照してください。
-
- アラートの詳細 (例: アラート名、説明 (オプション)) を入力します。
- 保存をクリックします。アラートが作成されます。
インフラストラクチャ監視のアラート
サポートされている以下のCitrix Virtual Apps and Desktops™コンポーネントの健全性を監視するアラートを作成できます。
-
Provisioning Service
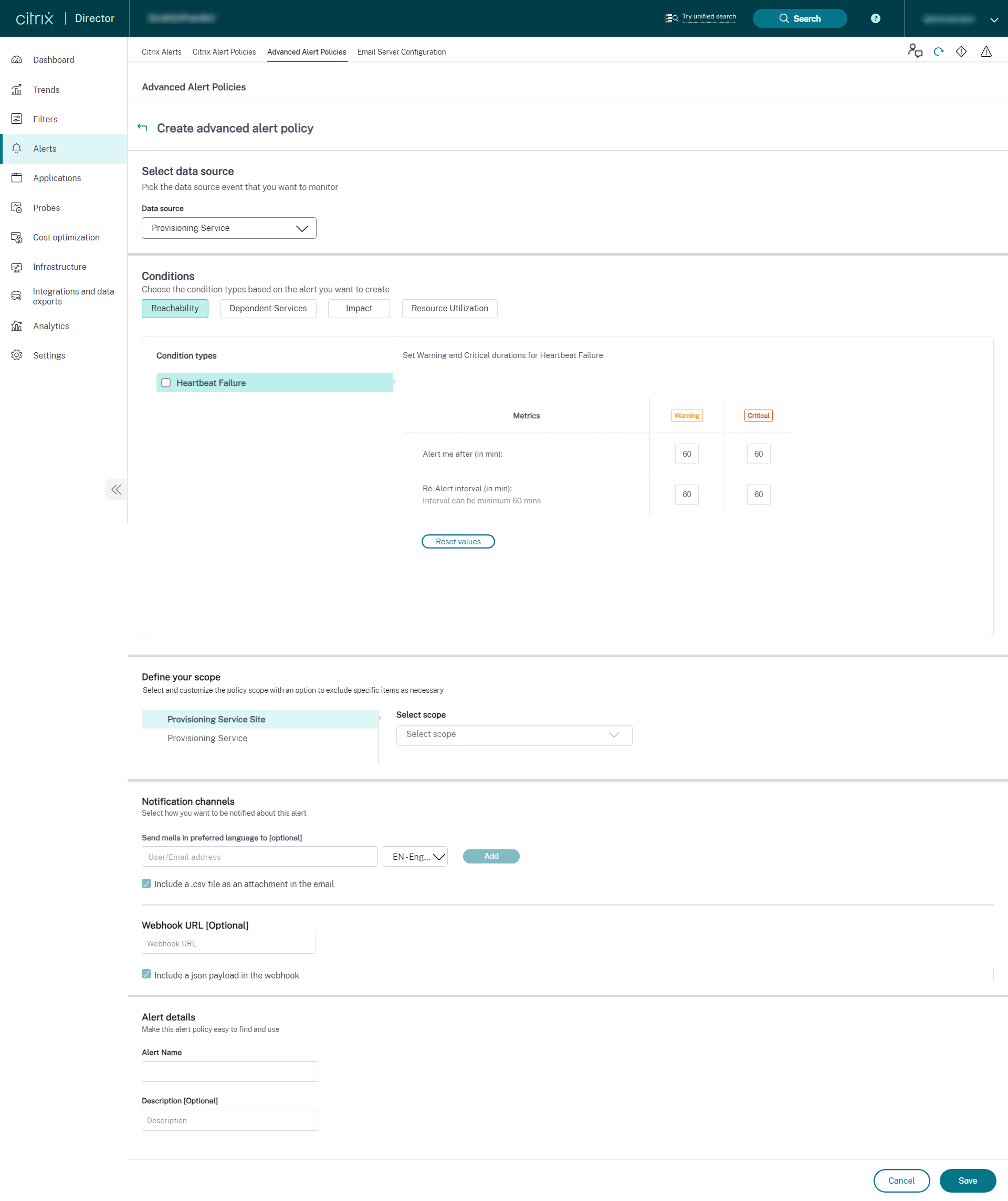
-
StoreFront
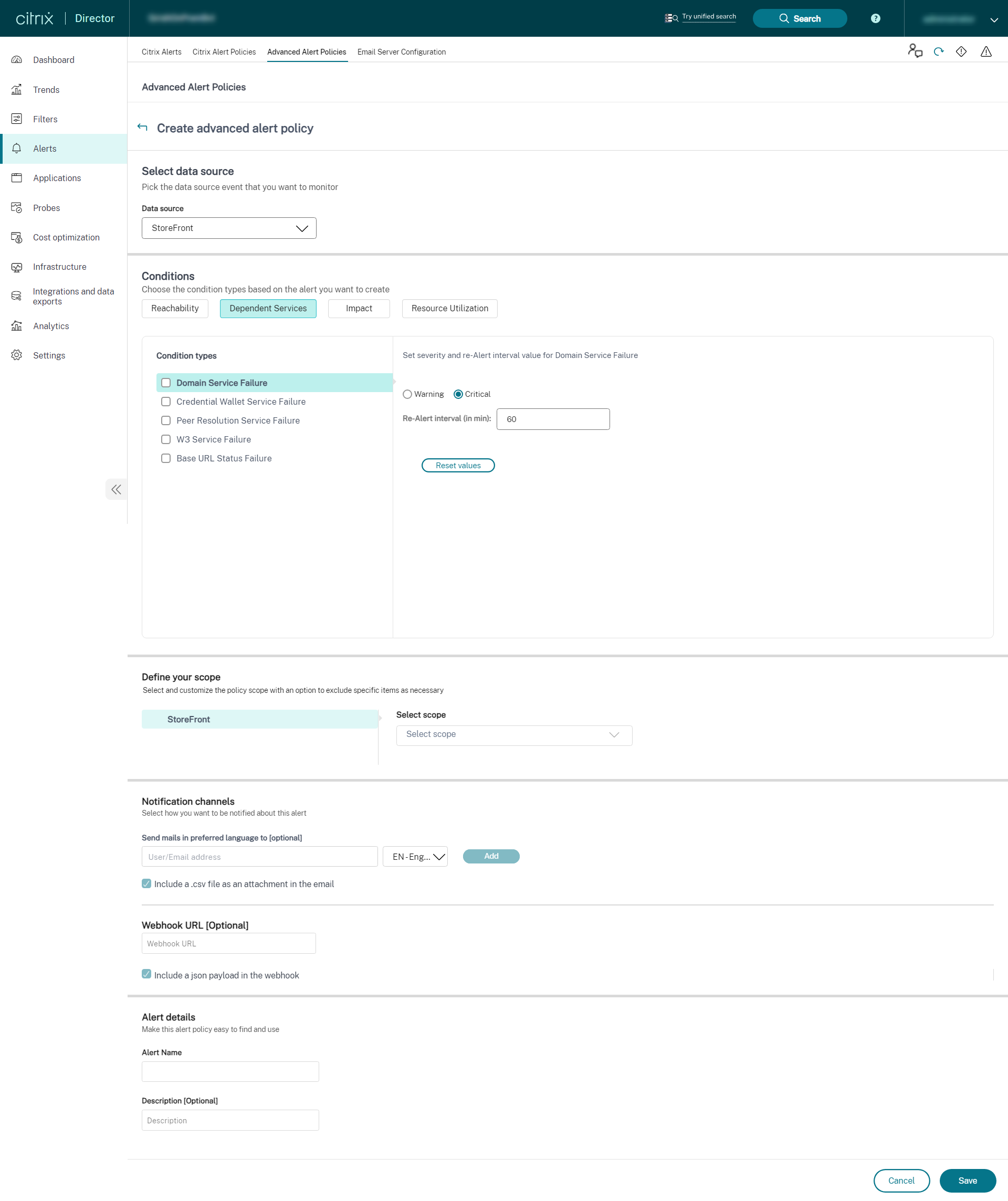
-
Delivery Controller
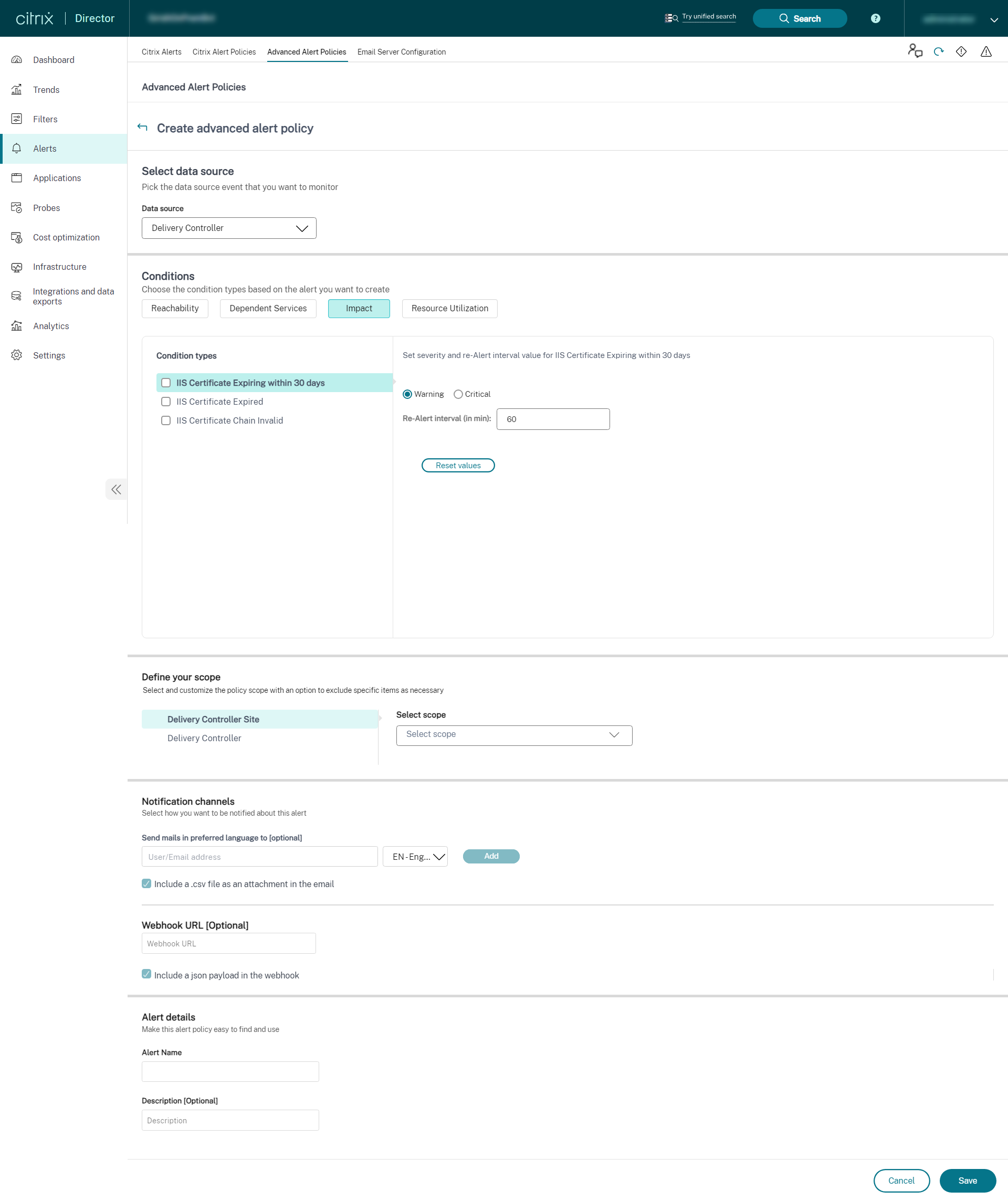
インフラストラクチャ監視のセットアップが完了すると、Directorで利用可能なヘルスデータを使用して、必要なコンポーネントのアラートを設定できます。管理者は、条件、スコープ、通知媒体を設定して、メールまたはWebhook経由のJSONペイロードで重要なアラートを受信できます。Provisioning ServiceおよびDelivery Controllerの場合、アラートのスコープをサイトレベルまたは個々のサーバーレベルのいずれかとして選択できます。たとえば、Provisioning Serviceの場合、「すべてのProvisioning Service」を選択すると、サイトに2台のサーバーがある場合でも、サイト全体に対して1つのアラートのみを受信します。これはサイトレベルのアラートと見なされます。発生したアラートは、分析と管理のためにCitrix Alertsセクションでも利用できます。
新しく導入されたインフラストラクチャポリシーの一部として、アラート条件は次の4つのセクションに分類されます。
- 到達可能性
- 依存サービス
- 影響
- リソース使用率
各カテゴリ内の条件は、組織の優先順位に基づいて重大および警告の重大度で設定できます。これらのアラートの再アラート間隔をスケジュールすることもできます。
アラート > Citrixアラートポリシーセクションからインフラストラクチャポリシーを作成できます。必要なカテゴリを選択し、ポリシーに必要な条件を選択できます。ポリシーの作成方法の詳細については、「アラートポリシーの作成」を参照してください。ポリシーが作成された後、Citrix Alertsページでポリシーを編集、削除、または無効にできます。
各カテゴリおよびコンポーネントでサポートされている条件の詳細については、以下を参照してください。
メールまたはCitrix Alertページでアラートとして受信されるデータは次のとおりです。
| フィールド | 説明 |
|---|---|
| 顧客ID | サイトの顧客ID。 |
| アラートレベル | 可能な値は「重大」と「警告」です。 |
| ターゲット | アラートがトリガーされるマシンの名前。 |
| 時刻 | アラートがトリガーされた時刻。 |
| スコープ | ポリシーのスコープ。 |
| ポリシー | ポリシーの名前。 |
| 説明 | アラートがトリガーされる問題の説明。 |
ポリシーのスコープの定義
アラートのスコープを定義し、例外を追加できます。アラートは選択されたスコープに対してのみ生成され、例外の追加によって除外されたサブスコープはアラート生成に含まれません。この機能は、きめ細かなレベルでアラートを作成するのに役立ちます。
メールまたはWebhook URLを介して通知を作成できます。アラートを受信する希望の言語を選択することもできます。メールの場合は.CSVファイル添付、Webhook URLを介した場合はJSONペイロードでアラートパラメーターを受信するオプションを選択することもできます。添付ファイルには、必要なパラメーターの詳細が含まれています。詳細については、「アラートコンテンツの機能強化」を参照してください。
メールまたはCitrix Alertsページでアラートとして受信されるデータは次のとおりです。
| フィールド | 説明 |
|---|---|
| 顧客ID | サイトの顧客ID。 |
| アラートレベル | この値は、各アラート条件に設定された事前定義値です。可能な値は「重大」と「警告」です。 |
| 条件 | この値は、ポリシー作成時に設定された条件です。たとえば、未登録マシンの数が20以上である場合などです。 |
| ターゲット | アラートがトリガーされるデリバリーグループまたはサイトの名前。 |
| サイト | サイトの名前。 |
| スコープ | ポリシーのスコープ。この値にはサブスコープも含まれます。 |
| ポリシー | ポリシーの名前。 |
| 説明 | アラートがトリガーされる問題の説明。 |
PowerShellスクリプトを使用した高度なアラートポリシーの作成方法
- アラートポリシーを作成するためのPowerShellスクリプト:
asnp Citrix.Monitor.*
# Add Parameters
$timeSpan = New-TimeSpan -Seconds 30
$alertThreshold = 1
$alarmThreshold = 2
# Add Target UID's
$targetIds = @()
$targetIds += "e9a211b4-a1f3-4f74-b6c7-85225902e997"
# Add email addresses
$emailaddress = @()
$emailaddress += "loki@abc.com"
- # Create new policy
- $policy = New-MonitorNotificationPolicy -Name "FailedMachinePercentageAlertCreationViaPowershell" -Description "Policy created to test urm" -Enabled $true
<!--NeedCopy-->
FailedMachinePercentageの正しい条件で次の行を置き換える
Add-MonitorNotificationPolicyCondition -Uid $policy.Uid -ConditionType FailedMachinePercentage -AlertThreshold $alertThreshold -AlarmThreshold $alarmThreshold -AlertRenotification $timeSpan -AlarmRenotification $timeSpan
Add-MonitorNotificationPolicyTargets -Uid $policy.Uid -Scope "DG-Multisession" -TargetKind DesktopGroup -TargetIds $targetIds
$policy = Get-MonitorNotificationPolicy -Uid $policy.Uid
$policy
<!--NeedCopy-->
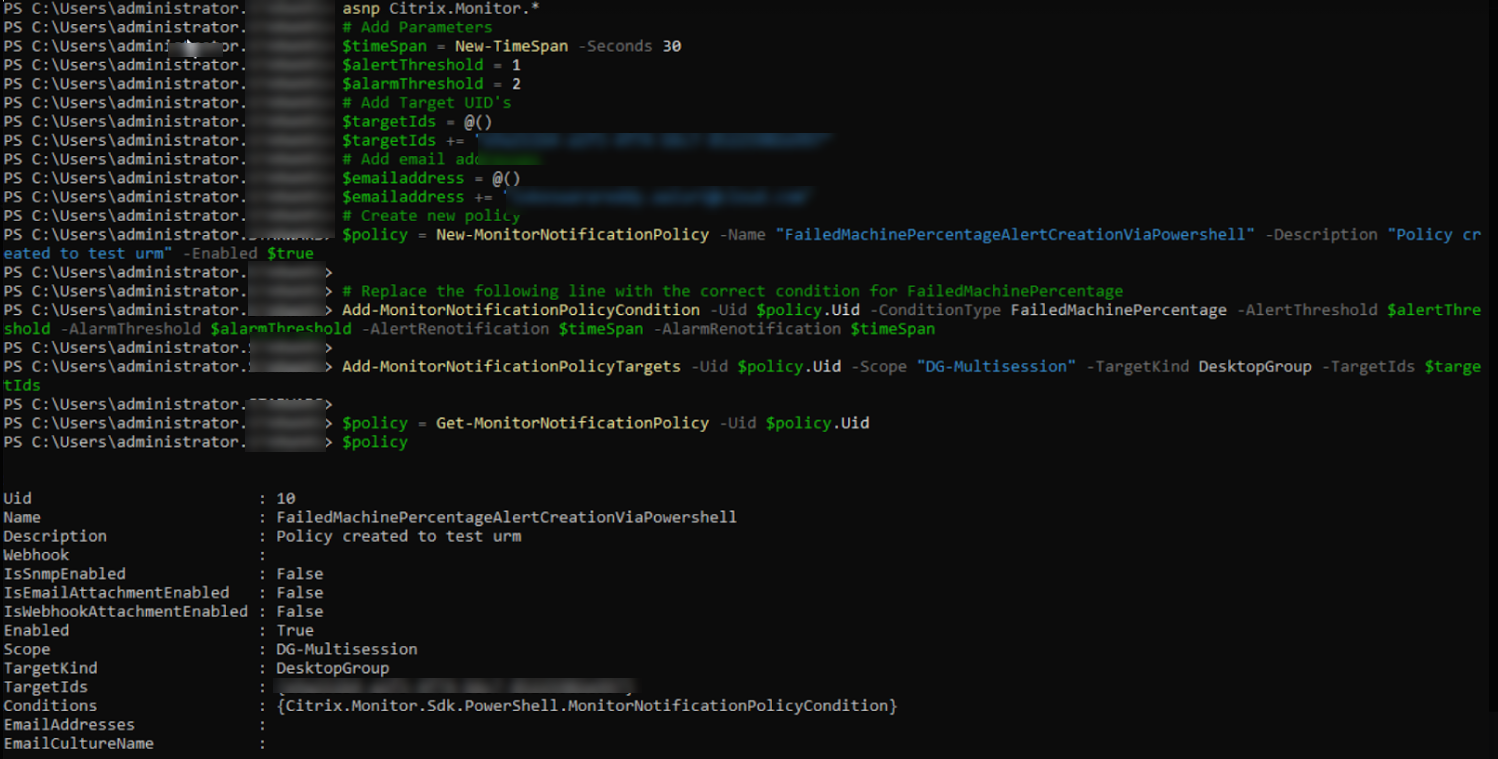
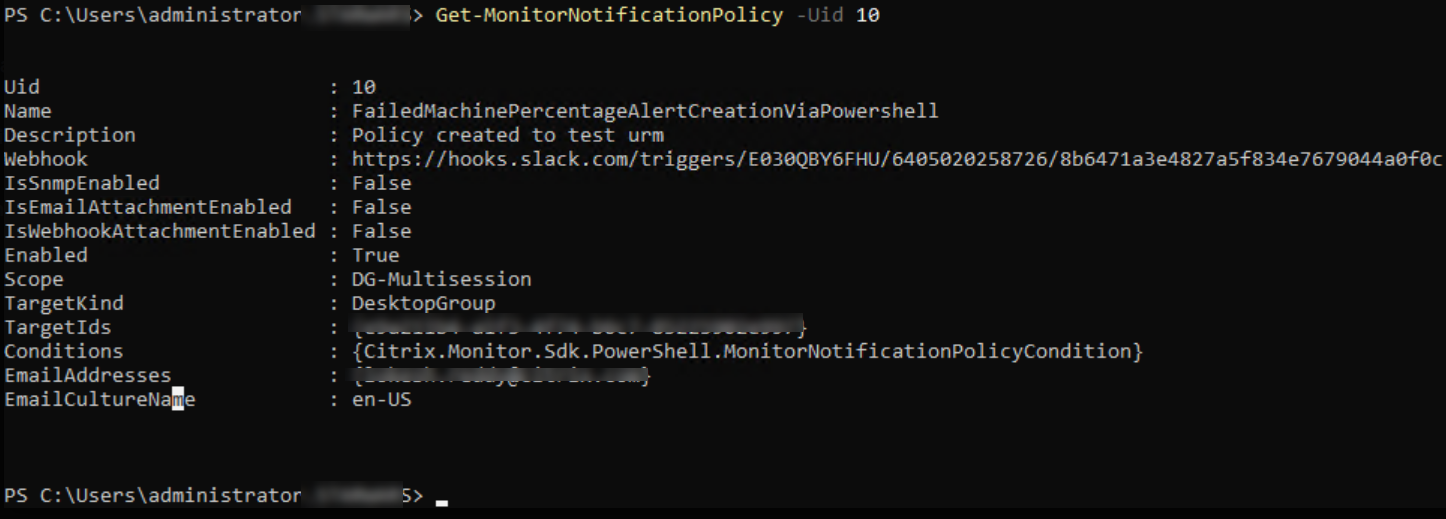
上記の画像から、ポリシーが作成され、Uidが10であることがわかります。
構成にメールを追加する
Set-MonitorNotificationEmailServerConfiguration -ProtocolType SMTP -ServerName NameOfTheSMTPServerOrIPAddress -PortNumber 80 -SenderEmailAddress loki@abc.com -RequiresAuthentication 0
<!--NeedCopy-->
ポリシーにメールを追加する
Add-MonitorNotificationPolicyEmailAddresses -Uid $policy.Uid -EmailAddresses $emailaddress -EmailCultureName "en-US"
<!--NeedCopy-->
メールを追加するサンプルスクリプト:
Add-MonitorNotificationPolicyEmailAddresses -Uid 10 -EmailAddresses $emailaddress -EmailCultureName "en-US"
<!--NeedCopy-->

ポリシーにWebhook URLを追加する
Set-MonitorNotificationPolicy –Uid $polcy.Uid –Webhook 'URL'
<!--NeedCopy-->

- Webhook URLを追加するためのサンプルスクリプト:
Set-MonitorNotificationPolicy –Uid 10 –Webhook 'https://hooks.slack.com/triggers/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'
<!--NeedCopy-->
- Get-MonitorNotificationPolicy -Uid 10
<!--NeedCopy-->
アラートポリシーの作成
-
-
アラートポリシーを作成するには、たとえば、特定のセッション数基準が満たされたときにアラートを生成する場合、次の手順を実行します。
- アラート > Citrixアラートポリシー に移動し、たとえば、マルチセッションOSポリシーを選択します
- 作成 をクリックします
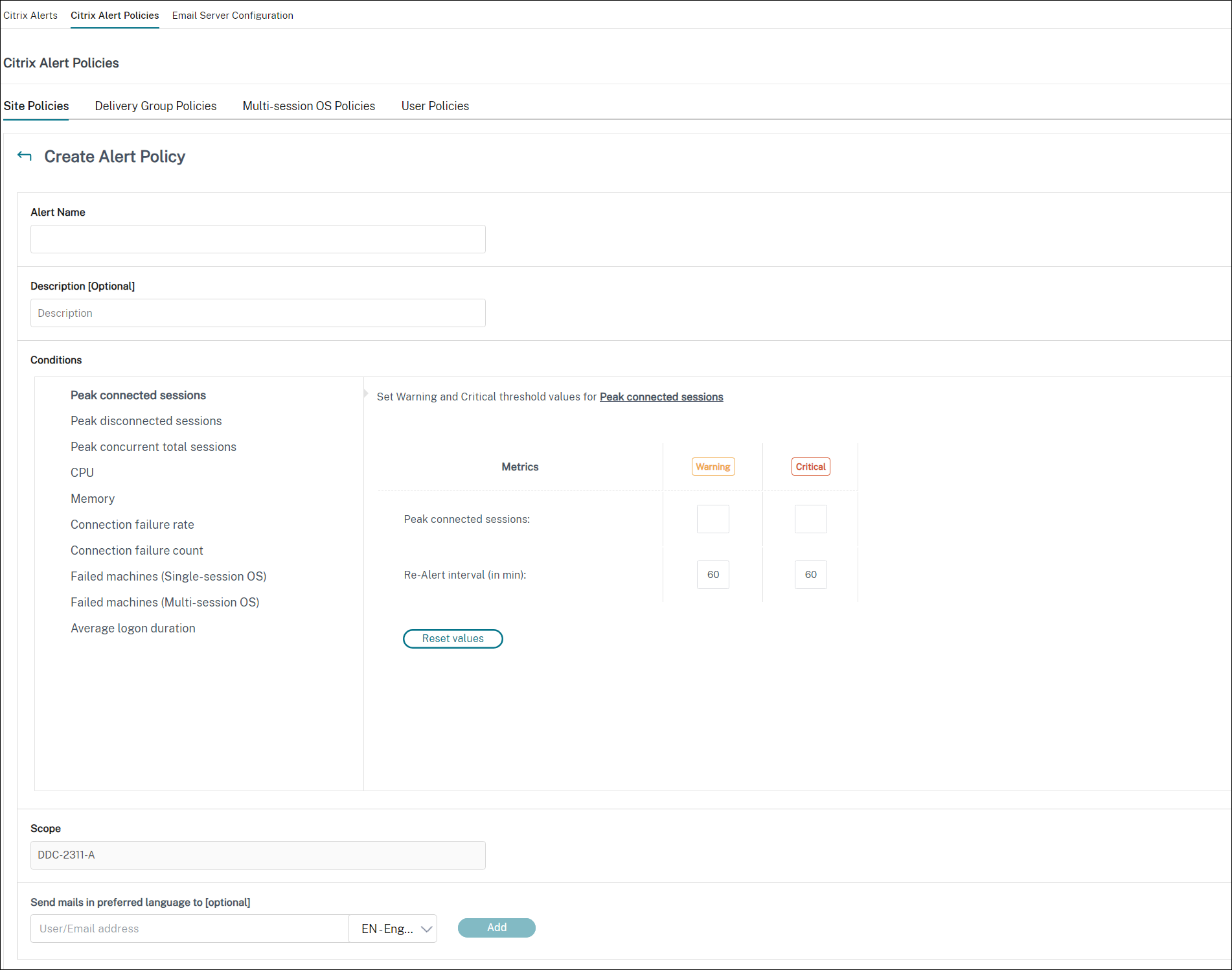
- ポリシーに名前を付けて説明し、アラートがトリガーされるために満たす必要がある条件を設定します。たとえば、ピーク接続セッション、ピーク切断セッション、およびピーク同時合計セッションの警告数とクリティカル数を指定します。警告値はクリティカル値より大きくしてはいけません。詳細については、アラートポリシーの条件を参照してください
-
- 再アラート間隔を設定します。アラートの条件が引き続き満たされている場合、この時間間隔でアラートが再度トリガーされ、アラートポリシーで設定されている場合はメール通知が生成されます。却下されたアラートは、再アラート間隔でメール通知を生成しません
-
- スコープを設定します。たとえば、特定のデリバリーグループに設定します
-
-
通知設定で、アラートがトリガーされたときにメールで通知される必要があるユーザーを指定します。アラートポリシーでメール通知設定を行うには、メールサーバー構成タブでメールサーバーを指定する必要があります
-
- アラートコンテンツを.CSV添付ファイルまたはJSONペイロードで受信することもできます。これを行うには、次のチェックボックスを選択します
- JSONペイロードをWebhookの添付ファイルとして含める
- CSVファイルをメールの添付ファイルとして含める
注:
現在、.CSV添付ファイルおよびJSONペイロードオプションを介してアラートコンテンツを受信できるのは、一部のアラートのみです。詳細については、アラートコンテンツの機能強化を参照してください
-
- 保存 をクリックします
-
スコープに20以上のデリバリーグループが定義されたポリシーを作成すると、構成の完了に約30秒かかる場合があります。この間、スピナーが表示されます。
- 最大20のユニークなデリバリーグループ(合計1000のデリバリーグループターゲット)に対して50を超えるポリシーを作成すると、応答時間が増加する可能性があります(5秒以上)。
アクティブなセッションを含むマシンをあるデリバリーグループから別のデリバリーグループに移動すると、マシンパラメーターを使用して定義された誤ったデリバリーグループアラートがトリガーされる可能性があります。
Directorのアラート機能は、CSV添付ファイルとJSONペイロードを含めるように強化されました。この機能強化により、メールでCSV添付ファイルとして、またはWebhookがある場合はJSONペイロードとしてアラートの詳細を取得できます。このCSV添付ファイルまたはJSONペイロードを使用すると、詳細レベルで豊富なコンテンツを受信でき、問題の迅速な特定と解決に役立ちます。
-
現在、この機能強化は次のアラートでのみ利用可能です。
- マシンの稼働時間
- 電源オンアクションの失敗
- 電源オフアクションの失敗
-
未登録マシン (%)
-
この機能を使用するには、アラートに移動し、次のチェックボックスを選択します。
- JSONペイロードをWebhookの添付ファイルとして含める
- CSVファイルをメールの添付ファイルとして含める
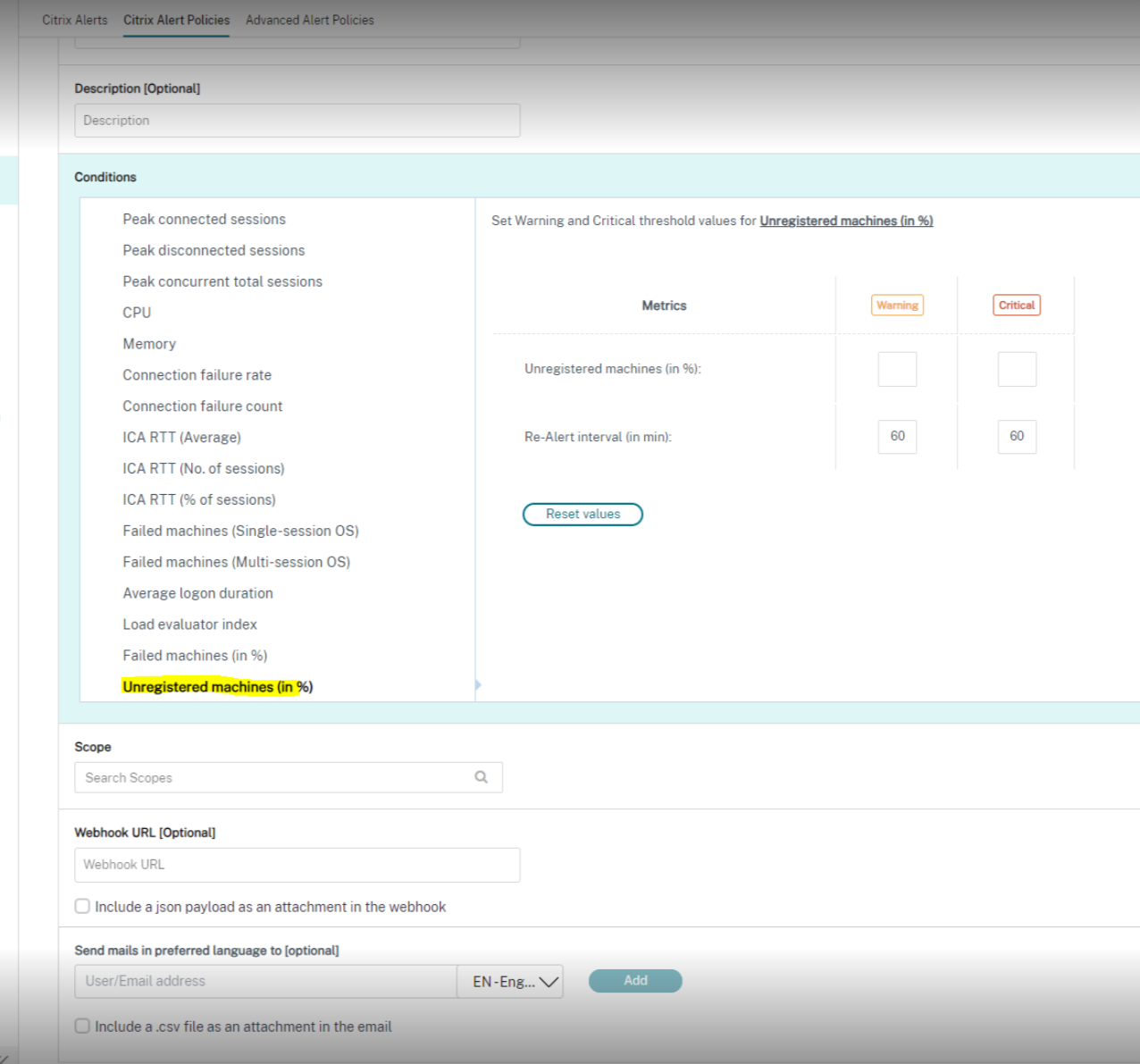
以下は、Citrixアラートポリシーセクションのスクリーンショットです。
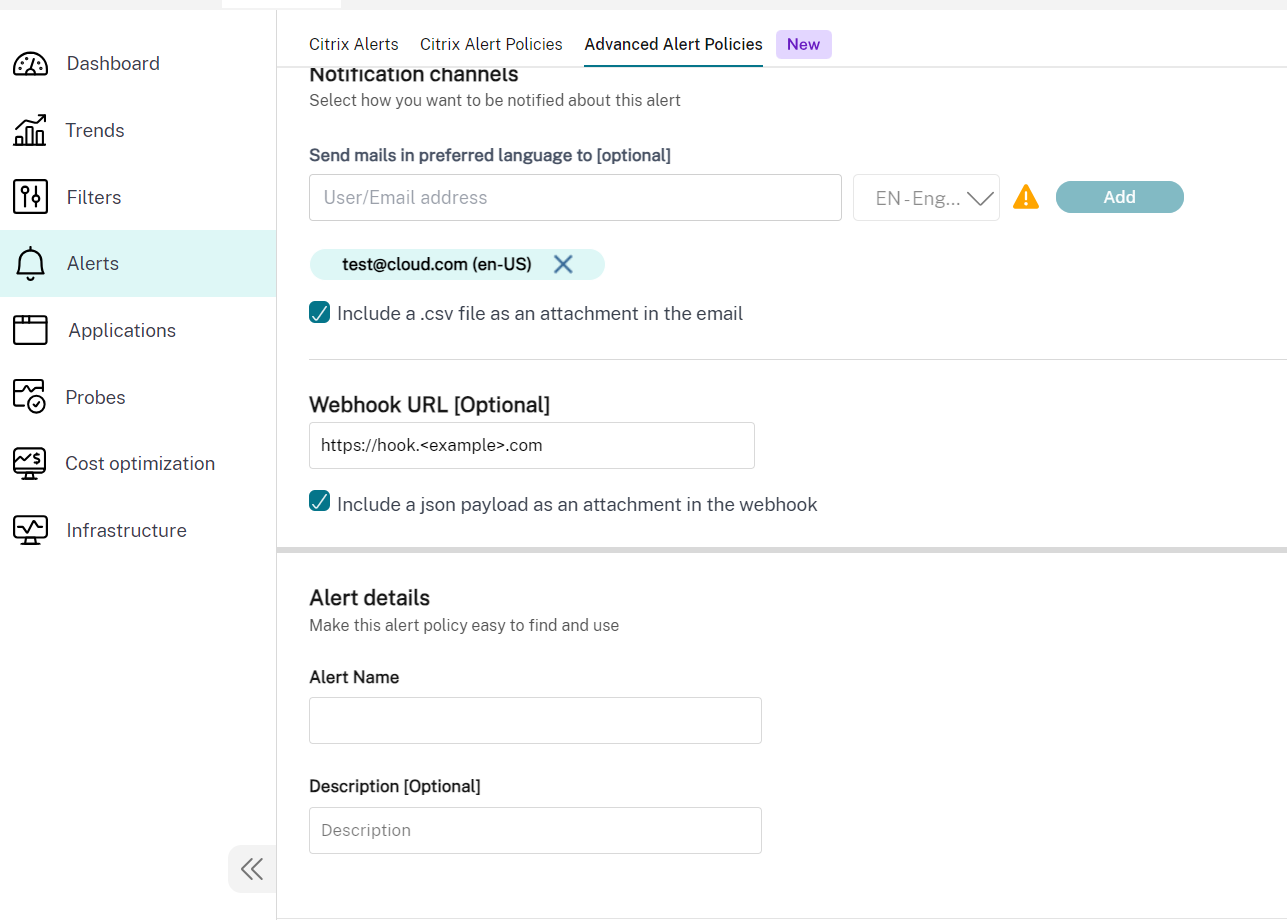
- 以下は、**高度なアラートポリシー**セクションのスクリーンショットです。
CSV添付ファイル
- 次の表は、サポートされているすべてのアラートの.CSV添付ファイルの列を示しています。
| 列 | 適用されるアラート |
|---|---|
| マシン名、IPアドレス、およびデリバリーグループ名 | マシンの稼働時間、電源オフアクションの失敗、電源オンアクションの失敗、および未登録マシン (%) |
| 現在の登録状態、失敗日、障害状態、およびライフサイクル状態 | 未登録マシン (%) |
| 最終電源アクション失敗理由、最終電源アクショントリガー元、最終電源アクションタイプ、および最終電源アクション完了日 | 電源オフアクションの失敗および電源オンアクションの失敗 |
- |電源状態、電源オン日、および合計稼働時間(分)|マシンの稼働時間|
{
"text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Unregistered machines (in %)\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"CurrentRegistrationState\":\"Unregistered\",\"FailureDate\":\"<Date of Failure>\",\"FaultState\":\"<Fault State of the Machine>\",\"LifecycleState\":\"<Lifecycle state of the Machine>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"CurrentRegistrationState\":\"Unregistered\",\"FailureDate\":\"<Date of Failure>\",\"FaultState\":\"<Fault State of the Machine>\",\"LifecycleState\":\"<Lifecycle state of the Machine>\"}]}"
}
<!--NeedCopy-->
電源オンアクション失敗アラート
{
"text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Failure To PowerOn Action\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure, HypervisorRateLimitExceeded, UnknownError, Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User, Administrator, Auto-Scale, Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure, HypervisorRateLimitExceeded, UnknownError, Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User, Administrator, Auto-Scale, Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"}]}"
- }
<!--NeedCopy-->
電源オフアクション失敗アラート
{
"text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Failure To PowerOff Action\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IPV4 Address of the Machine>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure,HypervisorRateLimitExceeded,UnknownError,Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User,Administrator,Auto-Scale,Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IPV4 Address of the Machine>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure,HypervisorRateLimitExceeded,UnknownError,Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User,Administrator,Auto-Scale,Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"}]}"
- }
<!--NeedCopy-->
- ##### マシンの稼働時間アラート
{
"text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Machine Uptime Alert\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"PowerState\":\"<On/Off>\",\"PoweredOnDate\":\"2024-05-15T15:04:27.723\",\"TotalUptimeInMinutes\":180},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"PowerState\":\"<ON/OFF>\",\"PoweredOnDate\":\"2024-05-15T15:04:27.723\",\"TotalUptimeInMinutes\":\"<Uptime Duration>\"}]}"
- }
<!--NeedCopy-->
アラートポリシーの条件
以下に、アラートカテゴリ、アラートを軽減するための推奨されるアクション、および定義されている場合は組み込みのポリシー条件を示します。組み込みのアラートポリシーは、アラートおよび再アラートの間隔が60分に設定されています。
ピーク時の接続セッション
- Directorのセッショントレンドビューでピーク時の接続セッションを確認
- セッション負荷に対応する十分な容量があることを確認
- 必要に応じて新しいマシンを追加
ピーク時の切断セッション
- Directorのセッショントレンドビューでピーク時の切断セッションを確認
- セッション負荷に対応する十分な容量があることを確認
- 必要に応じて新しいマシンを追加
- 必要に応じて切断されたセッションをログオフ
ピーク時の同時合計セッション
- Directorのセッショントレンドビューでピーク時の同時セッションを確認
- セッション負荷に対応する十分な容量があることを確認
- 必要に応じて新しいマシンを追加
- 必要に応じて切断されたセッションをログオフ
CPU
CPU使用率の割合は、プロセスを含むVDA全体のCPU消費量を示します。個々のプロセスによるCPU使用率の詳細については、対応するVDAのマシン詳細ページから確認できます。
- マシン詳細 > 履歴使用率の表示 > 上位10プロセスに移動し、CPUを消費しているプロセスを特定します。プロセスレベルのリソース使用統計の収集を開始するには、プロセス監視ポリシーが有効になっていることを確認してください。
- 必要に応じてプロセスを終了
- プロセスを終了すると、保存されていないデータが失われます。
- すべてが期待どおりに機能している場合は、将来的に追加のCPUリソースを追加します。
注:
リソース監視を有効にするポリシー設定は、VDAがインストールされたマシンでのCPUおよびメモリのパフォーマンスカウンタの監視に対して、デフォルトで許可されています。このポリシー設定が無効になっている場合、CPUおよびメモリ条件のアラートはトリガーされません。詳細については、「監視ポリシー設定」を参照してください。
スマートポリシー条件:
- スコープ: デリバリーグループ、マルチセッションOSスコープ
- しきい値: 警告 - 80%、クリティカル - 90%
メモリ
メモリ使用率の割合は、プロセスを含むVDA全体のメモリ消費量を示します。個々のプロセスによるメモリ使用量の詳細については、対応するVDAのマシン詳細ページから確認できます。
- **マシン詳細 > 履歴使用率の表示 > 上位10プロセス**に移動し、メモリを消費しているプロセスを特定します。プロセスレベルのリソース使用統計の収集を開始するには、プロセス監視ポリシーが有効になっていることを確認してください。
- 必要に応じてプロセスを終了
- プロセスを終了すると、保存されていないデータが失われます。
-
すべてが期待どおりに機能している場合は、将来的に追加のメモリを追加します。
注:
リソース監視を有効にするポリシー設定は、VDAがインストールされたマシンでのCPUおよびメモリのパフォーマンスカウンタの監視に対して、デフォルトで許可されています。このポリシー設定が無効になっている場合、CPUおよびメモリ条件のアラートはトリガーされません。詳細については、「監視ポリシー設定」を参照してください。
スマートポリシー条件:
- スコープ: デリバリーグループ、マルチセッションOSスコープ
- しきい値: 警告 - 80%、クリティカル - 90%
接続失敗率
過去1時間における接続失敗の割合。
- 試行された合計接続数に対する合計失敗数に基づいて計算
- Directorの接続失敗トレンドビューで、構成ログから記録されたイベントを確認
- アプリケーションまたはデスクトップに到達可能かどうかを判断
接続失敗数
過去1時間における接続失敗の数。
- Directorの接続失敗トレンドビューで、構成ログから記録されたイベントを確認
- アプリケーションまたはデスクトップに到達可能かどうかを判断
ICA® RTT (平均)
平均ICAラウンドトリップタイム。
- ICA RTTの内訳についてCitrix ADMを確認し、根本原因を特定します。詳細については、Citrix ADMのドキュメントを参照してください。
- Citrix ADMが利用できない場合は、Directorのユーザー詳細ビューでICA RTTと遅延を確認し、ネットワークの問題か、アプリケーションまたはデスクトップの問題かを判断します。
ICA RTT (セッション数)
しきい値のICAラウンドトリップタイムを超えるセッションの数。
- 高いICA RTTを持つセッション数についてCitrix ADMを確認します。詳細については、Citrix ADMのドキュメントを参照してください。
-
Citrix ADMが利用できない場合は、ネットワークチームと協力して根本原因を特定します。
スマートポリシー条件:
- スコープ: デリバリーグループ、マルチセッションOSスコープ
- しきい値: 警告 - 5セッション以上で300ミリ秒、クリティカル - 10セッション以上で400ミリ秒
ICA RTT (セッションの割合)
平均ICAラウンドトリップタイムを超えるセッションの割合。
- 高いICA RTTを持つセッション数についてCitrix ADMを確認します。詳細については、Citrix ADMのドキュメントを参照してください。
- Citrix ADMが利用できない場合は、ネットワークチームと協力して根本原因を特定します。
ICA RTT (ユーザー)
指定されたユーザーによって起動されたセッションに適用されるICAラウンドトリップタイム。ICA RTTが少なくとも1つのセッションでしきい値を超えると、アラートがトリガーされます。
失敗したマシン (シングルセッション OS)
失敗したシングルセッション OS マシンの数。失敗は、Director のダッシュボードおよびフィルタービューに示されているように、さまざまな理由で発生する可能性があります。
-
Citrix Scout 診断を実行して、根本原因を特定
スマートポリシーの条件:
- スコープ: デリバリーグループ、マルチセッション OS スコープ
- しきい値: 警告 - 1、重大 - 2
失敗したマシン (マルチセッション OS)
失敗したマルチセッション OS マシンの数。失敗は、Director のダッシュボードおよびフィルタービューに示されているように、さまざまな理由で発生する可能性があります。
-
Citrix Scout 診断を実行して、根本原因を特定
スマートポリシーの条件:
- スコープ: デリバリーグループ、マルチセッション OS スコープ
- しきい値: 警告 - 1、重大 - 2
-
失敗したマシン (割合)
デリバリーグループ内の失敗したシングルセッションおよびマルチセッション OS マシンの割合。失敗したマシンの数に基づいて計算されます。このアラート条件を使用すると、デリバリーグループ内の失敗したマシンの割合としてアラートしきい値を構成でき、30 秒ごとに計算されます。 失敗は、Director のダッシュボードおよびフィルタービューに示されているように、さまざまな理由で発生する可能性があります。Citrix Scout 診断を実行して、根本原因を特定します。詳しくは、「ユーザーの問題のトラブルシューティング」を参照してください。
電源オンアクションの失敗と電源オフアクションの失敗
デリバリーグループ内の電源オンアクションの失敗数と電源オフアクションの失敗数。電源オンまたは電源オフに失敗した電源管理対象マシンの数に基づいて計算されます。このアラート条件を使用すると、デリバリーグループ内で電源オンまたは電源オフに失敗した電源管理対象マシンの数としてアラートしきい値を構成でき、30 分ごとに計算されます。
管理者は、詳細アラートポリシーでこれらのアラートに対して次のパラメーターを構成できます。
- トリガー元: 電源アクションをトリガーしたもの
- 失敗の理由: アクションが失敗した理由
- しきい値: ポリシーをトリガーするために電源アクションに失敗したマシンのしきい値
- サンプリング間隔: 失敗した電源アクションを確認する間隔
- 再アラート間隔: アラートを再送信するまでの時間
失敗は、Director のダッシュボードおよびフィルタービューに示されているように、さまざまな理由で発生する可能性があります。Citrix Scout 診断を実行して、根本原因を特定します。詳しくは、「ユーザーの問題のトラブルシューティング」を参照してください。
未登録のマシン (割合)
マシンが再起動によって不安定になった場合、またはデリバリーコントローラーと仮想マシンとの間に通信の問題がある場合、マシンは未登録と見なされます。未登録のマシン (割合) は、デリバリーグループ内の未登録のシングルセッションおよびマルチセッション OS マシンの割合であり、未登録のマシンの数に基づいて計算されます。このアラート条件を使用すると、デリバリーグループ内の未登録のマシンの割合として警告および重大なしきい値を構成できます。再アラートの間隔を設定できます。また、未登録のマシン (割合) の条件が満たされたときに通知を受け取るためにメールを追加することもできます。重大または警告のしきい値を超えると、アラートとメールが生成されます。アラートは [Citrix Alerts] で表示できます。[Unregistered Machines (in %)] カテゴリで、必要な状態と時間でフィルターできます。
メールがある場合は CSV 添付ファイルで、Webhook がある場合は JSON ペイロードでアラートの詳細を受け取ることもできます。
注:
重大値は警告値よりも大きくする必要があります。
ポリシーの条件:
- スコープ: シングルセッション OS およびマルチセッション OS デリバリーグループ
- しきい値: 警告および重大
マシンの稼働時間アラート
デリバリーグループ内のマシンの稼働時間は、デリバリーグループ内でマシンがオンになっている 1 日あたりの時間数、1 週間あたりの時間数、または 1 か月あたりの時間数に基づいて計算されます。このアラート条件を使用すると、デリバリーグループ内でマシンがオンになっている時間数としてアラートしきい値を構成できます。マシンの稼働時間アラートは、次の場合に機能します。
- 1 日あたりの時間数 - マシンが 1 日にオンになっている時間数を指定でき、30 分ごとに計算されます。設定できる 1 日あたりの最大時間数は 24 時間です。
- 1 週間あたりの時間数 - マシンが 1 週間にオンになっている時間数を指定でき、6 時間ごとに計算されます。設定できる 1 週間あたりの最大時間数は 168 時間です。
- 1 か月あたりの時間数 - マシンが 1 か月にオンになっている時間数を指定でき、1 日に 1 回計算されます。1 か月あたりの最大時間数は 720 時間です。 設定できる再アラート間隔の最小値は 60 分です。警告および重大アラートセクションで、マシンの稼働時間しきい値を超えたマシンの数を入力できます。任意のマシンに対して例外を追加することもできます。
たとえば、このアラートに 5 つのデリバリーグループが追加されており、最初のデリバリーグループと 4 番目のデリバリーグループでマシンの数が警告または重大なしきい値を超えた場合、アラートは最初のデリバリーグループと 4 番目のデリバリーグループで個別にトリガーされます。
このアラートは、管理者がマシンの稼働時間を分析するのに役立ち、この分析に基づいて管理者はコストの最適化に役立てることができます。メールがある場合は CSV 添付ファイルで、Webhook がある場合は JSON ペイロードでアラートの詳細を受け取ることもできます。
平均ログオン時間
過去 1 時間に発生したログオンの平均ログオン時間。
- Director ダッシュボードをチェックして、ログオン時間に関する最新のメトリックを取得します。短期間に多くのユーザーがログオンすると、ログオン時間が増加する可能性があります。
-
ログオンのベースラインと内訳をチェックして、原因を絞り込みます。詳しくは、「ユーザーログオンの問題の診断」を参照してください。
スマートポリシーの条件:
- スコープ: デリバリーグループ、マルチセッション OS スコープ
- しきい値: 警告 - 45 秒、重大 - 60 秒
ログオン時間 (ユーザー)
過去 1 時間に発生した指定されたユーザーのログオンのログオン時間。
ロードエバリュエーターインデックス
過去 5 分間のロードエバリュエーターインデックスの値。
-
Director でピーク負荷 (最大負荷) が発生している可能性のあるマルチセッション OS マシンをチェックします。ダッシュボード (失敗) とトレンドのロードエバリュエーターインデックスレポートの両方を表示します。
スマートポリシーの条件:
- スコープ: デリバリーグループ、マルチセッション OS スコープ
- しきい値: 警告 - 80%、重大 - 90%
Webhookによるアラートポリシーの設定
メール通知とは別に、Webhookを使用してアラートポリシーを設定できます。
注: この機能には、Delivery Controllerバージョン7.11以降が必要です。
PowerShellコマンドレットを使用して、HTTPコールバックまたはHTTP POSTでアラートポリシーを設定できます。これらはWebhookをサポートするように拡張されています。
新しいOctobluワークフローの作成と、対応するWebhook URLの取得については、Octoblu Developer Hubを参照してください。
新しいアラートポリシーまたは既存のポリシーにWebhook URLを設定するには、次のPowerShellコマンドレットを使用します。
Webhook URLを使用して新しいアラートポリシーを作成します。
$policy = New-MonitorNotificationPolicy -Name <Policy name> -Description <Policy description> -Enabled $true -Webhook <Webhook URL>
<!--NeedCopy-->
既存のアラートポリシーにWebhook URLを追加します。
Set-MonitorNotificationPolicy - Uid <Policy id> -Webhook <Webhook URL>
<!--NeedCopy-->
PowerShellコマンドのヘルプについては、PowerShellヘルプを使用してください。例:
Get-Help <Set-MonitorNotificationPolicy>
<!--NeedCopy-->
アラートポリシーから生成された通知は、Webhook URLへのPOST呼び出しでWebhookをトリガーします。POSTメッセージには、JSON形式の通知情報が含まれます。
{"NotificationId" : \<Notification Id\>,
"Target" : \<Notification Target Id\>,
"Condition" : \<Condition that was violated\>,
"Value" : \<Threshold value for the Condition\>,
"Timestamp": \<Time in UTC when notification was generated\>,
"PolicyName": \<Name of the Alert policy\>,
"Description": \<Description of the Alert policy\>,
"Scope" : \<Scope of the Alert policy\>,
"NotificationState": \<Notification state critical, warning, healthy or dismissed\>,
"Site" : \<Site name\>}
<!--NeedCopy-->
アラートの一括解除
この機能は、管理者のアラート管理プロセスを最適化し、柔軟性を提供し、アラート疲労を軽減します。管理者は、時間、種類、またはカテゴリに基づいてアラートを一括解除できるため、メンテナンス中やハイパーバイザーなどの環境を扱う際のアラート管理が簡素化されます。
アラートの一括解除は、管理者がワークロードを効率的に管理し、大量のアラートに圧倒されるのを防ぐのに役立ちます。
アラートを一括解除する手順
-
アラート > Citrixアラートタブに移動します。アラートが表示されます。
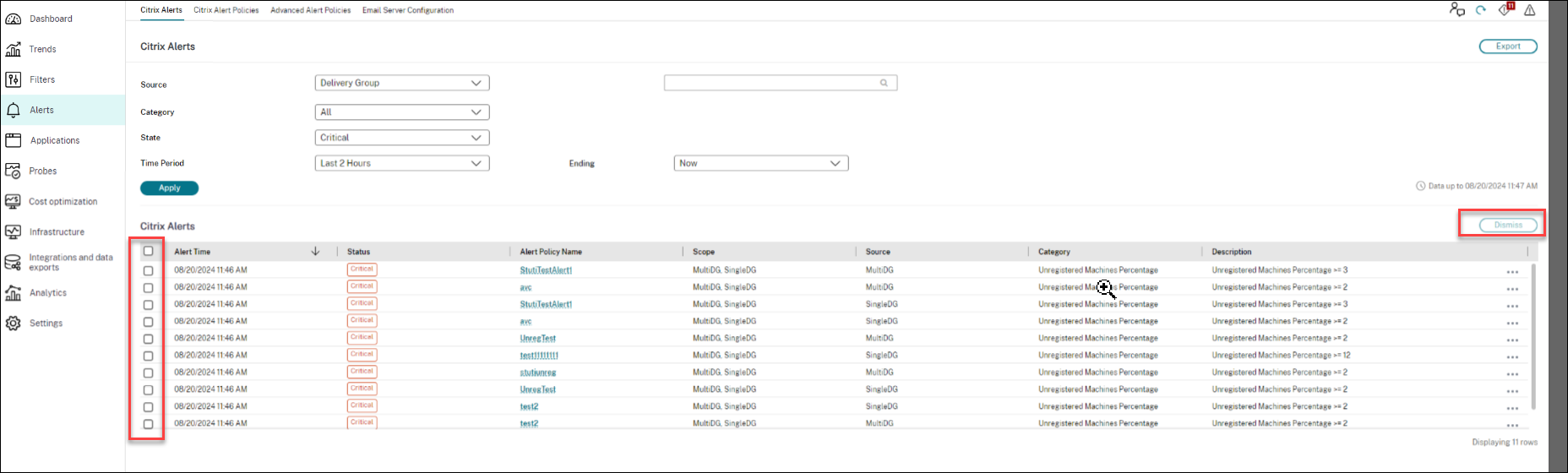
- 解除するアラートをフィルター処理するには、ソース、カテゴリ、状態、または期間からオプションを選択します。特定のアラートが表示されます。
- 特定のアラートの横にあるチェックボックス、または上部にあるチェックボックスを選択して、すべてのアラートを選択します。
- 解除をクリックします。アラートの解除を確認する通知が表示されます。
- はいをクリックします。選択したアラートは解除済みとしてマークされ、アラートのステータスがそれに応じて更新されます。
PowerShell SDKを使用したWebhook構成
PowerShell SDKを使用したWebhook構成機能により、管理者はWebhookプロファイルの作成、変更、削除、および一覧表示を行うことができます。この機能は、ヘッダー、認証タイプ、コンテンツタイプ、ペイロード、およびWebhook URLの指定を可能にすることで、Webhook構成の柔軟性を提供します。
注:
サポートされているペイロード形式はテキストであり、エンドユーザーはWebhookでテキストを有効にする必要があります。
最新のペイロード形式は次のとおりです。
{"text": "This is a message from a Webex incoming webhook."}
<!--NeedCopy-->
Webhookの作成
次のPowerShellサンプルコマンドを使用して、Webhookプロファイルを作成できます。
承認ヘッダーなしでWebhookを作成するには:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$payloads = '{ "text": "$PAYLOAD" }'
$url = "<Fill this field with the required URL>"
Add-MonitorWebhookProfile -Name "profile_slack" -Description "webhook profile for slack" -Url $url -Headers $headers -PayloadFormat $payloads
<!--NeedCopy-->
承認ヘッダー付きでWebhookを作成するには:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$headers.Add("Authorization", "Basic <Fill this field with the authorization token>")
$payloads = '{ "text": "$PAYLOAD" }'
$url = "<Fill this field with the required URL>"
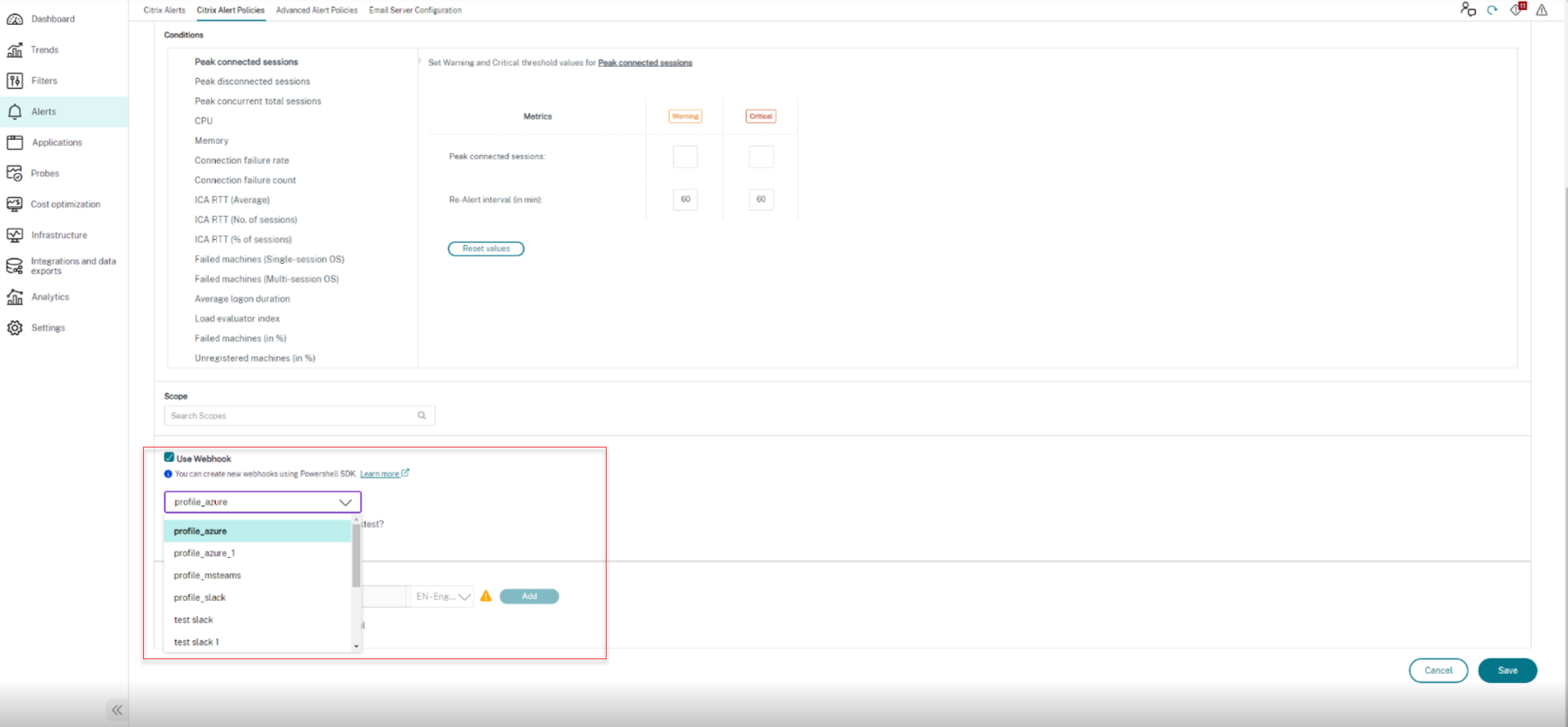
Add-MonitorWebhookProfile -Name "profile_azure" -Description "webhook profile for azure function with Authentication" -Url $url -Headers $headers -PayloadFormat $payloads
<!--NeedCopy-->
プロファイルが作成されたら、データベースで確認できます。また、新しく作成されたWebhookプロファイルは、Citrixアラートページで見つけることができます。
Webhookプロファイルの更新
次のPowerShellサンプルコマンドを使用して、Webhookプロファイルを更新できます。
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$payloads = '{ "text": "$PAYLOAD" }'
$url = "<Fill this field with the required URL>"
Set-MonitorWebhookProfile -Uid 1 -Name "profile_slack_citrix" -Description "webhook profile for citrix slack" -Url $url -Headers $headers -PayloadFormat $payloads
<!--NeedCopy-->
すべてのWebhookプロファイルの一覧取得
次のPowerShellサンプルコマンドを使用して、利用可能なすべてのWebhookプロファイルの一覧を取得できます。
Get-MonitorWebhookProfile
Get-MonitorWebhookProfile -Name 'profile_msteams'
Get-MonitorWebhookProfile -Uid 1
<!--NeedCopy-->
ウェブフックプロファイルの削除
次のサンプルPowerShellコマンドを使用して、ウェブフックプロファイルを削除できます。
Remove-MonitorWebhookProfile -Uid 1
<!--NeedCopy-->
注:
ウェブフックプロファイルがいずれかのポリシーにマッピングされている場合、削除できません。回避策として、まずポリシーからウェブフックマッピングを削除する必要があります。
ウェブフックプロファイルを使用したポリシーの作成
次のサンプルPowerShellコマンドを使用して、ウェブフックプロファイルを含むポリシーを作成できます。
New-MonitorNotificationPolicy -Name "Policy1" -Description "Policy Description" -Enabled $true -WebhookProfileId 1
<!--NeedCopy-->
ウェブフックプロファイルを使用したポリシーの更新
次のサンプルPowerShellコマンドを使用して、ウェブフックプロファイルを含むポリシーを更新できます。
$Policy = Set-MonitorNotificationPolicy -Uid 1 -WebhookProfileId 1
<!--NeedCopy-->
ポリシーからのウェブフックマッピングの削除
次のサンプルPowerShellコマンドを使用して、ポリシーからウェブフックプロファイルを削除できます。
$Policy = Set-MonitorNotificationPolicy -Uid 1 -WebhookProfileId 0
<!--NeedCopy-->
ウェブフックプロファイルのテスト
次のサンプルPowerShellコマンドを使用して、ウェブフックプロファイルをテストできます。
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$headers.Add("Authorization", "Basic <Fill this with authorization token>")
$payloads = '{ "text": "$PAYLOAD" }'
$url ="<Fill this field with the required URL>"
Test-MonitorWebhookProfile -Url $url -Headers $headers -PayloadFormat $payloads
<!--NeedCopy-->
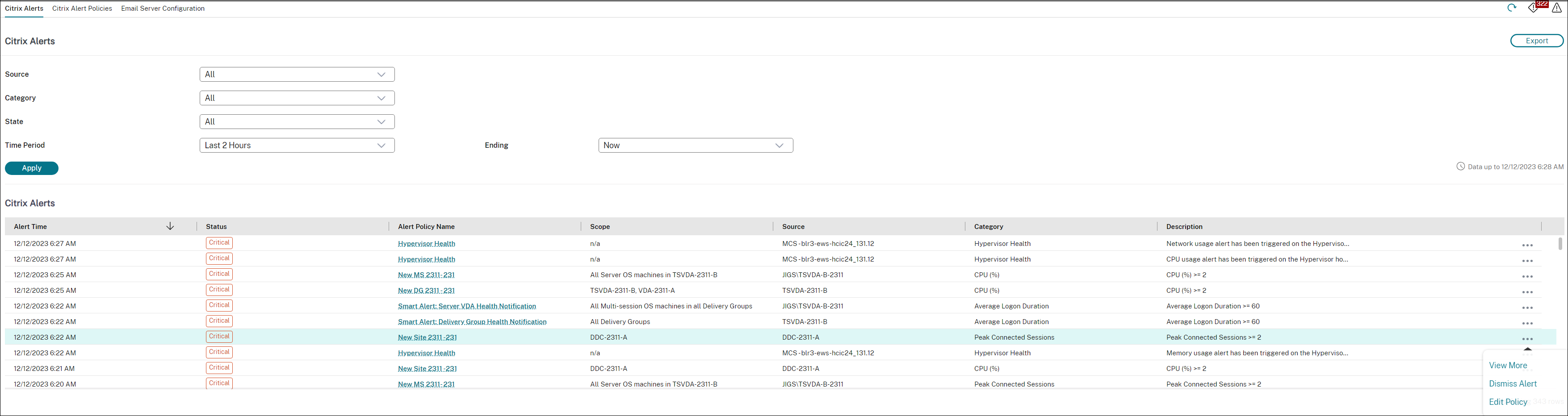
ハイパーバイザーアラートの監視
Directorは、ハイパーバイザーの健全性を監視するためのアラートを表示します。XenServer®およびVMware vSphereからのアラートは、ハイパーバイザーのパラメーターと状態の監視に役立ちます。ハイパーバイザーへの接続ステータスも監視され、ホストのクラスターまたはプールが再起動されたり利用できなくなったりした場合にアラートが提供されます。
ハイパーバイザーアラートを受信するには、Web Studioでホスティング接続が作成されていることを確認してください。詳しくは、「接続とリソース」を参照してください。これらの接続のみがハイパーバイザーアラートについて監視されます。
これらのアラートは、しきい値に達するか、それを超えた場合に表示されます。ハイパーバイザーアラートには次の種類があります。
- 重大—ハイパーバイザーアラームポリシーの重大なしきい値に達したか、それを超えた場合
- 警告—ハイパーバイザーアラームポリシーの警告しきい値に達したか、それを超えた場合
- 却下済み—アクティブなアラートとして表示されなくなったアラート
この機能には、Delivery Controllerバージョン7 1811以降が必要です。Directorの古いバージョンをサイト7 1811以降で使用している場合、ハイパーバイザーアラートの数のみが表示されます。アラートを表示するには、Directorをアップグレードする必要があります。
次の表は、ハイパーバイザーアラートのさまざまなパラメーターと状態について説明しています。
| アラート | サポートされているハイパーバイザー | トリガー元 | 条件 | 構成 |
|---|---|---|---|---|
| CPU使用率 | XenServer、VMware vSphere | ハイパーバイザー | CPU使用率アラートのしきい値に達したか、それを超えた場合 | アラートのしきい値はハイパーバイザーで構成する必要があります |
| メモリ使用率 | XenServer、VMware vSphere | ハイパーバイザー | メモリ使用率アラートのしきい値に達したか、それを超えた場合 | アラートのしきい値はハイパーバイザーで構成する必要があります |
| ネットワーク使用率 | XenServer、VMware vSphere | ハイパーバイザー | ネットワーク使用率アラートのしきい値に達したか、それを超えた場合 | アラートのしきい値はハイパーバイザーで構成する必要があります |
| ディスク使用率 | VMware vSphere | ハイパーバイザー | ディスク使用率アラートのしきい値に達したか、それを超えた場合 | アラートのしきい値はハイパーバイザーで構成する必要があります |
| ホスト接続または電源状態 | VMware vSphere | ハイパーバイザー | ハイパーバイザーホストが再起動されたか、利用できない場合 | アラートはVMware vSphereに組み込まれています。追加の構成は不要です |
| ハイパーバイザー接続が利用不可 | XenServer、VMware vSphere | Delivery Controller | ハイパーバイザー(プールまたはクラスター)への接続が失われたか、電源がオフになったか、再起動された場合。このアラートは、接続が利用できない限り1時間ごとに生成されます | アラートはDelivery Controllerに組み込まれています。追加の構成は不要です |
注:
アラートの構成について詳しくは、「Citrix XenCenter Alerts」を参照するか、VMware vCenter Alertsのドキュメントを確認してください。
メール通知の設定は、Citrix Alerts Policy > Site Policy > Hypervisor Healthで構成できます。ハイパーバイザーアラートポリシーのしきい値条件は、Directorからではなく、ハイパーバイザーからのみ構成、編集、無効化、または削除できます。ただし、メール設定の変更とアラートの却下はDirectorで行うことができます。役割にインフラストラクチャの監視が含まれていない場合は、アラートを無効にできます。
重要:
- ハイパーバイザーによってトリガーされたアラートは、Directorで取得および表示されます。ただし、ハイパーバイザーアラートのライフサイクル/状態の変更はDirectorには反映されません。
- ハイパーバイザーコンソールで正常または却下済み、無効になっているアラートはDirectorに引き続き表示され、明示的に却下する必要があります。
- Directorで却下されたアラートは、ハイパーバイザーコンソールでは自動的に却下されません。
垂直および水平負荷分散アラートの処理の改善
以前は、UseVerticalScalingForRdsLaunchesをtrueに設定し、Studioで「最大セッション数」ポリシーを構成すると、マシンは「最大容量」状態に移行していました。Directorは、垂直負荷分散または水平負荷分散のいずれかによって制限に達した場合でも、「最大容量」のアラートをトリガーしていました。「最大負荷に到達」などの特定のエラーが発生した場合、垂直負荷分散と水平負荷分散を区別する方法はありませんでした。これにより、垂直スケーリングシナリオで予期される動作に対して不要なアラートが発生し、時間と混乱を招いていました。
現在、垂直負荷分散がアクティブで、マシンがセッション制限に達すると、「垂直スケーリングの最大容量」という新しい状態に移行します。Directorは、この新しい状態に対してアラートを生成しなくなりました。アラートは、水平スケーリングシナリオでの「最大容量」に対してのみトリガーされます。フィルターページとカスタムレポートページで新しい状態を表示できるため、予期される条件と例外的な条件を簡単に区別できます。この機能強化により、不要なアラートを回避し、実際の問題に集中できるため、監視とトラブルシューティングが効率化されます。これは、Set-BrokerSiteを使用してUseVerticalScalingForRdsLaunchesを構成し、Studioで「最大セッション数」ポリシーを設定した場合に適用されます。