Architecture Splunk avec l’application complémentaire Citrix Analytics
Splunk suit une architecture qui contient les trois niveaux suivants :
- Collecte
- Indexation
- Recherche
Splunk prend en charge un large éventail de mécanismes de collecte de données qui facilitent l’ingestion de données dans Splunk, de sorte qu’elles puissent être indexées et rendues disponibles pour la recherche. Ce niveau n’est autre que votre heavy forwarder ou universal forwarder.
Vous devez installer l’application complémentaire sur la couche du heavy forwarder plutôt que sur la couche de l’universal forwarder. En effet, à quelques exceptions près pour les données bien structurées (telles que json, csv, tsv), l’universal forwarder ne parse pas les sources de journaux en événements, il ne peut donc effectuer aucune action nécessitant une compréhension du format des journaux.
Il est également livré avec une version allégée de Python, ce qui le rend incompatible avec toute application d’entrée modulaire nécessitant une pile Splunk complète pour fonctionner. Le heavy forwarder n’est autre que votre niveau de collecte.
La principale différence entre un universal forwarder et un heavy forwarder est que le heavy forwarder contient la pipeline d’analyse complète, exécutant les fonctions identiques à celles d’un indexeur sans réellement écrire et indexer les événements sur le disque. Cela permet au heavy forwarder de comprendre et d’agir sur des événements individuels tels que le masquage de données, le filtrage et le routage basés sur les données d’événement. Étant donné que l’application complémentaire dispose d’une installation Splunk Enterprise complète, elle peut héberger des entrées modulaires qui nécessitent une pile Python complète pour une collecte de données appropriée, ou agir comme un point de terminaison pour le Splunk HTTP Event Collector (HEC).
Une fois les données collectées, elles sont indexées ou traitées et stockées de manière à les rendre consultables.
La principale façon pour les clients d’explorer leurs données est la recherche. Une recherche peut être enregistrée en tant que rapport et utilisée pour alimenter les panneaux de tableau de bord. Les recherches permettent d’extraire des informations de vos données.
En général, l’application complémentaire Splunk est déployée au niveau de la couche de collecte (au niveau Splunk Enterprise), tandis que notre application de tableau de bord est déployée au niveau de la couche de recherche (au niveau Splunk Cloud). Dans une configuration sur site simple, vous pouvez avoir ces trois niveaux sur un seul hôte Splunk (appelé déploiement sur un seul serveur).
Le niveau de collecte est une bien meilleure façon d’utiliser l’application complémentaire pour Splunk. Il existe deux façons d’installer l’application complémentaire. Soit vous pouvez l’installer au niveau de la couche de collecte dans l’environnement client, soit vous pouvez l’installer au niveau du gestionnaire de données d’entrée (Inputs Data Manager) dans l’instance Splunk Cloud.
Reportez-vous au diagramme suivant pour comprendre l’architecture de déploiement Splunk avec notre application complémentaire :
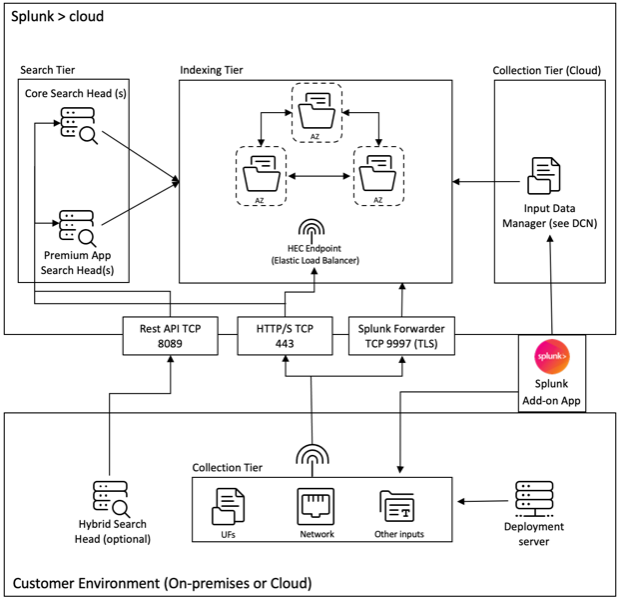
L’Inputs Data Manager (IDM) présenté dans le diagramme susmentionné est l’implémentation gérée par Splunk Cloud d’un nœud de collecte de données (Data Collection Node - DCN) qui prend en charge uniquement les entrées scriptées et modulaires. Pour les besoins de collecte de données au-delà de cela, vous pouvez déployer et gérer un DCN dans votre environnement à l’aide d’un heavy forwarder Splunk.
Splunk permet de collecter, d’indexer et de rechercher des données provenant de diverses sources. Une façon de collecter des données est via des API, ce qui permet à Splunk d’accéder aux données stockées dans d’autres systèmes ou applications. Ces API peuvent inclure REST, les services web, JMS et/ou JDBC comme mécanisme de requête. Splunk et tout développeur tiers proposent une gamme d’applications qui permettent des interactions API via le cadre d’entrée modulaire de Splunk. Ces applications nécessitent généralement une installation complète du logiciel Splunk Enterprise pour fonctionner correctement.
Pour faciliter la collecte de données via des API, il est courant de déployer un heavy forwarder en tant que DCN. Les heavy forwarders sont des agents plus puissants que les universal forwarders, car ils contiennent la pipeline d’analyse complète et peuvent comprendre et agir sur des événements individuels. Cela leur permet de collecter des données via des API et de les traiter avant de les transmettre à une instance Splunk pour indexation.
Pour en savoir plus sur l’architecture de haut niveau d’un déploiement Splunk Cloud, consultez les Architectures validées Splunk.