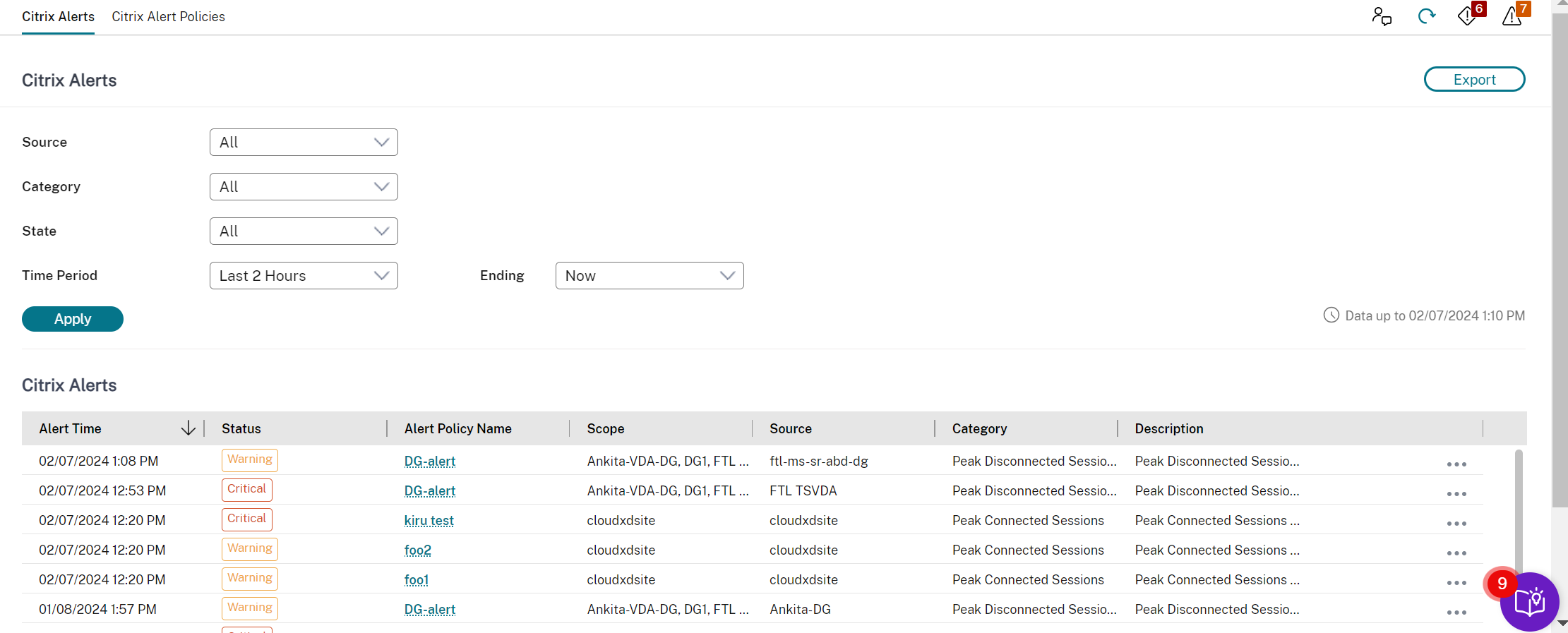
Alertas y notificaciones
Las alertas se muestran en Monitor en el panel de control y en otras vistas de alto nivel con símbolos de alerta de advertencia y críticos. Las alertas se actualizan automáticamente cada minuto; también puedes actualizar las alertas bajo demanda.
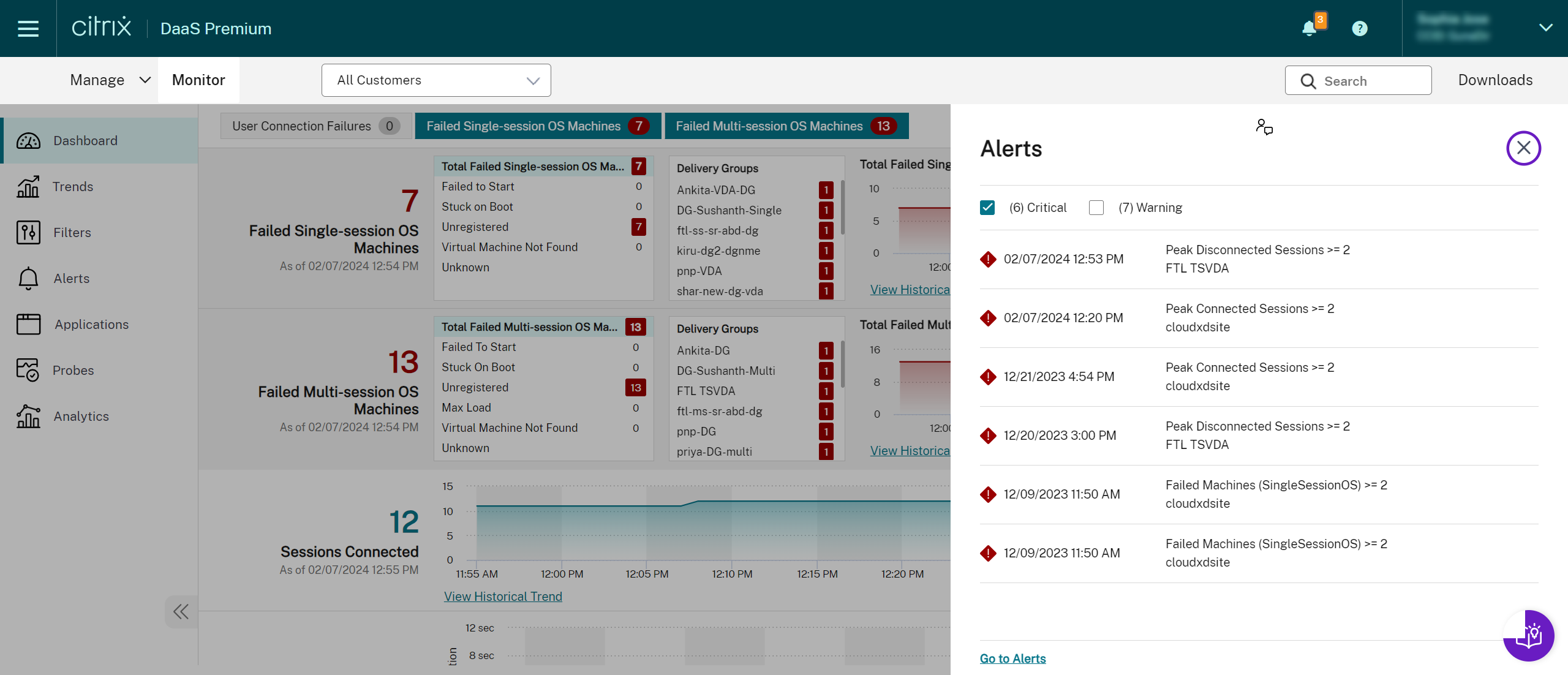
Una alerta de advertencia (triángulo ámbar) indica que se ha alcanzado o superado el umbral de advertencia de una condición.
Una alerta crítica (círculo rojo) muestra que se ha alcanzado o superado el umbral crítico de una condición.
Puedes ver información más detallada sobre las alertas seleccionando una alerta de la barra lateral, haciendo clic en el enlace Ir a alertas en la parte inferior de la barra lateral o seleccionando Alertas en la parte superior de la página Monitor.
En la vista Alertas, puedes filtrar y exportar alertas. Por ejemplo, máquinas de SO multisesión fallidas para un grupo de entrega específico durante el último mes, o todas las alertas para un usuario específico. Para obtener más información, consulta Exportar informes.
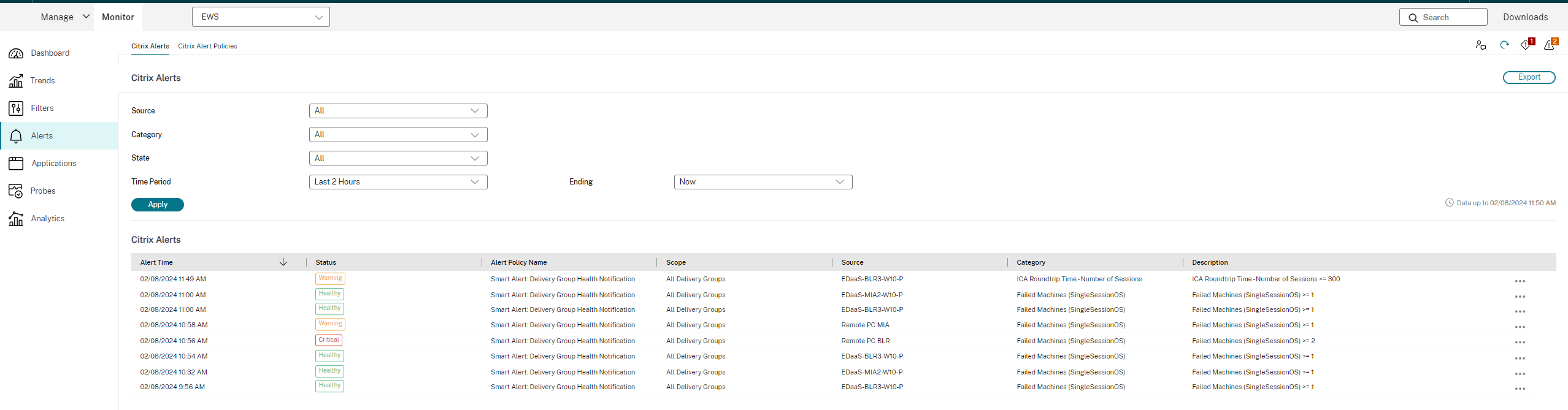
Alertas de Citrix®
Las alertas de Citrix son las que se originan en los componentes de Citrix. Puedes configurar las alertas de Citrix en Monitor en Alertas > Directiva de alertas de Citrix. Como parte de la configuración, puedes establecer que se envíen notificaciones por correo electrónico a personas y grupos cuando las alertas superen los umbrales que has configurado. Para obtener más información sobre cómo configurar las alertas de Citrix, consulta Crear directivas de alertas.
Directivas de alertas inteligentes
- Hay disponible un conjunto de directivas de alertas integradas con valores de umbral predefinidos para grupos de entrega y el ámbito de los VDA de SO multisesión. Puedes modificar los parámetros de umbral de las directivas de alertas integradas en Alertas > Directiva de alertas de Citrix.
- Estas directivas se crean cuando hay al menos un destino de alerta (un grupo de entrega o un VDA de SO multisesión) definido en tu sitio. Además, estas alertas integradas se agregan automáticamente a un nuevo grupo de entrega o a un VDA de SO multisesión.
Las directivas de alertas integradas se crean solo si no existen reglas de alerta correspondientes en la base de datos de Monitor.
Para conocer los valores de umbral de las directivas de alertas integradas, consulta la sección Condiciones de las directivas de alertas.
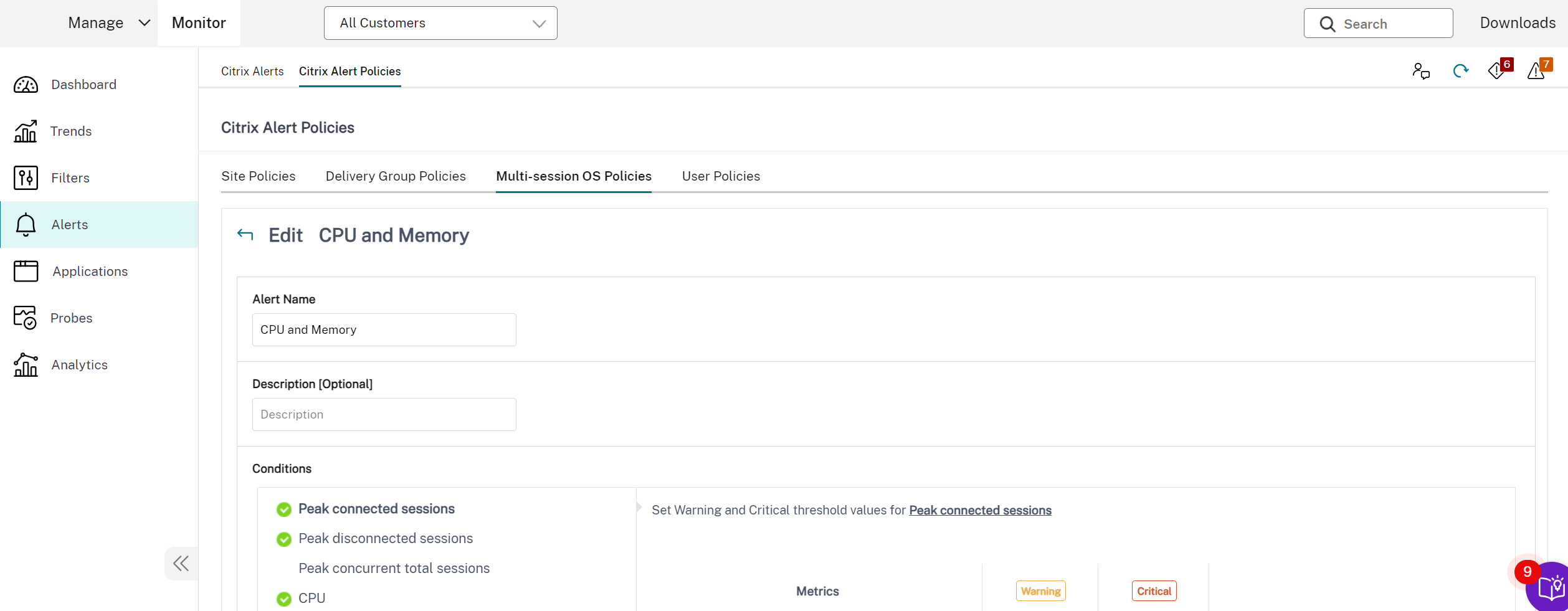
Directivas de alertas avanzadas
- La función de notificación y alerta proactiva de Monitor se ha mejorado para incluir un nuevo marco de alertas denominado **Directivas de alertas avanzadas**. Con esta función, puedes crear alertas incluyendo detalles granulares para cada elemento o condición, lo que mejora el control sobre el ámbito de las alertas. Actualmente, estas directivas incluyen alertas para el ahorro de costes y la infraestructura.
- Con la introducción de las directivas de alertas avanzadas, que son alertas basadas en fuentes de datos, puedes usar el filtrado de ámbito de varias condiciones.
Esta función te ayuda a reducir las alertas excesivas que podrían provocar una menor capacidad de respuesta o eficacia al abordar problemas importantes. Esta directiva ayuda a medir la eficacia de las directivas de alertas y la participación de los administradores.
- Puedes crear una directiva de alertas avanzada desde la sección **Alertas** > **Directiva de alertas avanzada** > **Crear directiva**.
- Puedes seleccionar una de las siguientes fuentes de datos:
- Máquinas
- Provisioning Service
- StoreFront™
Alertas para el ahorro de costes
- Puedes crear alertas para el ahorro de costes, lo que te ayuda a optimizar los costes. Actualmente, puedes crear alertas para máquinas.
- Para crear alertas en Máquinas, haz lo siguiente:
- Haz clic en la ficha Alertas > Directivas de alertas avanzadas. Aparece la página Directivas de alertas avanzadas.
- Haz clic en Crear directiva. Aparece la sección Crear directivas de alertas avanzadas.
- Selecciona Máquinas en la lista desplegable Fuente de datos. Se muestran la condición de ahorro de costes y los tipos de condición correspondientes.
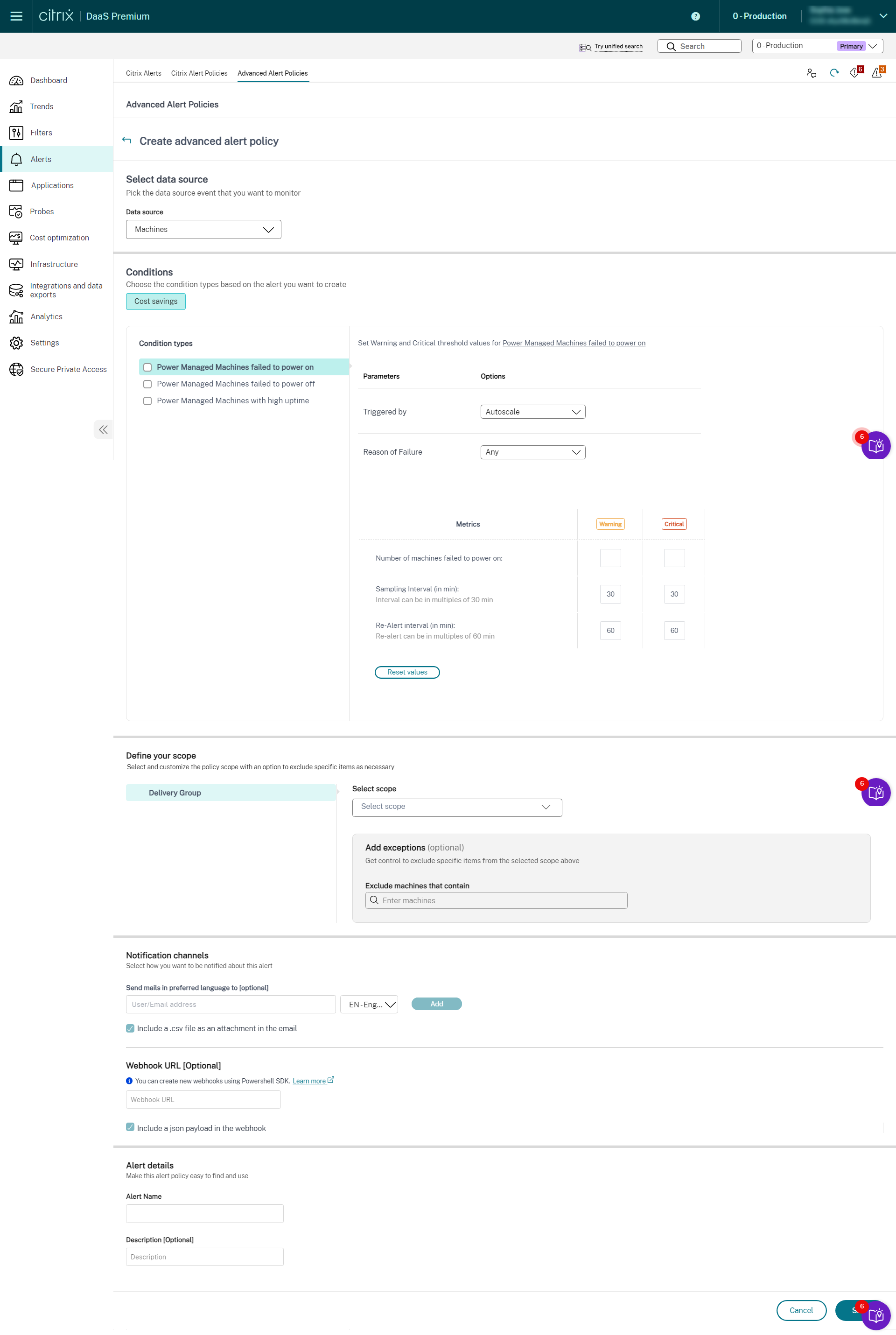
-
Selecciona los siguientes tipos de condición según sea necesario:
- **Máquinas administradas por energía que no se pudieron encender** - **Máquinas administradas por energía que no se pudieron apagar** - **Máquinas administradas por energía con alto tiempo de actividad** -
Selecciona los parámetros específicos y las opciones correspondientes para cada una de las condiciones seleccionadas. - 1. Establece las métricas de advertencia y críticas para el tipo de condición seleccionado:
- Para **Máquinas administradas por energía con alto tiempo de actividad**: - Número de máquinas que superan el umbral de tiempo de actividad - Intervalo de nueva alerta (en min); el intervalo puede ser de un mínimo de 60 min-
Para Máquinas administradas por energía que no se pudieron encender y Máquinas administradas por energía que no se pudieron apagar:
- Número de máquinas que superan el umbral de tiempo de actividad
- Intervalo de muestreo (en min); los intervalos pueden ser múltiplos de 30 min
-
Intervalo de nueva alerta (en min); la nueva alerta puede ser múltiplos de 60 min
-
- Programa los intervalos de nueva alerta para las alertas seleccionadas según sea necesario.
-
- Define el ámbito de la alerta.
-
Establece los canales de notificación. Puede ser correo electrónico o Webhook.
-
Puedes seleccionar las siguientes casillas de verificación:
- Incluir una carga JSON como archivo adjunto en el webhook
- Incluir un archivo CSV como archivo adjunto en el correo electrónico
-
- Introduce los Detalles de la alerta, como el Nombre de la alerta y la Descripción (opcional). - 1. Haz clic en Guardar. La alerta se crea.
Alertas para la latencia de conexión de SPA
- El marco de directivas de alertas avanzadas admite alertas proactivas para la conectividad de Secure Private Access (SPA). Usa esta directiva para detectar y actuar sobre la latencia de extremo a extremo que afecta a las conexiones de usuario de SPA.
Configura la alerta de latencia de conexión de SPA
-
Para crear alertas de latencia de conexión de SPA, haz lo siguiente:
-
- Haz clic en la ficha Alertas > Directivas de alertas avanzadas. Aparecerá la página Directivas de alertas avanzadas.
-
- Haz clic en Crear directiva. Aparecerá la sección Crear directivas de alertas avanzadas.
- Selecciona Secure Private Access en la lista desplegable Origen de datos. Se mostrará la condición de latencia de conexión de SPA.
-
Selecciona los siguientes tipos de métricas según sea necesario:
- Latencia del ISP (Cliente → CDN)
- Latencia de conexión (Cliente → PoP de la puerta de enlace)
- Latencia del ISP (Cliente → CDN)
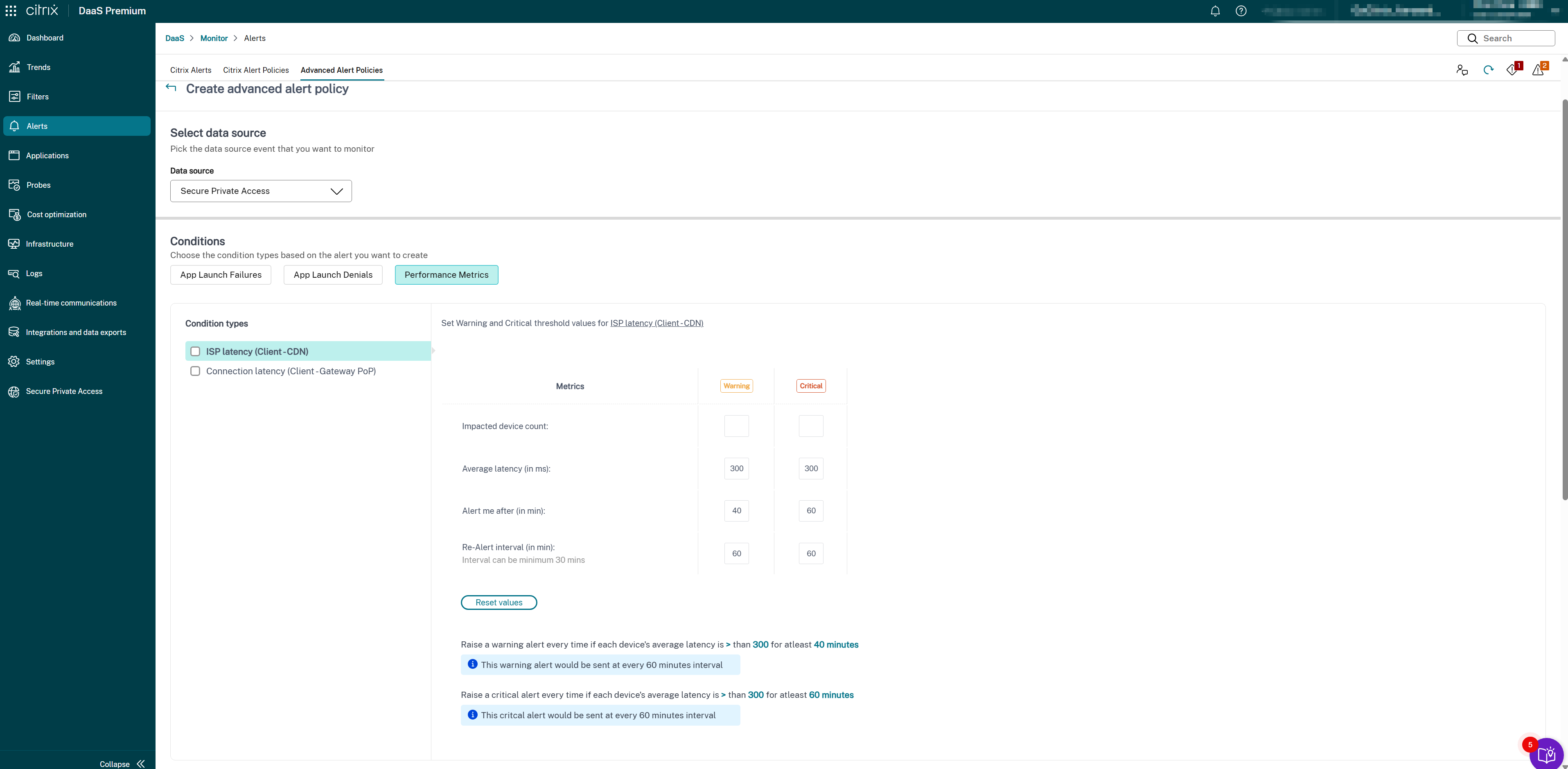
- Latencia de conexión (Cliente → PoP de la puerta de enlace)
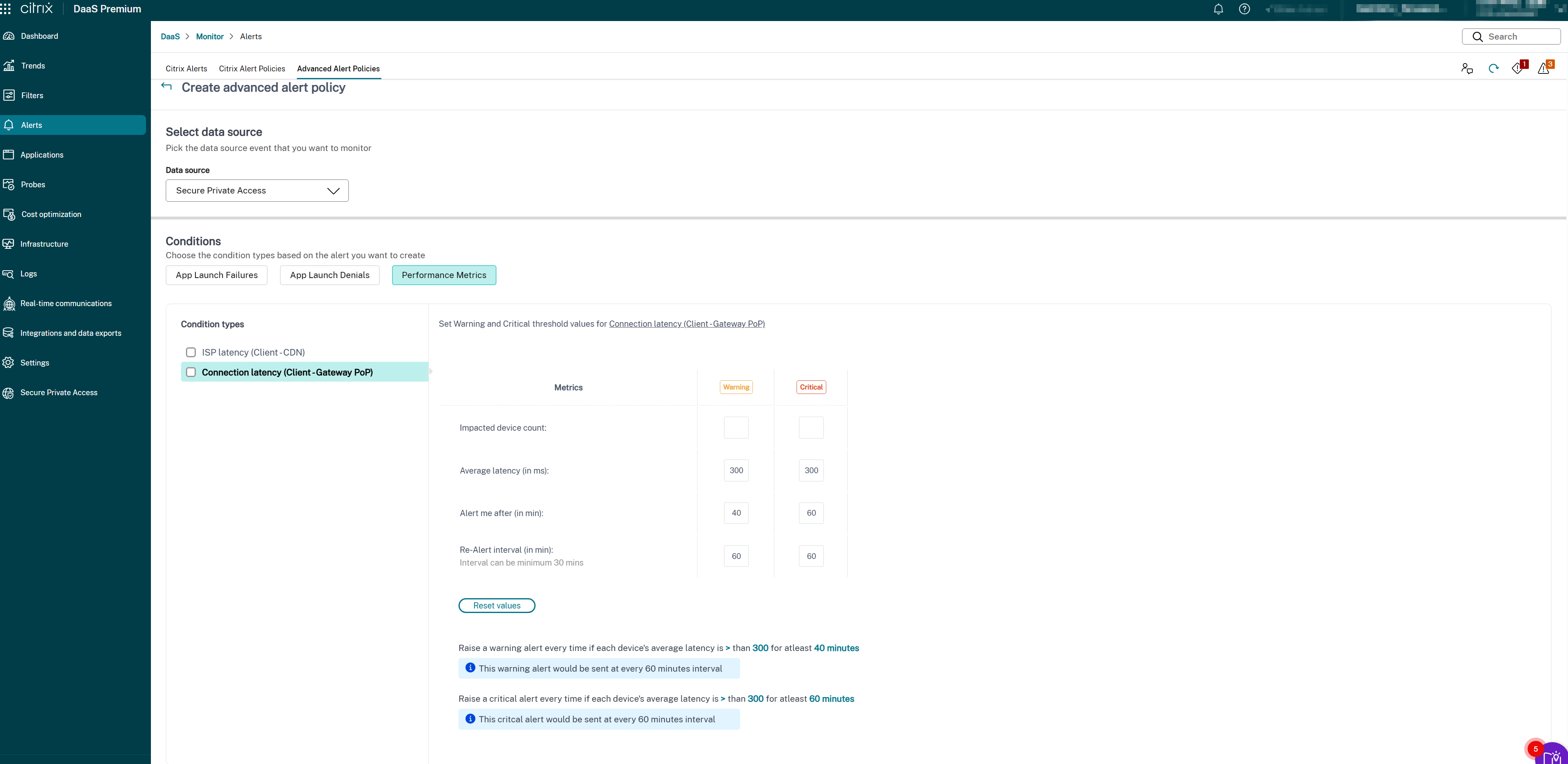
- Selecciona los parámetros específicos y las opciones correspondientes para cada una de las métricas seleccionadas.
-
Establece las métricas de advertencia y críticas para el tipo de condición seleccionado:
- Umbral de latencia (en ms): Establece los valores de advertencia (por ejemplo, 150–200 ms) y críticos (por ejemplo, 300–400 ms)
- Usuarios afectados (recuento): Número de usuarios que experimentan latencia por encima del umbral
- Intervalo de muestreo (en min): Con qué frecuencia se evalúa la latencia (por ejemplo, 5–15 minutos)
- Intervalo de nueva alerta (en min): Se recomienda un mínimo de 60 minutos para evitar la fatiga de alertas
- Programa los intervalos de nueva alerta para las alertas seleccionadas según sea necesario.
- Define el ámbito de la alerta. Selecciona el sitio, el grupo de entrega o el subconjunto de destino.
-
Establece los canales de notificación. Puede ser correo electrónico o webhook.
-
Puedes seleccionar las siguientes casillas de verificación:
- Incluir una carga JSON como archivo adjunto en el webhook
- Incluir un archivo CSV como archivo adjunto en el correo electrónico
-
- Introduce los Detalles de la alerta, como el Nombre de la alerta (por ejemplo, “Latencia de conexión de SPA – PoP Este”) y la Descripción (opcional).
- Haz clic en Guardar. La alerta se crea.
Recomendación:
Para una alerta proactiva, ajusta los umbrales de latencia en función de las mediciones de referencia por región. Incluye la integración de webhook para dirigir las alertas de alta latencia a la gestión de incidentes para un triaje más rápido.
Directivas de infraestructura
Puedes crear alertas para supervisar el estado de los siguientes componentes de Citrix DaaS™ compatibles:
- Servicio de aprovisionamiento
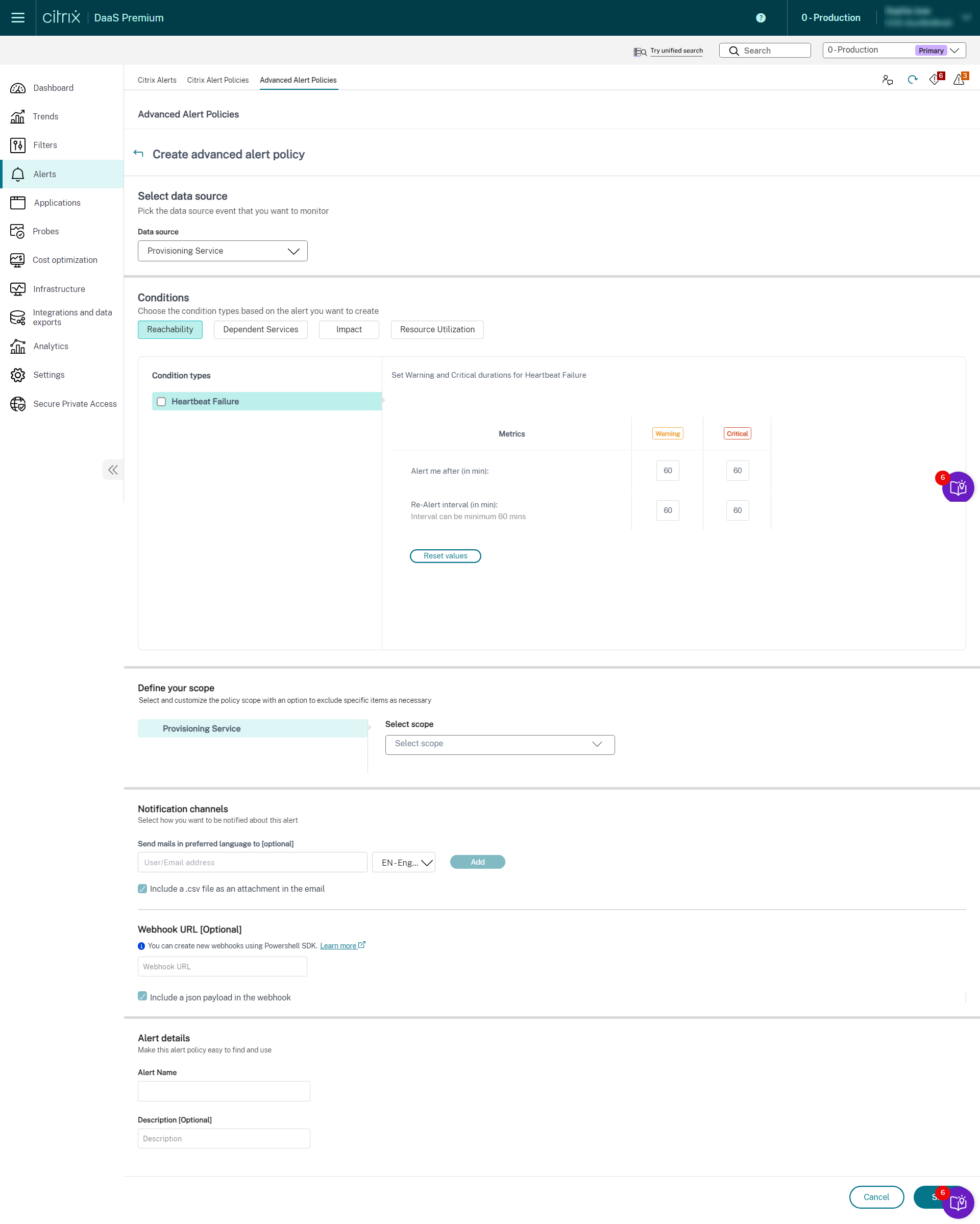
- StoreFront
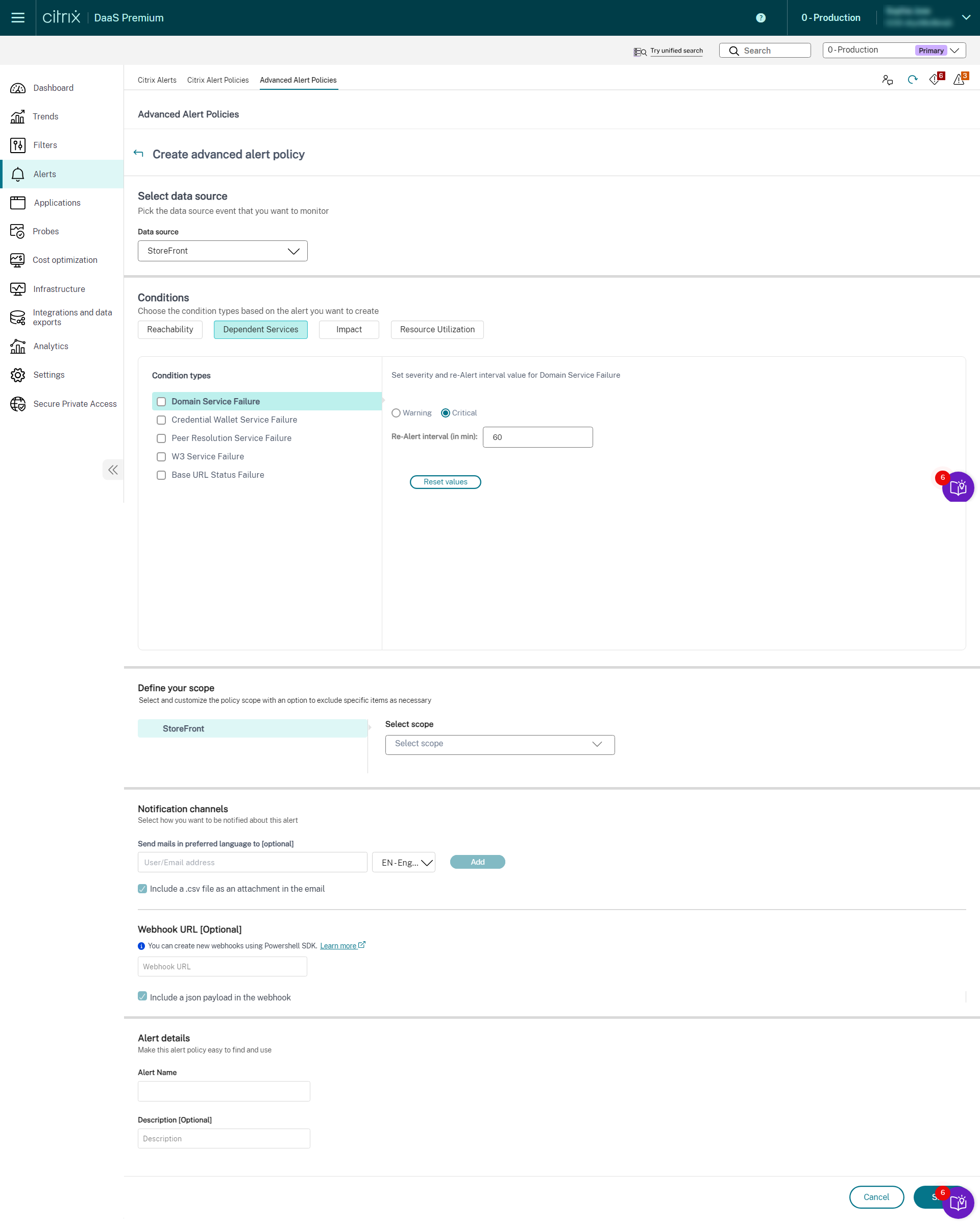
- Cloud Connector
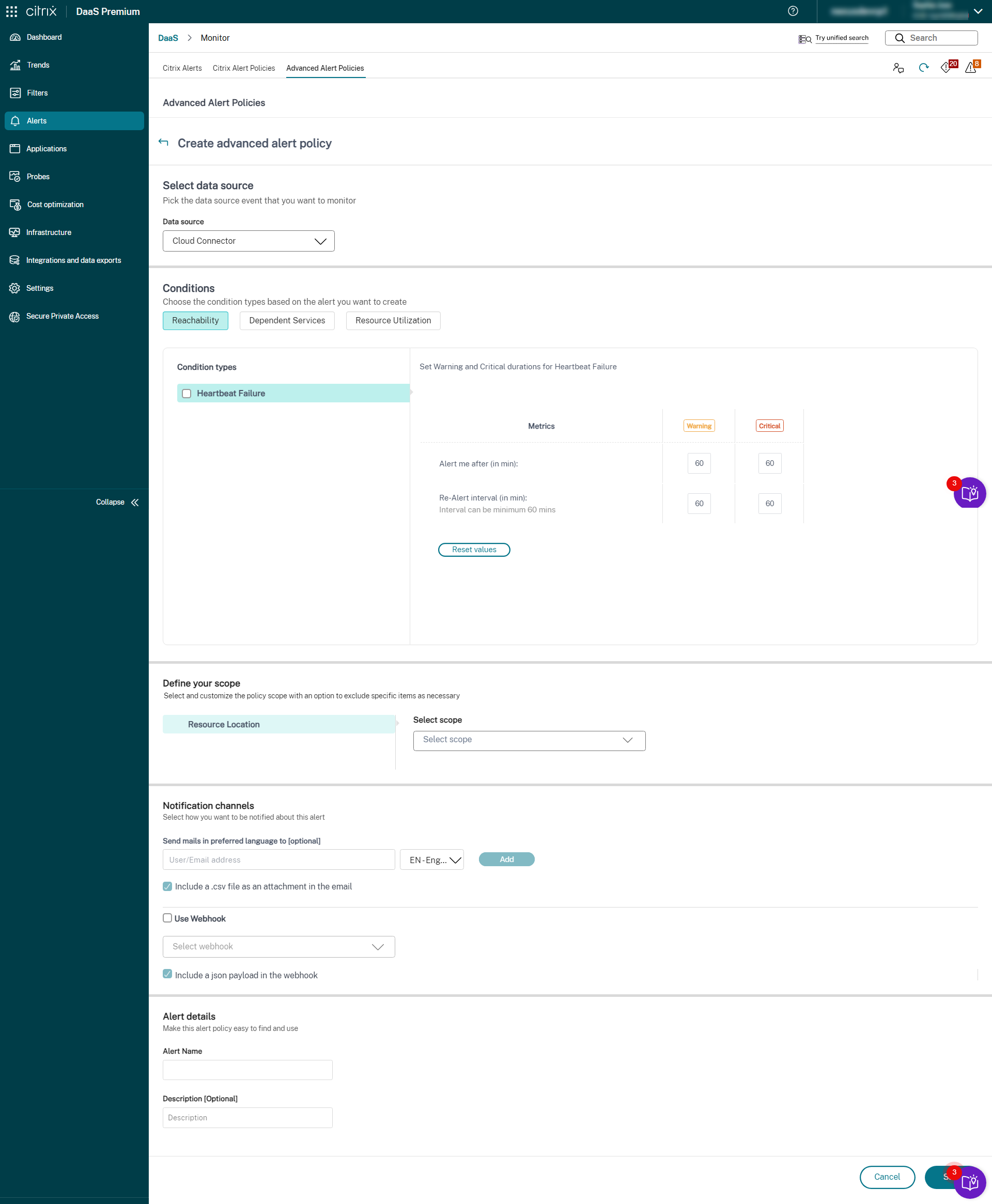
- Connector Appliance
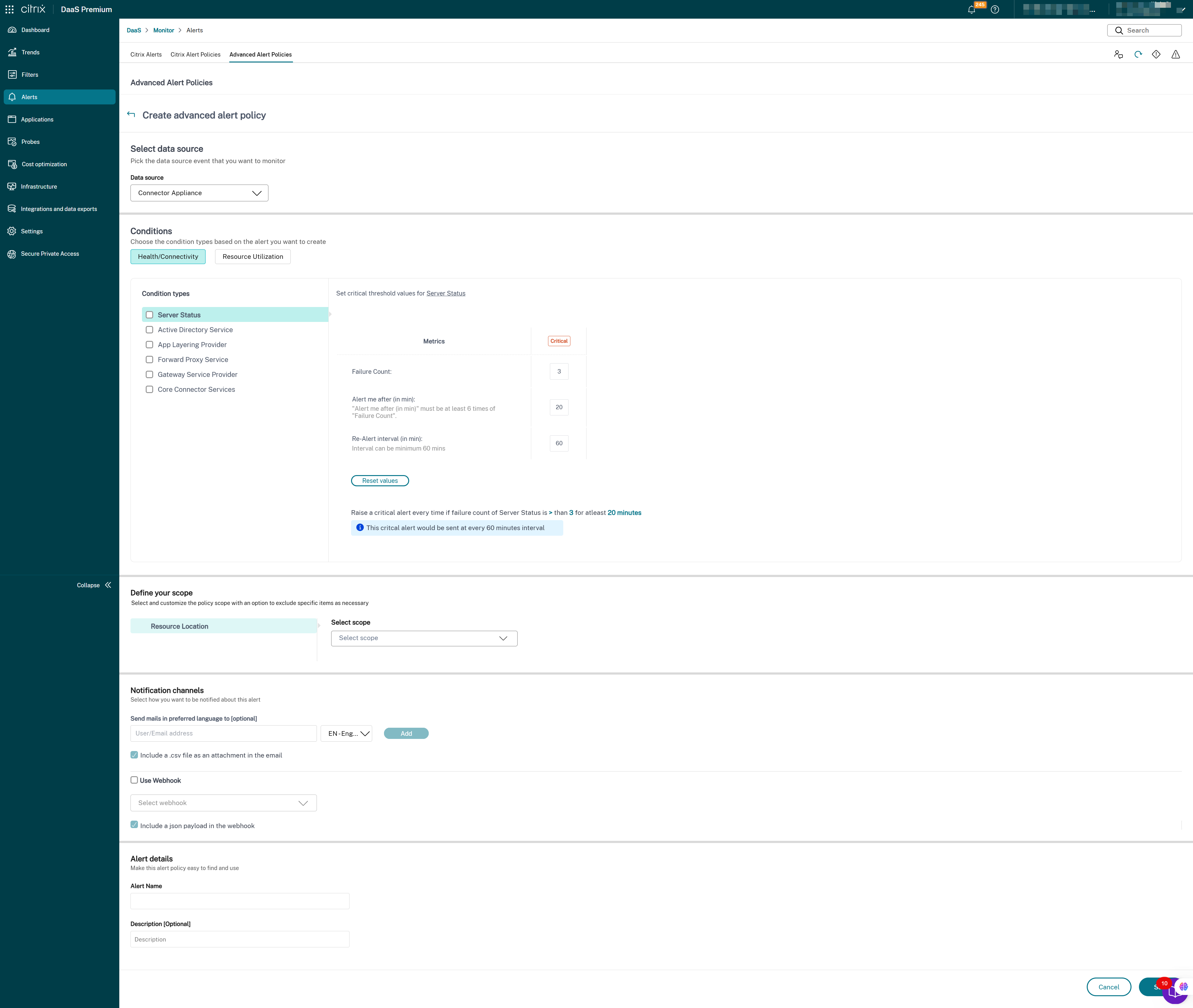
Una vez completada la configuración de la supervisión de la infraestructura, puedes usar los datos de estado disponibles en Monitor para configurar alertas para cualquier componente necesario. Los administradores pueden establecer condiciones, ámbitos y medios de notificación para recibir alertas importantes a través de correos electrónicos o una carga JSON a través de webhooks. Las alertas generadas también están disponibles en la sección Alertas de Citrix para su análisis y gestión.
Como parte de la directiva de infraestructura recién introducida, las condiciones de alerta se clasifican en cuatro secciones de la siguiente manera:
- Accesibilidad
- Servicios dependientes
- Impacto
- Utilización de recursos
Las condiciones dentro de cada categoría se pueden establecer con la gravedad de Crítica y Advertencia en función de las prioridades de tu organización. También puedes programar intervalos de nueva alerta para estas alertas.
Puedes crear una directiva de infraestructura desde la sección Alertas > Directivas de alertas de Citrix. Puedes seleccionar la categoría necesaria y, a continuación, seleccionar las condiciones necesarias para la directiva. Para obtener más información sobre cómo crear una directiva, consulta Crear directivas de alertas. Una vez creada la directiva, puedes modificarla, eliminarla o deshabilitarla en la página Alertas de Citrix.
Para obtener más detalles sobre las condiciones admitidas en cada categoría y componente, consulta lo siguiente:
- Métricas de estado de aprovisionamiento
- Métricas de estado de StoreFront
- Métricas de estado de Cloud Connector
- Métricas de estado de Connector Appliance
Los siguientes datos se reciben como una alerta por correo electrónico o en la página Alertas de Citrix:
| Campo | Descripción |
|---|---|
| ID de cliente | El ID de cliente del sitio. |
| Nivel de alerta | Los valores posibles son Crítica y Advertencia. |
| Destino | El nombre de la máquina para la que se activa la alerta. |
| Hora | La hora en que se activa la alerta. |
| Ámbito | El ámbito de la directiva. |
| Directiva | El nombre de la directiva. |
| Descripción | La descripción del problema para el que se activa la alerta. |
Define el ámbito de la directiva
Puedes definir el ámbito de tu alerta y agregar excepciones. La alerta se genera solo para el ámbito seleccionado y el subámbito excluido mediante la adición de excepciones no se incluye en la generación de alertas. Esta característica te ayuda a crear alertas a un nivel granular.
Puedes crear notificaciones a través de correos electrónicos o de URL de webhook. También puedes seleccionar tu idioma preferido en el que te gustaría recibir alertas. También puedes seleccionar una opción para recibir los parámetros de alerta en un archivo .CSV adjunto para el correo electrónico o en una carga JSON a través de una URL de webhook. El archivo adjunto incluye los detalles de los parámetros necesarios. Para obtener más información, consulta Mejoras en el contenido de las alertas.
Los siguientes datos se reciben como una alerta por correo electrónico o en la página de Alertas de Citrix:
| Campo | Descripción |
|---|---|
| ID de cliente | El ID de cliente del sitio. |
| Nivel de alerta | Este valor es el valor predefinido establecido para cada condición de alerta. Los valores posibles son Crítico y Advertencia. |
| Condición | Este valor es la condición establecida al crear la política. Por ejemplo, el número de máquinas no registradas es igual o superior a 20. |
-
Destino El nombre del grupo de entrega o sitio para el que se activa la alerta. -
Sitio El nombre del sitio. -
Ámbito El ámbito de la política. Este valor también incluye el subámbito. -
Política El nombre de la política.
| Descripción | La descripción del problema por el que se activa la alerta. |
¿Cómo crear una política de alerta avanzada mediante un script de PowerShell?
Script de PowerShell para crear una política de alerta:
asnp Citrix.Monitor.*
# Add Parameters
$timeSpan = New-TimeSpan -Seconds 30
$alertThreshold = 1
$alarmThreshold = 2
# Add Target UID's
$targetIds = @()
$targetIds += "e9a211b4-a1f3-4f74-b6c7-85225902e997"
# Add email addresses
$emailaddress = @()
$emailaddress += "loki@abc.com"
# Create new policy
$policy = New-MonitorNotificationPolicy -Name "FailedMachinePercentageAlertCreationViaPowershell" -Description "Policy created to test urm" -Enabled $true
<!--NeedCopy-->
Reemplaza la siguiente línea con la condición correcta para FailedMachinePercentage
Add-MonitorNotificationPolicyCondition -Uid $policy.Uid -ConditionType FailedMachinePercentage -AlertThreshold $alertThreshold -AlarmThreshold $alarmThreshold -AlertRenotification $timeSpan -AlarmRenotification $timeSpan
Add-MonitorNotificationPolicyTargets -Uid $policy.Uid -Scope "DG-Multisession" -TargetKind DesktopGroup -TargetIds $targetIds
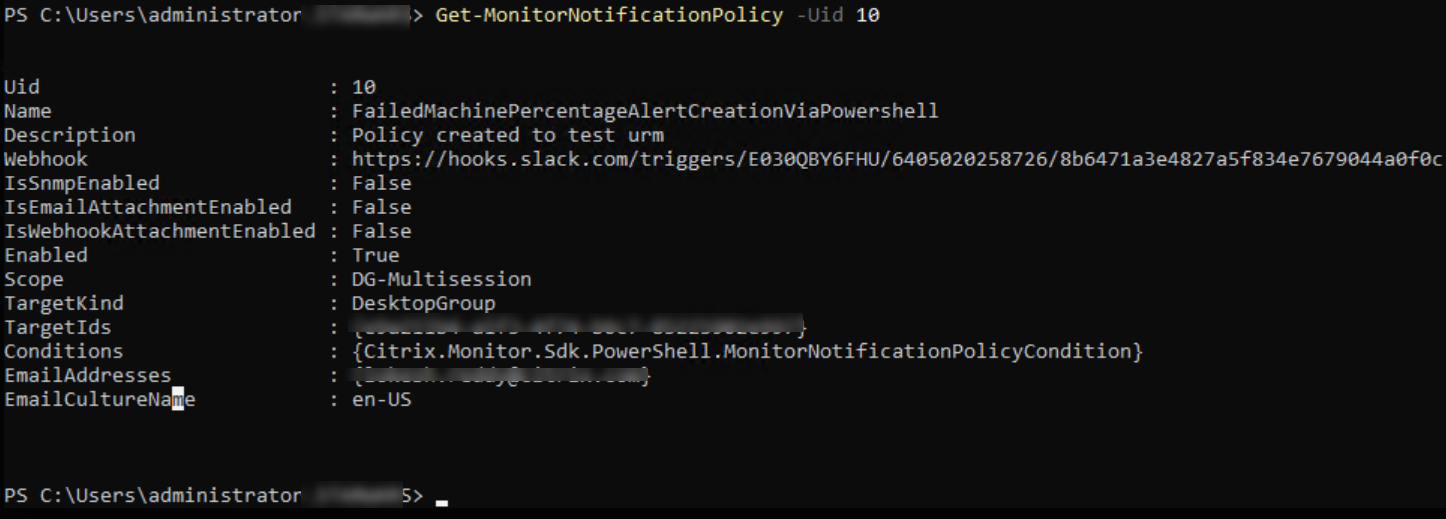
$policy = Get-MonitorNotificationPolicy -Uid $policy.Uid
$policy
<!--NeedCopy-->
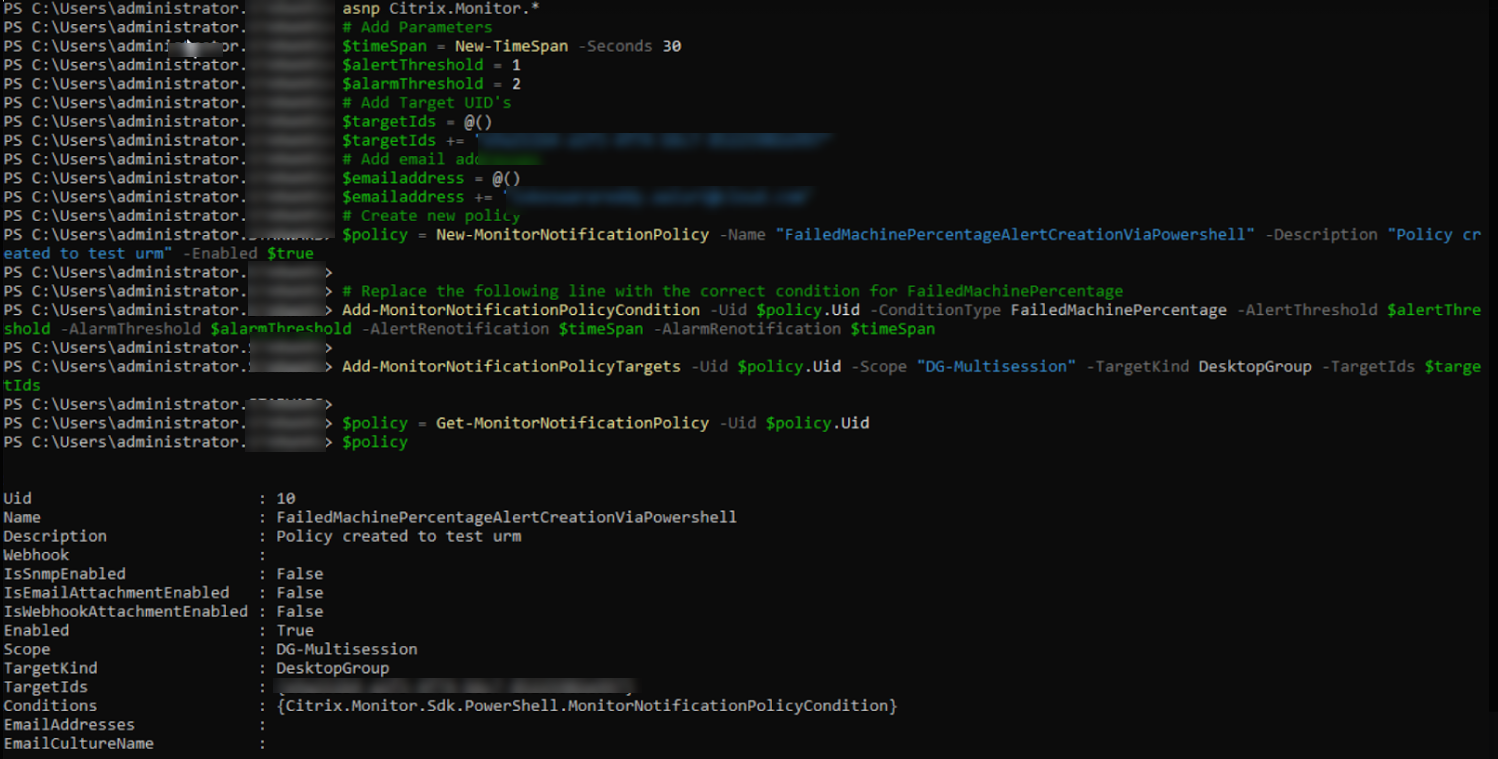
En la imagen anterior, puedes ver que la política se ha creado y que el Uid es 10.
Para agregar correo electrónico a la configuración
Set-MonitorNotificationEmailServerConfiguration -ProtocolType SMTP -ServerName NameOfTheSMTPServerOrIPAddress -PortNumber 80 -SenderEmailAddress loki@abc.com -RequiresAuthentication 0
<!--NeedCopy-->
Para agregar correo electrónico a la política
- ```
Add-MonitorNotificationPolicyEmailAddresses -Uid $policy.Uid -EmailAddresses $emailaddress -EmailCultureName “en-US”
-
```
- Script de ejemplo para agregar correo electrónico:
- Add-MonitorNotificationPolicyEmailAddresses -Uid 10 -EmailAddresses $emailaddress -EmailCultureName "en-US"
- <!--NeedCopy-->
- 
Para agregar una URL de webhook a la política
- ``` - Set-MonitorNotificationPolicy –Uid $polcy.Uid –Webhook 'URL' - <!--NeedCopy--> ```

Script de ejemplo para agregar una URL de webhook:
- ``` Set-MonitorNotificationPolicy –Uid 10 –Webhook 'https://hooks.slack.com/triggers/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'
#### Obtener detalles de la política creada
- ```
Get-MonitorNotificationPolicy -Uid 10
<!--NeedCopy-->
Crear políticas de alerta
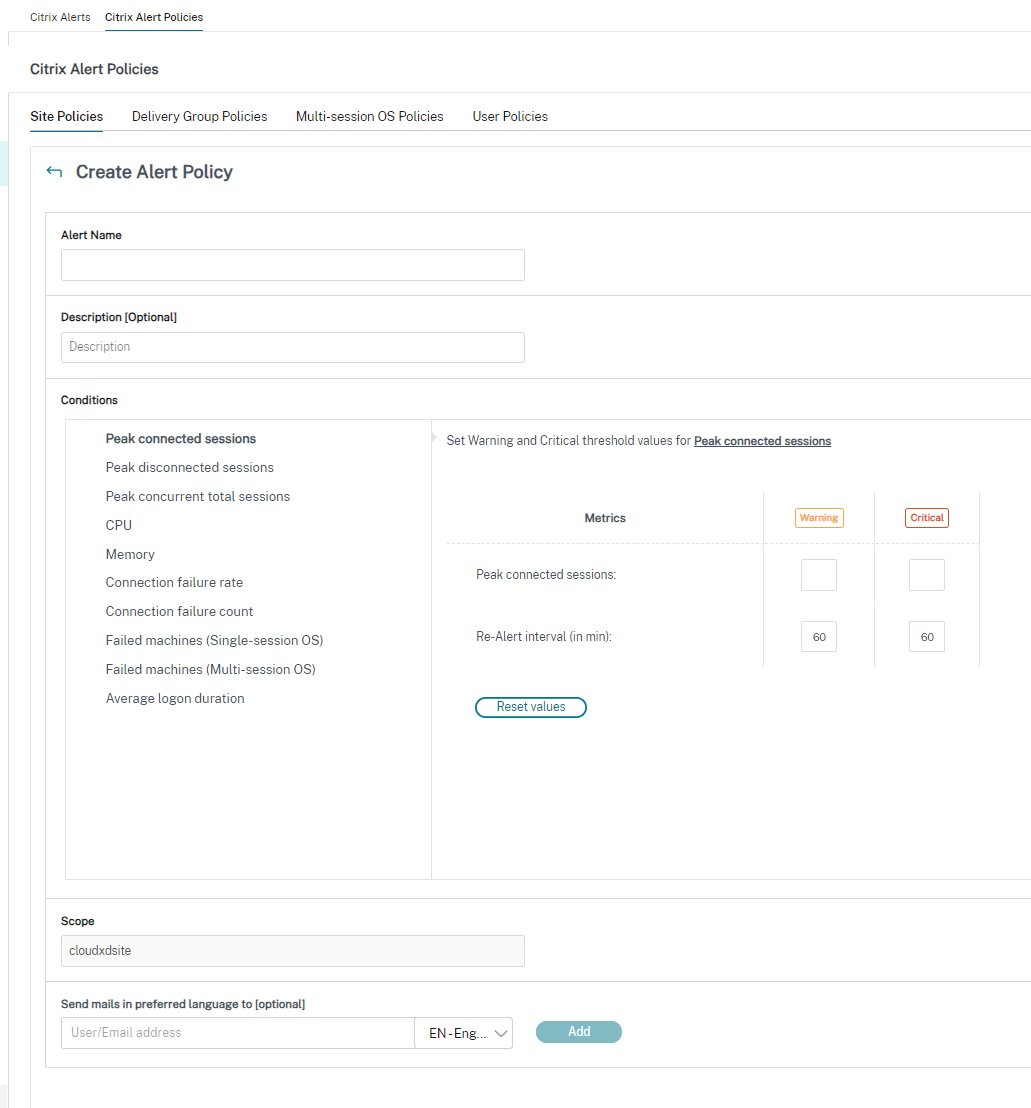
- Para crear una política de alertas, por ejemplo, para generar una alerta cuando se cumpla un conjunto específico de criterios de recuento de sesiones:
- Ve a Alertas > Política de alertas de Citrix y selecciona, por ejemplo, Política de SO multisesión.
- Haz clic en Crear.
-
- Nombra y describe la política, luego establece las condiciones que deben cumplirse para que se active la alerta. Por ejemplo, especifica los recuentos de Advertencia y Crítico para Sesiones conectadas máximas, Sesiones desconectadas máximas y Sesiones concurrentes totales máximas. Los valores de advertencia no deben ser mayores que los valores críticos. Para obtener más información, consulta Condiciones de las políticas de alerta.
-
- Establece el intervalo de nueva alerta. Si las condiciones de la alerta aún se cumplen, la alerta se activa de nuevo en este intervalo de tiempo y, si se configura en la política de alerta, se genera una notificación por correo electrónico. Una alerta descartada no genera una notificación por correo electrónico en el intervalo de nueva alerta.
-
- Establece el Ámbito. Por ejemplo, configúralo para un grupo de entrega específico.
- En las preferencias de notificación, especifica quién debe ser notificado por correo electrónico cuando se active la alerta. Las notificaciones por correo electrónico se envían a través de SendGrid. Asegúrate de que la dirección de correo electrónico
donotreplynotifications@citrix.comesté en la lista blanca de tu configuración de correo electrónico.-
- Haz clic en Guardar.
-
La creación de una política con 20 o más grupos de entrega definidos en el Ámbito puede tardar aproximadamente 30 segundos en completar la configuración. Durante este tiempo, se muestra un indicador de carga.
- La creación de más de 50 políticas para hasta 20 grupos de entrega únicos (1000 destinos de grupos de entrega en total) podría provocar un aumento en el tiempo de respuesta (más de 5 segundos).
Mover una máquina que contiene sesiones activas de un grupo de entrega a otro podría activar alertas erróneas de grupos de entrega definidas mediante parámetros de máquina.
Nota:
Después de eliminar una política de alerta, las notificaciones de alerta generadas por la política pueden tardar hasta 30 minutos en detenerse.
Mejoras en el contenido de las alertas
La función de alerta del Monitor se ha mejorado para incluir un archivo adjunto CSV y una carga útil JSON. Con esta mejora, puedes obtener los detalles de la alerta en un archivo adjunto CSV por correo electrónico o como una carga útil JSON si hay un webhook. Al usar este archivo adjunto CSV o carga útil JSON, puedes recibir contenido enriquecido a un nivel detallado, lo que ayuda a la rápida identificación y resolución de problemas.
Actualmente, esta mejora solo está disponible en las siguientes alertas:
- Tiempo de actividad de la máquina
- Acciones de encendido fallidas
- Acciones de apagado fallidas
-
Máquinas no registradas (%)
-
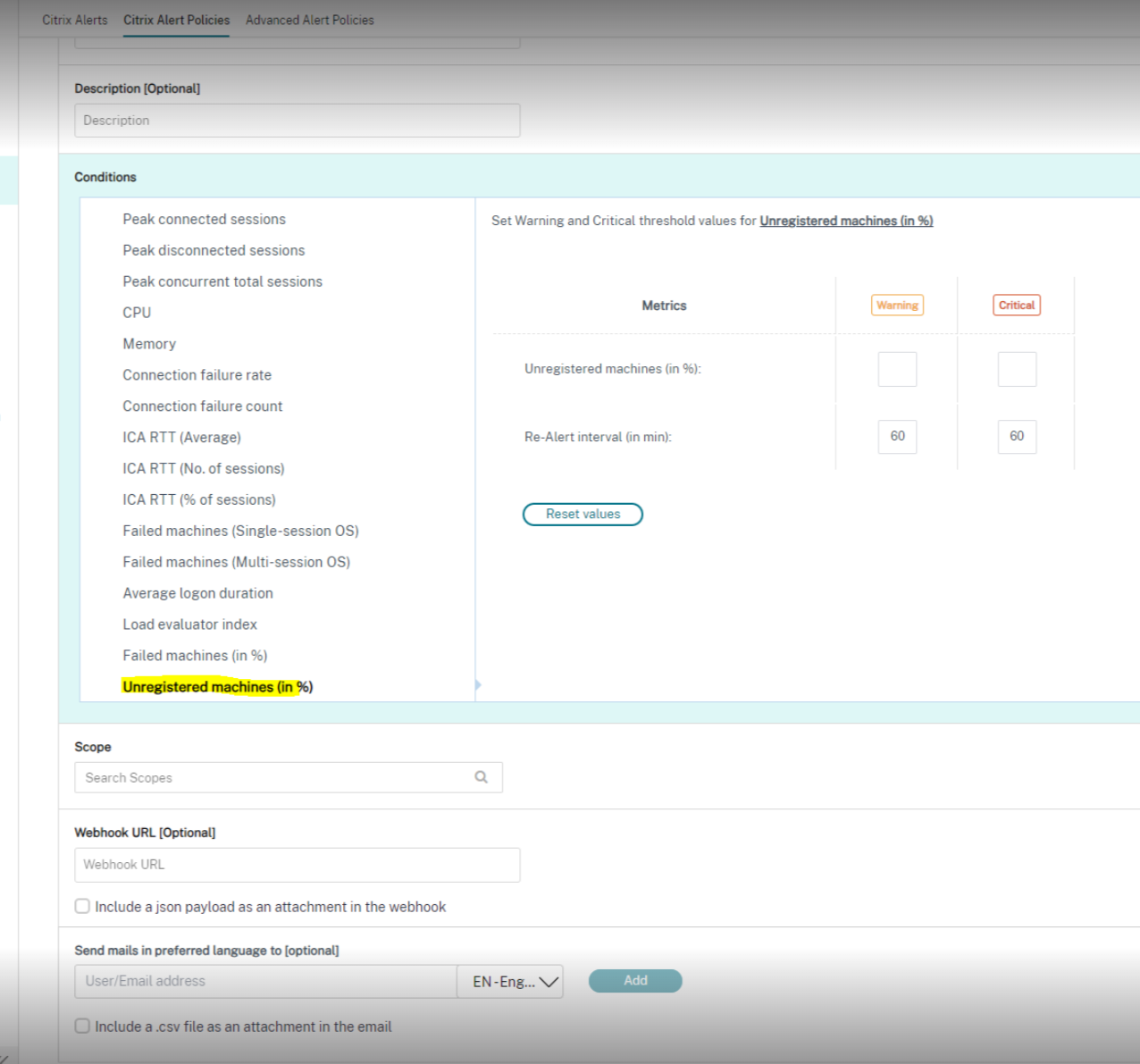
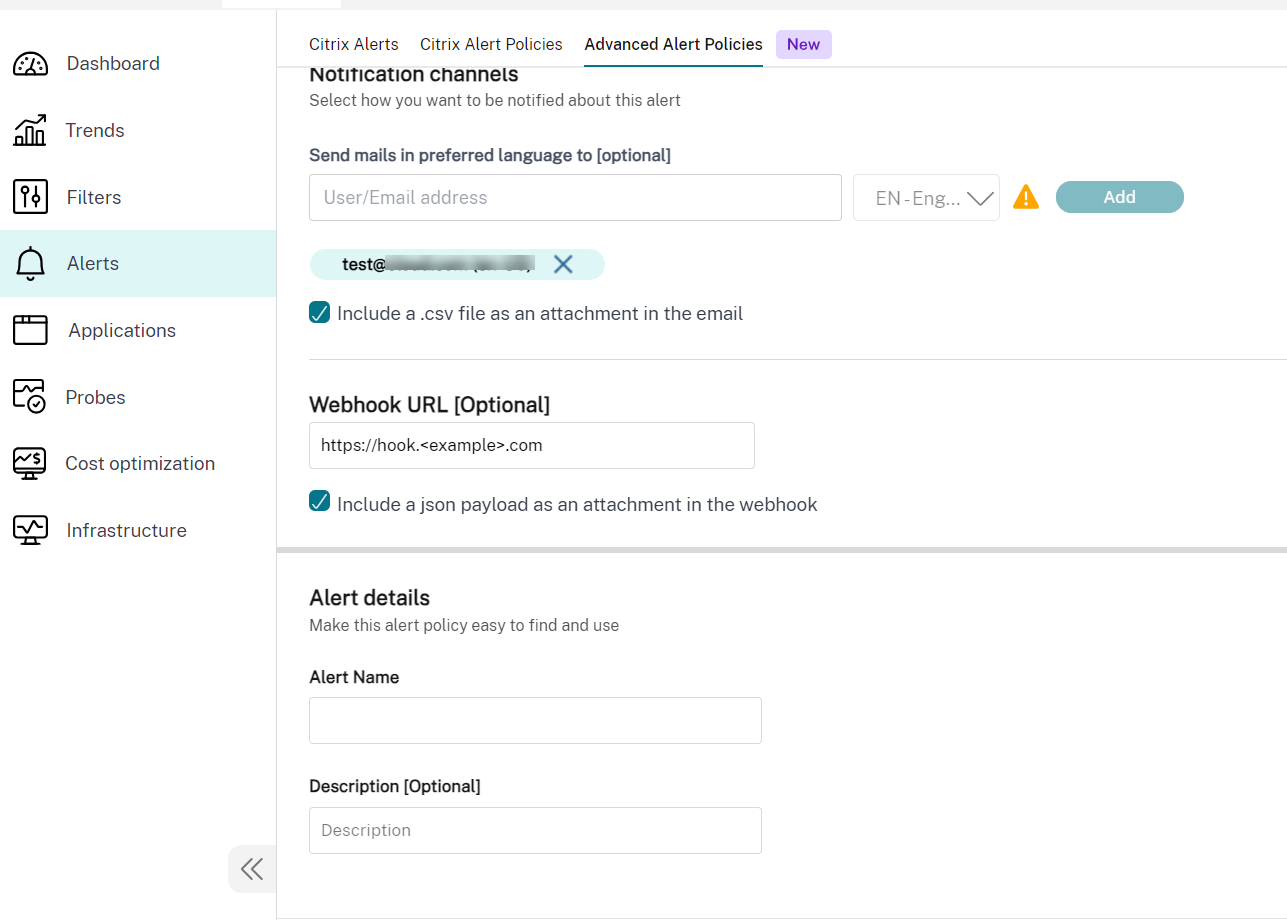
Para usar esta función, ve a la alerta y selecciona las siguientes casillas de verificación:
-
Incluir una carga útil JSON como archivo adjunto en el webhook
-
- Incluir un archivo CSV como archivo adjunto en el correo electrónico
La siguiente es una captura de pantalla de la sección Directivas de alertas de Citrix:
Aquí tienes una captura de pantalla de la sección Directivas de alertas avanzadas:
La siguiente tabla proporciona las columnas del archivo .CSV adjunto para todas las alertas admitidas:
| Columna | Alerta aplicable | |
|---|---|---|
| Nombre de la máquina, dirección IP y nombre del grupo de entrega | Tiempo de actividad de la máquina, acción de apagado fallida y acción de encendido fallida, y máquinas no registradas (%) | |
| Estado de registro actual, fecha de error, estado de error y estado del ciclo de vida | Máquina no registrada (%) | |
| Motivo del último error de acción de energía, última acción de energía activada por, tipo de última acción de energía y fecha de finalización de la última acción de energía | Acción de apagado fallida y acción de encendido fallida | |
| - | Estado de energía, fecha de encendido y tiempo total de actividad en minutos | Tiempo de actividad de la máquina |
Carga útil del webhook
Alerta de porcentaje de máquinas no registradas
- ```
{
“text”: “{"Address":"
\",\"NotificationId\":\" \",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\" \",\"Condition\":\"Unregistered machines (in %)\",\"Value\":\" \",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\" \",\"Description\":\" \",\"Scope\":\"DeliveryGroup\",\"Site\":\" \",\"AttachmentData\":[{\"MachineName\":\" \",\"IPAddress\":\" \",\"DeliveryGroupName\":\" \",\"CurrentRegistrationState\":\"Unregistered\",\"FailureDate\":\" \",\"FaultState\":\" \",\"LifecycleState\":\" \"},{\"MachineName\":\" \",\"IPAddress\":\" \",\"DeliveryGroupName\":\" \",\"CurrentRegistrationState\":\"Unregistered\",\"FailureDate\":\" \",\"FaultState\":\" \",\"LifecycleState\":\" \"}]}" }
##### Alerta de acciones de encendido fallidas
- {
- "text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Failure To PowerOn Action\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure, HypervisorRateLimitExceeded, UnknownError, Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User, Administrator, Auto-Scale, Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure, HypervisorRateLimitExceeded, UnknownError, Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User, Administrator, Auto-Scale, Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"}]}" }
##### Alerta de acciones de apagado fallidas
- {
- "text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Failure To PowerOff Action\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IPV4 Address of the Machine>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure,HypervisorRateLimitExceeded,UnknownError,Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User,Administrator,Auto-Scale,Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IPV4 Address of the Machine>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure,HypervisorRateLimitExceeded,UnknownError,Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User,Administrator,Auto-Scale,Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"}]}" }
##### Alerta de tiempo de actividad de la máquina
{
“text”: “{"Address":"
## Condiciones de las directivas de alertas
A continuación, encontrarás las categorías de alertas, las acciones recomendadas para mitigar la alerta y las condiciones de directiva integradas, si están definidas. Las directivas de alertas integradas se definen para intervalos de alerta y realerta de 60 minutos.
### Sesiones conectadas máximas
- Consulta la vista Tendencias de sesión del monitor para ver las sesiones conectadas máximas.
- Asegúrate de que haya suficiente capacidad para soportar la carga de sesiones.
- Agrega nuevas máquinas si es necesario.
### Sesiones desconectadas máximas
- Consulta la vista Tendencias de sesión del monitor para ver las sesiones desconectadas máximas.
- Asegúrate de que haya suficiente capacidad para soportar la carga de sesiones.
- Agrega nuevas máquinas si es necesario.
- Cierra la sesión de las sesiones desconectadas si es necesario.
### Sesiones concurrentes totales máximas
- Consulta la vista Tendencias de sesión del monitor en Monitor para ver las sesiones concurrentes máximas.
- Asegúrate de que haya suficiente capacidad para soportar la carga de sesiones.
- Agrega nuevas máquinas si es necesario.
- Cierra la sesión de las sesiones desconectadas si es necesario.
### CPU
- El porcentaje de uso de la CPU indica el consumo general de la CPU en el VDA, incluido el de los procesos. Puedes obtener más información sobre la utilización de la CPU por procesos individuales en la página **Detalles de la máquina** del VDA correspondiente.
- Ve a **Detalles de la máquina > Ver utilización histórica > 10 procesos principales**, identifica los procesos que consumen la CPU. Asegúrate de que la directiva de supervisión de procesos esté habilitada para iniciar la recopilación de estadísticas de uso de recursos a nivel de proceso.
- Finaliza el proceso si es necesario.
- Al finalizar el proceso, se perderán los datos no guardados.
- Si todo funciona como se espera, agrega más recursos de CPU en el futuro.
> **Nota:**
>
> La configuración de directiva, **Habilitar supervisión de recursos**, está permitida de forma predeterminada para la supervisión de contadores de rendimiento de CPU y memoria en máquinas con VDA. Si esta configuración de directiva está deshabilitada, no se activarán las alertas con condiciones de CPU y memoria. Para obtener más información, consulta [Configuración de directivas de supervisión](/es-es/citrix-virtual-apps-desktops/policies/reference/virtual-delivery-agent-policy-settings/monitoring-policy-settings.html).
**Condiciones de directiva inteligentes:**
- **Ámbito:** Grupo de entrega, ámbito de SO multisesión
- **Valores de umbral:** Advertencia - 80%, Crítico - 90%
### Memoria
- El porcentaje de uso de la memoria indica el consumo general de memoria en el VDA, incluido el de los procesos. Puedes obtener más información sobre el uso de la memoria por procesos individuales en la página **Detalles de la máquina** del VDA correspondiente.
- Ve a **Detalles de la máquina > Ver utilización histórica > 10 procesos principales**, identifica los procesos que consumen memoria. Asegúrate de que la directiva de supervisión de procesos esté habilitada para iniciar la recopilación de estadísticas de uso de recursos a nivel de proceso.
- Finaliza el proceso si es necesario.
- Al finalizar el proceso, se perderán los datos no guardados.
- Si todo funciona como se espera, agrega más memoria en el futuro.
> **Nota:**
>
> La configuración de directiva **Habilitar supervisión de recursos** está permitida de forma predeterminada para la supervisión de contadores de rendimiento de CPU y memoria en máquinas con VDA. Si esta configuración de directiva está deshabilitada, no se activarán las alertas con condiciones de CPU y memoria. Para obtener más información, consulta [Configuración de directivas de supervisión](/es-es/citrix-virtual-apps-desktops/policies/reference/virtual-delivery-agent-policy-settings/monitoring-policy-settings.html).
**Condiciones de directiva inteligentes:**
- **Ámbito:** Grupo de entrega, ámbito de SO multisesión
- **Valores de umbral:** Advertencia - 80%, Crítico - 90%
### Tasa de errores de conexión
Porcentaje de errores de conexión durante la última hora.
- Se calcula en función del total de fallos respecto al total de intentos de conexión.
- Consulta la vista Tendencias de fallos de conexión del monitor para ver los eventos registrados en el registro de configuración.
- Determina si las aplicaciones o los escritorios son accesibles.
### Recuento de fallos de conexión
Número de fallos de conexión en la última hora.
- Consulta la vista Tendencias de fallos de conexión del monitor para ver los eventos registrados en el registro de configuración.
- Determina si las aplicaciones o los escritorios son accesibles.
### ICA® RTT (promedio)
Tiempo de ida y vuelta (RTT) promedio de ICA.
- Consulta Citrix ADM para ver un desglose del RTT de ICA y determinar la causa raíz. Para obtener más información, consulta la documentación de [Citrix ADM](/es-es/netscaler-mas/12-1.html).
- Si Citrix ADM no está disponible, consulta la vista Detalles de usuario del monitor para ver el RTT de ICA y la latencia, y determina si se trata de un problema de red o un problema con las aplicaciones o los escritorios.
### ICA RTT (núm. de sesiones)
Número de sesiones que superan el tiempo de ida y vuelta (RTT) de ICA umbral.
- Consulta Citrix ADM para ver el número de sesiones con un RTT de ICA alto. Para obtener más información, consulta la documentación de [Citrix ADM](/es-es/netscaler-mas/12-1.html).
- Si Citrix ADM no está disponible, ponte en contacto con el equipo de red para determinar la causa raíz.
**Condiciones de la directiva inteligente:**
- **Ámbito:** Grupo de entrega, ámbito de SO multisesión
- **Valores de umbral:** Advertencia: 300 ms para 5 o más sesiones, Crítico: 400 ms para 10 o más sesiones
### ICA RTT (% de sesiones)
Porcentaje de sesiones que superan el tiempo de ida y vuelta (RTT) promedio de ICA.
- Consulta Citrix ADM para ver el número de sesiones con un RTT de ICA alto. Para obtener más información, consulta la documentación de [Citrix ADM](/es-es/netscaler-mas/12-1.html).
- Si Citrix ADM no está disponible, ponte en contacto con el equipo de red para determinar la causa raíz.
### ICA RTT (usuario)
Tiempo de ida y vuelta (RTT) de ICA que se aplica a las sesiones iniciadas por el usuario especificado. La alerta se activa si el RTT de ICA es superior al umbral en al menos una sesión.
### Máquinas con fallos (SO de sesión única)
Número de máquinas con SO de sesión única que han fallado. Los fallos pueden ocurrir por varias razones, como se muestra en las vistas Panel de control del monitor y Filtros.
- Ejecuta los diagnósticos de Citrix Scout para determinar la causa raíz. Para obtener más información, consulta [Solucionar problemas de usuario](/es-es/citrix-daas/monitor/troubleshoot-deployments/user-issues.html).
**Condiciones de la directiva inteligente:**
- **Ámbito:** Ámbito del grupo de entrega
- **Valores de umbral:** Advertencia: 1, Crítico: 2
### Máquinas con fallos (SO multisesión)
Número de máquinas con SO multisesión que han fallado. Los fallos pueden ocurrir por varias razones, como se muestra en las vistas Panel de control del monitor y Filtros.
- Ejecuta los diagnósticos de Citrix Scout para determinar la causa raíz.
**Condiciones de la directiva inteligente:**
- **Ámbito:** Grupo de entrega, ámbito de SO multisesión
- **Valores de umbral:** Advertencia: 1, Crítico: 2
### Máquinas con fallos (en %)
El porcentaje de máquinas con SO de sesión única y multisesión que han fallado en un grupo de entrega, calculado en función del número de máquinas con fallos. Esta condición de alerta te permite configurar umbrales de alerta como un porcentaje de máquinas con fallos en un grupo de entrega y se calcula cada 30 segundos.
Los fallos pueden ocurrir por varias razones, como se muestra en las vistas Panel de control del monitor y Filtros. Ejecuta los diagnósticos de Citrix Scout para determinar la causa raíz. Para obtener más información, consulta [Solucionar problemas de usuario](/es-es/citrix-daas/monitor/troubleshoot-deployments/user-issues.html).
### Acción de encendido fallida y acción de apagado fallida
Número de acciones de encendido fallidas y número de acciones de apagado fallidas en un grupo de entrega, calculado en función del número de **máquinas administradas por energía** que no se pudieron encender o apagar. Esta condición de alerta te permite configurar umbrales de alerta como el número de **máquinas administradas por energía** que no se pudieron encender o apagar en un grupo de entrega y se calcula cada 30 minutos.
El administrador puede configurar los siguientes parámetros para estas alertas en la directiva de alerta avanzada:
- Activado por: Qué activó la acción de energía
- Motivo del fallo: Por qué falló la acción
- Umbral: Número umbral de máquinas cuya acción de energía falló para activar la directiva
- Intervalo de muestreo: El intervalo en el que se debe comprobar la acción de energía fallida
- Intervalo de nueva alerta: Después de cuánto tiempo se debe volver a enviar la alerta
Los fallos pueden ocurrir por varias razones, como se muestra en las vistas Panel de control del monitor y Filtros. Ejecuta los diagnósticos de Citrix Scout para determinar la causa raíz. Para obtener más información, consulta [Solucionar problemas de usuario](/es-es/citrix-daas/monitor/troubleshoot-deployments/user-issues).
### Máquinas no registradas (en %)
Una máquina se considera no registrada cuando se vuelve inestable debido a un reinicio o cuando hay un problema de comunicación entre el delivery controller™ y las máquinas virtuales. El valor **Máquinas no registradas (en %)** es el porcentaje de máquinas con SO de sesión única y multisesión no registradas en un grupo de entrega, calculado en función del número de máquinas no registradas. Esta condición de alerta te permite configurar valores de umbral de advertencia y críticos como un porcentaje de máquinas no registradas en un grupo de entrega. Puedes establecer un intervalo para la nueva alerta. También puedes agregar un correo electrónico para recibir una notificación cuando se cumplan las condiciones para **Máquinas no registradas (en %)**. Cuando se supera el valor de umbral crítico o de advertencia, se generan alertas y correos electrónicos. Puedes ver las alertas en **Alertas de Citrix**. Puedes filtrarlas por la categoría **Máquinas no registradas (en %)** y por el estado y la hora requeridos.
>**Nota:**
>
> El valor crítico debe ser mayor que el valor de advertencia.
**Condiciones de la directiva:**
- **Ámbito**: SO de sesión única y grupo de entrega de SO multisesión
- **Valores de umbral**: Advertencia y Crítico
### Alerta de tiempo de actividad de la máquina
El tiempo de actividad de una máquina en un grupo de entrega se calcula en función del número de horas al día, a la semana o al mes que una máquina está encendida en un grupo de entrega. Esta condición de alerta te permite configurar umbrales de alerta como las horas que una máquina está encendida en un grupo de entrega. Las alertas de tiempo de actividad de la máquina funcionan de la siguiente manera en caso de:
- Horas al día: puedes especificar el número de horas que una máquina está encendida al día y se calcula cada 30 minutos. El número máximo de horas al día que puedes establecer es de 24 horas.
- Horas a la semana: puedes especificar el número de horas que una máquina está encendida a la semana y se calcula cada seis horas. El número máximo de horas a la semana que puedes establecer es de 168 horas.
- Horas al mes: puedes especificar el número de horas que una máquina está encendida al mes y se calcula una vez al día. El número máximo de horas al mes es de 720 horas.
El valor mínimo del intervalo de nueva alerta que puedes establecer es de 60 minutos. Puedes introducir el número de máquinas que superan el valor umbral de tiempo de actividad de la máquina en la sección de alertas de advertencia y críticas. También puedes agregar excepciones para cualquier máquina.
Por ejemplo, si hay cinco grupos de entrega agregados para esta alerta y si en el primer grupo de entrega y en el cuarto grupo de entrega, el número de máquinas supera los valores umbral de advertencia o críticos, la alerta se activa por separado para el primer grupo de entrega y para el cuarto grupo de entrega.
Esta alerta ayuda a los administradores a analizar el tiempo de actividad de las máquinas y, basándose en este análisis, los administradores pueden ayudar a optimizar el coste. También puedes recibir los detalles de la alerta en un archivo CSV adjunto en un correo electrónico o a través de una carga útil JSON en caso de un webhook.
### Duración media del inicio de sesión
- Duración media del inicio de sesión para los inicios de sesión que se produjeron durante la última hora.
- Consulta el panel de control de Monitor para obtener métricas actualizadas sobre la duración del inicio de sesión. Un gran número de usuarios que inician sesión en un corto período de tiempo puede aumentar la duración del inicio de sesión.
- Consulta la línea de base y el desglose de los inicios de sesión para acotar la causa. Para obtener más información, consulta [Diagnosticar problemas de inicio de sesión de usuario](/es-es/citrix-daas/monitor/troubleshoot-deployments/user-issues/user-logon.html).
**Condiciones de la directiva inteligente:**
- **Ámbito:** Grupo de entrega, ámbito de SO multisesión
- **Valores umbral:** Advertencia - 45 segundos, Crítico - 60 segundos
### Duración del inicio de sesión (usuario)
Duración del inicio de sesión para los inicios de sesión del usuario especificado que se produjeron durante la última hora.
### Índice del evaluador de carga
Valor del índice del evaluador de carga durante los últimos 5 minutos.
- Consulta Monitor para las máquinas con SO multisesión que puedan tener una carga máxima. Consulta tanto el panel de control (fallos) como el informe de tendencias del índice del evaluador de carga.
**Condiciones de la directiva inteligente:**
- **Ámbito:** Grupo de entrega, ámbito de SO multisesión
- **Valores umbral:** Advertencia - 80 %, Crítico - 90 %
## Configurar directivas de alerta con webhooks
Además de las notificaciones por correo electrónico, puedes configurar directivas de alerta con webhooks.
**Nota:** Esta característica requiere la versión 7.11 o posterior de Delivery Controller(s).
Puedes configurar una directiva de alerta con una devolución de llamada HTTP o un POST HTTP utilizando cmdlets de PowerShell. Se han ampliado para admitir webhooks.
Para obtener información sobre la creación de un nuevo flujo de trabajo de Octoblu y la obtención de la URL de webhook correspondiente, consulta el [Centro de desarrolladores de Octoblu](https://octoblu.readme.io/docs/api-guide).
Para configurar una URL de webhook para una nueva directiva de alerta o para una directiva existente, usa los siguientes cmdlets de PowerShell.
Crear directiva de alertas con una URL de webhook:
$policy = New-MonitorNotificationPolicy -Name
Agregar una URL de webhook a una directiva de alertas existente:
Set-MonitorNotificationPolicy - Uid
Para obtener ayuda sobre los comandos de **PowerShell**, usa la ayuda de PowerShell, por ejemplo:
Get-Help
Las notificaciones generadas a partir de la directiva de alerta activan el webhook con una llamada POST a la URL del webhook. El mensaje POST contiene la información de la notificación en formato JSON:
{“NotificationId” : <Notification Id>,
“Target” : <Notification Target Id>,
“Condition” : <Condition that was violated>,
“Value” : <Threshold value for the Condition>,
“Timestamp”: <Time in UTC when notification was generated>,
“PolicyName”: <Name of the Alert policy>,
“Description”: <Description of the Alert policy>,
“Scope” : <Scope of the Alert policy>,
“NotificationState”: <Notification state critical, warning, healthy or dismissed>,
“Site” : <Site name>}
### Configurar directivas de alerta con ServiceNow
Puedes configurar directivas de alerta para enviar notificaciones directamente a ServiceNow (SNOW), lo que permite una integración perfecta con tus flujos de trabajo de gestión de servicios de TI (ITSM). Esta integración permite que las alertas generadas en Citrix Monitor se reenvíen automáticamente a ServiceNow para un seguimiento centralizado, una escalada y una resolución de incidentes.
#### Ventajas de la integración con ServiceNow
- **Gestión unificada de alertas**: crea, actualiza y gestiona incidentes de ServiceNow directamente dentro de la interfaz de Citrix Monitor sin cambiar entre sistemas.
- **Configuración automática de ITSM**: Monitor recupera automáticamente la configuración necesaria de ServiceNow, como las URL de webhook, lo que reduce la complejidad de la configuración manual.
- **Respuesta optimizada a incidentes**: las alertas se reenvían a ServiceNow para un seguimiento y resolución centralizados de incidentes, lo que mejora la eficiencia operativa.
#### Requisitos previos
Antes de configurar la integración con ServiceNow, asegúrate de lo siguiente:
- Una instancia de ServiceNow está configurada en el servicio ITSM Adapter.
- Tienes los permisos necesarios para gestionar directivas de alerta en Monitor.
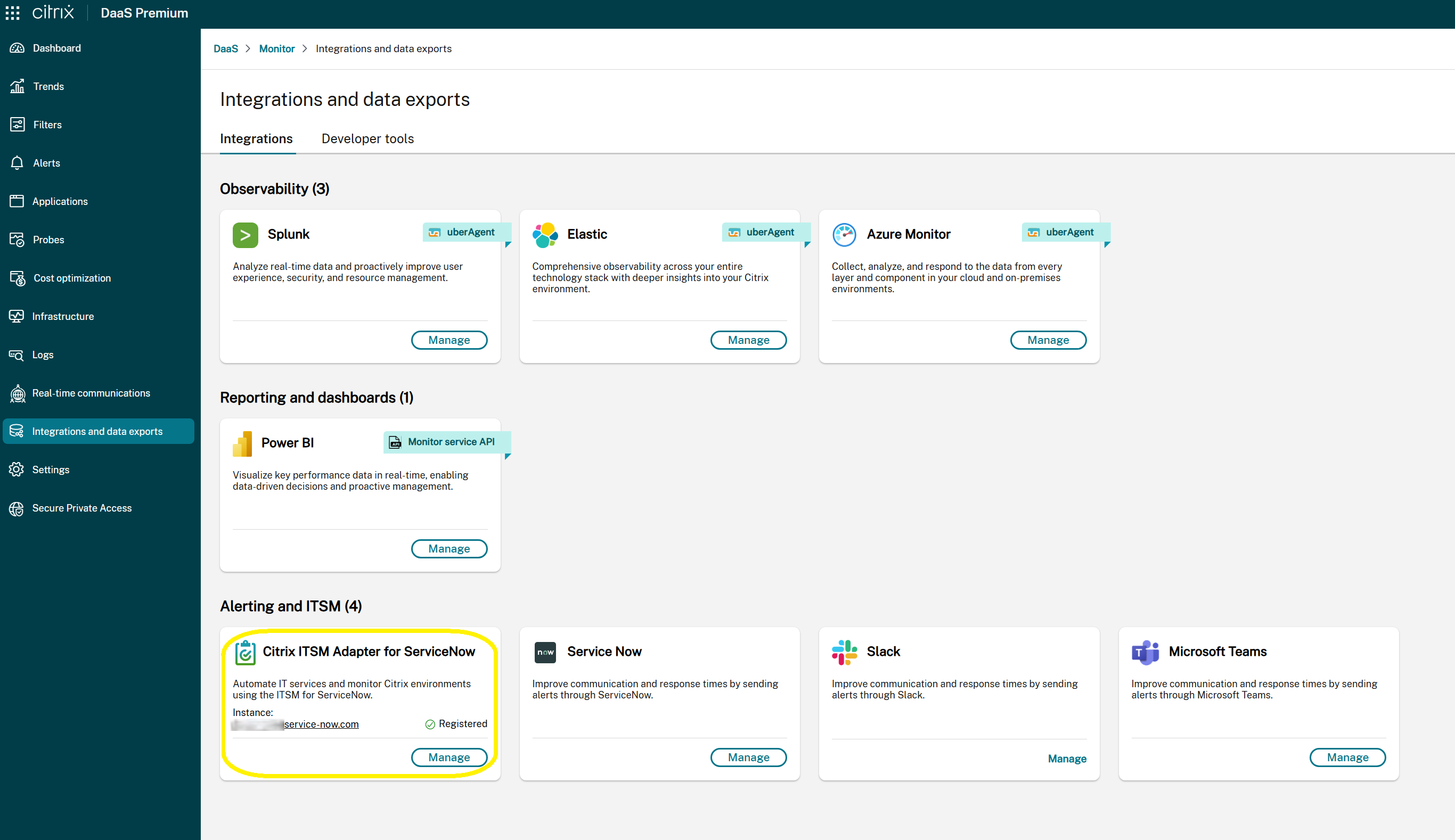
#### Comprobar el estado de la integración con ServiceNow
Puedes ver el estado de la integración con el servicio ITSM Adapter en la página **Monitor** > **Integraciones y exportaciones de datos**. Esta página muestra:
- El estado actual de la integración:
- **Empezar**: Indica que la integración de ITSM Adapter no se ha configurado. Selecciona esta opción para iniciar el proceso de configuración inicial.
- **Administrar**: Indica que la integración de ITSM Adapter está activa y operativa. Selecciona esta opción para ver o modificar la configuración de tu integración con ServiceNow.
- La URL de la instancia de ServiceNow asociada (visible solo cuando se ha configurado una instancia de ServiceNow en ITSM Adapter).
#### Configurar una política de alertas con notificaciones de ServiceNow
Para configurar una política de alertas para enviar notificaciones a ServiceNow:
1. Ve a **Alertas** > **Política de alertas de Citrix** y selecciona la categoría de la política (por ejemplo, Política de SO multisesión).
1. Haz clic en **Crear** para crear una nueva política o selecciona una política existente y haz clic en **Modificar**.
1. Configura las condiciones de la política según sea necesario.
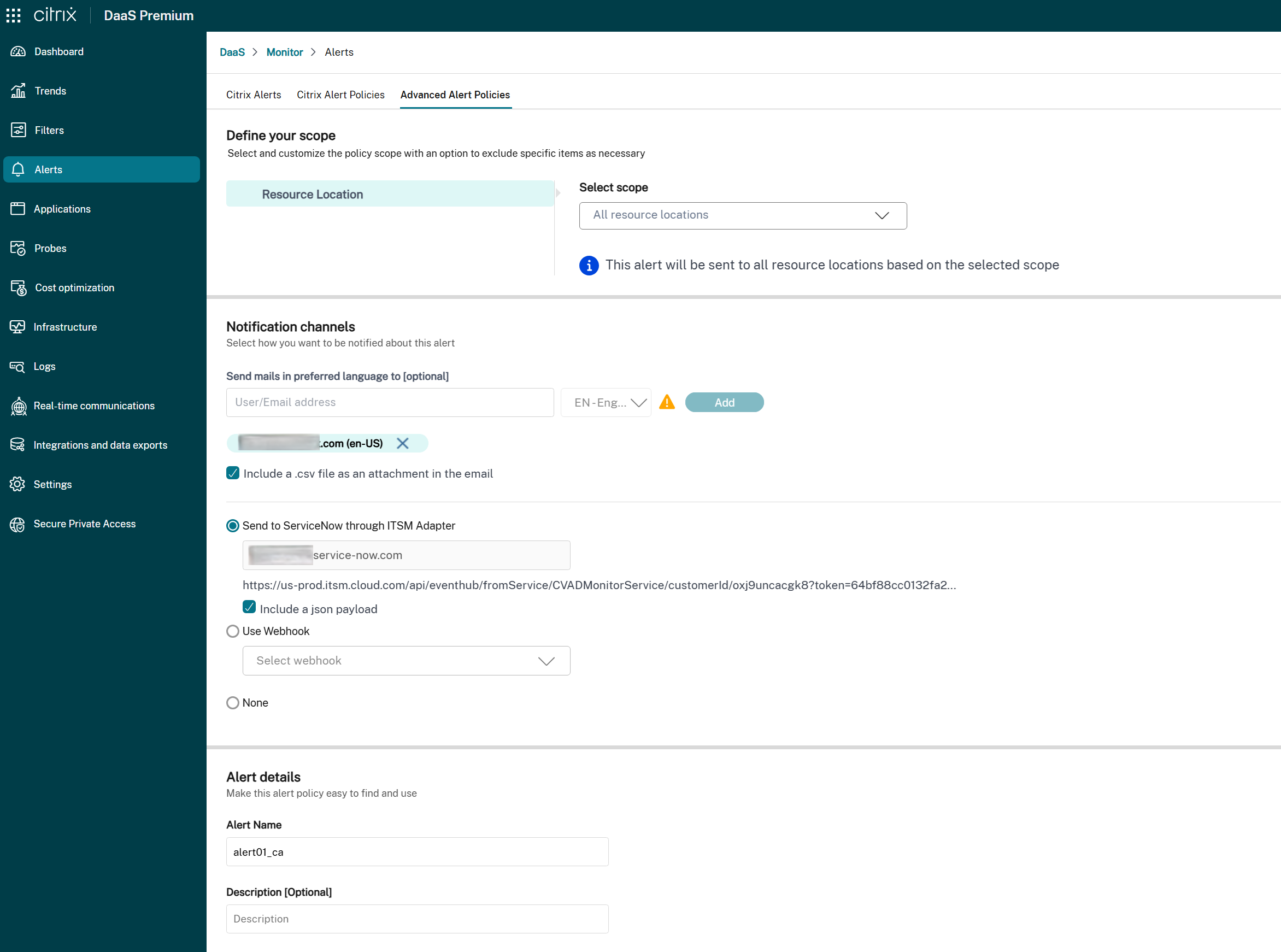
1. En la sección **Preferencias de notificación**, busca la opción **Integración de ServiceNow**:
- **Si ITSM Adapter está disponible:**
- Marca la casilla para habilitar las notificaciones de alerta a través de ServiceNow para esta política.
- La URL de la instancia de ServiceNow asociada se muestra como referencia.
- Si la política ya tiene un webhook configurado, un mensaje de advertencia te informa de que la habilitación de la integración de ServiceNow anula la configuración de webhook existente.
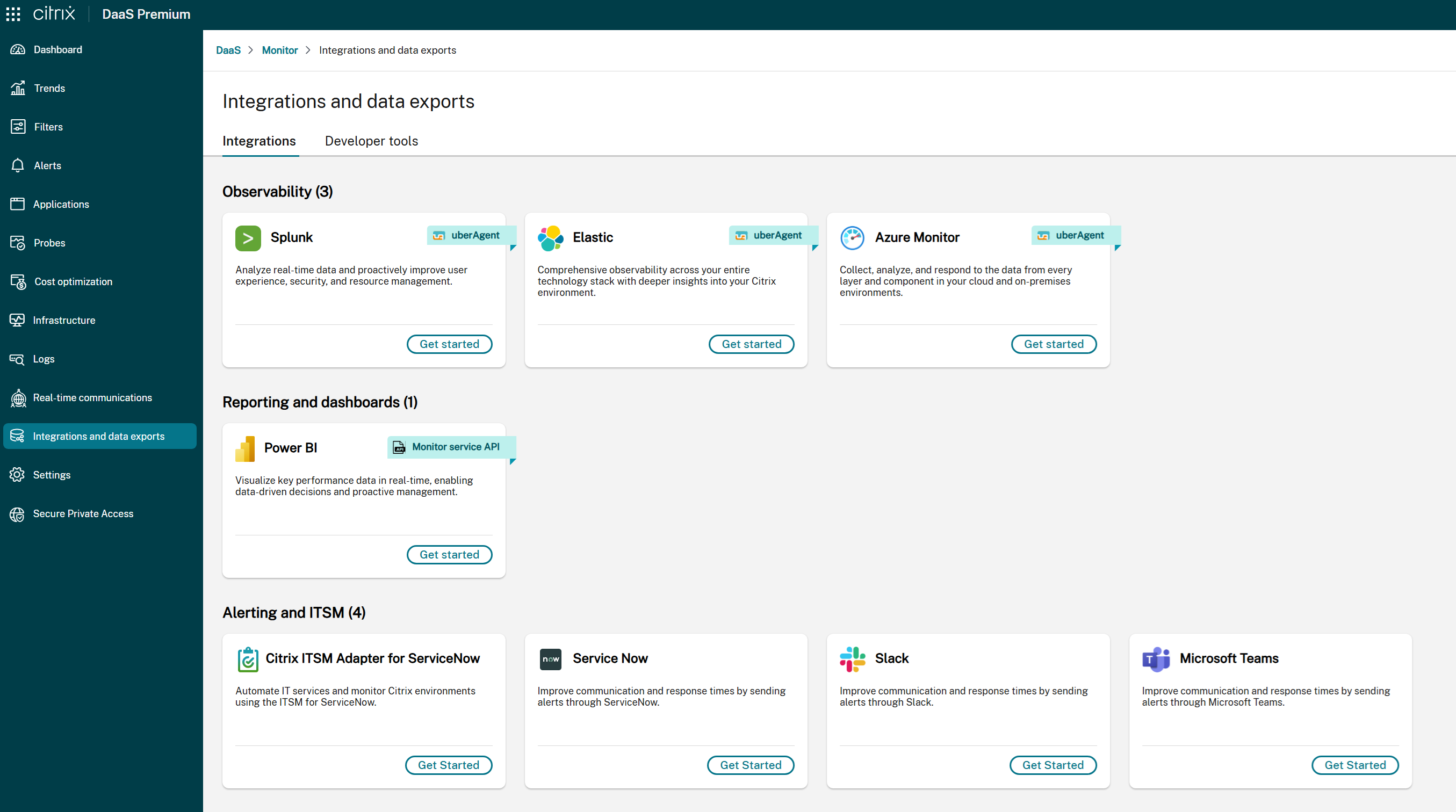
- **Si ITSM Adapter no está disponible:**
- Un mensaje indica que la integración de ITSM no está configurada actualmente.
- Haz clic en **Empezar** para acceder a la configuración de la integración. Para obtener más detalles, consulta la [documentación](https://docs.citrix.com/es-es/citrix-itsm-adapter-service/onboard).
1. Haz clic en **Guardar** para guardar la política.
Una vez configuradas, las alertas que cumplen las condiciones de la política se reenvían automáticamente a ServiceNow, donde se pueden gestionar como incidentes o eventos según tu configuración de ITSM.
## Descarte masivo de alertas
Esta función optimiza el proceso de gestión de alertas para los administradores, proporcionando flexibilidad y reduciendo la fatiga por alertas. Los administradores pueden descartar alertas de forma masiva según la hora, el tipo o la categoría, lo que simplifica la gestión de alertas durante el mantenimiento o al tratar con hipervisores y otros entornos.
El descarte masivo de alertas ayuda a los administradores a gestionar su carga de trabajo de manera eficiente y evita que se vean abrumados por un gran volumen de alertas.
### Pasos para descartar alertas de forma masiva
1. Navega a la ficha **Alertas** > **Alertas de Citrix**. Se muestran las alertas.
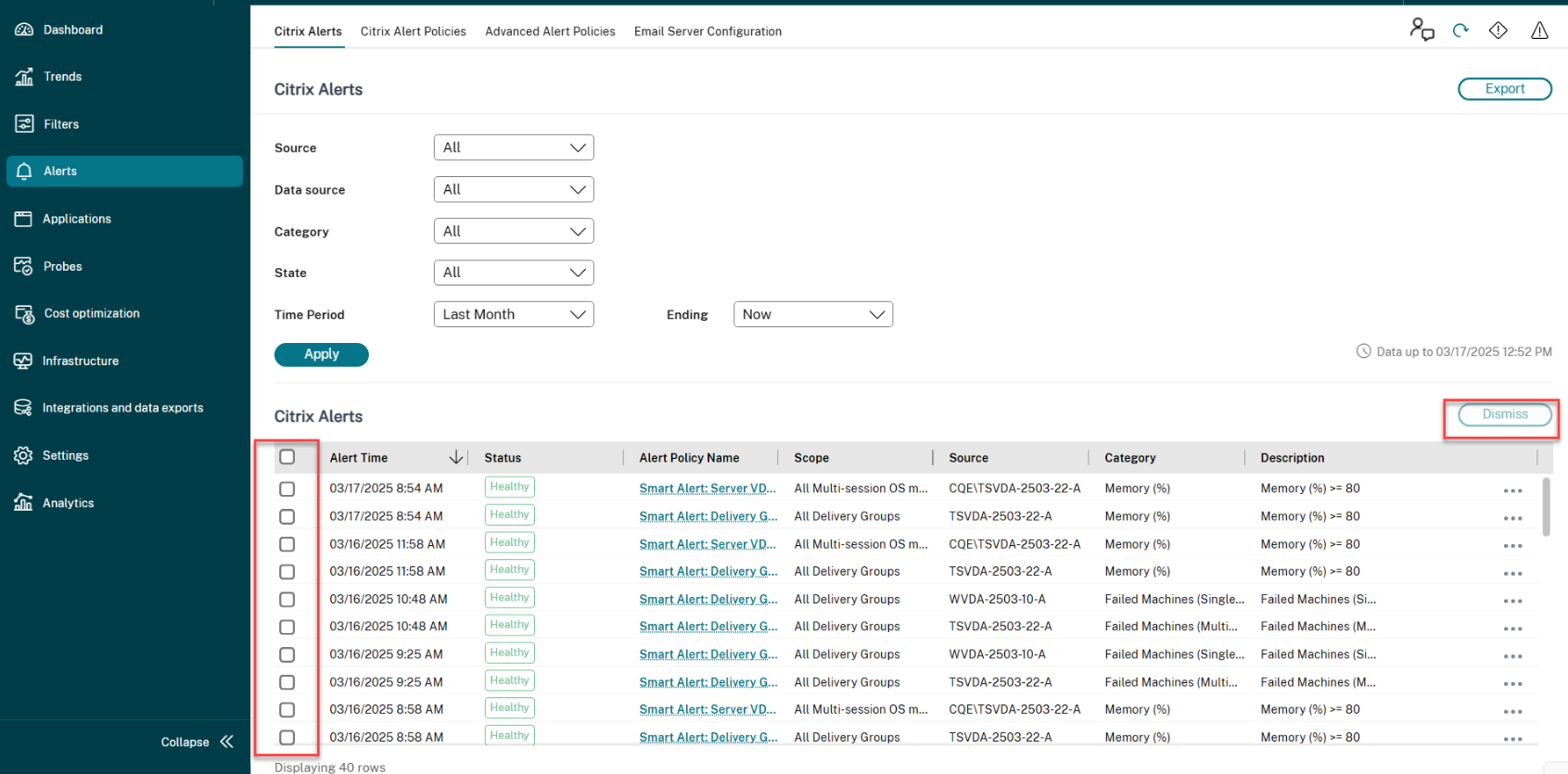
1. Selecciona una opción de **Origen**, **Categoría**, **Estado** o **Período de tiempo** para filtrar las alertas que quieres descartar. Se muestran las alertas específicas.
1. Marca la casilla junto a una alerta específica o en la parte superior para seleccionar todas las alertas.
1. Haz clic en **Descartar**. Aparece una notificación para confirmar el descarte de las alertas.
1. Haz clic en **Sí**. Las alertas seleccionadas se marcan como *descartadas* y el estado de la alerta se actualiza en consecuencia.
## Configuración de webhook mediante PowerShell SDK
La función de configuración de webhook mediante PowerShell SDK permite a los administradores crear, modificar, eliminar y listar perfiles de webhook. Esta función proporciona flexibilidad en la configuración de webhooks al permitir la especificación de encabezados, tipos de autenticación, tipos de contenido, cargas útiles y URL de webhook.
>**Nota:**
>
> El formato de carga útil admitido es texto y el usuario final debe habilitar el texto en su webhook.
El formato de carga útil más reciente es:
{“text”: “This is a message from a Webex incoming webhook.”}
### Crear un webhook
Puedes usar el siguiente comando de PowerShell de ejemplo para crear un perfil de webhook:
**Crear un webhook sin encabezado de autorización:**
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add(“Content-Type”, “application/json”)
$payloads = ‘{ “text”: “$PAYLOAD” }’
$url = “
Add-MonitorWebhookProfile -Name “webhookprofile1” -Description “Description” -Url $url -Headers $headers -PayloadFormat $payloads -Platform Slack -Type Webhook -MethodType POST
**Crear un webhook con encabezado de autorización:**
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add(“Content-Type”, “application/json”)
$headers.Add(“Authorization”, “Basic
$payloads = ‘{ “text”: “$PAYLOAD” }’
$url = “
Add-MonitorWebhookProfile -Name “webhookprofile1” -Description “Description” -Url $url -Headers $headers -PayloadFormat $payloads -Platform Slack -Type Webhook -MethodType POST
**Ejemplo:**
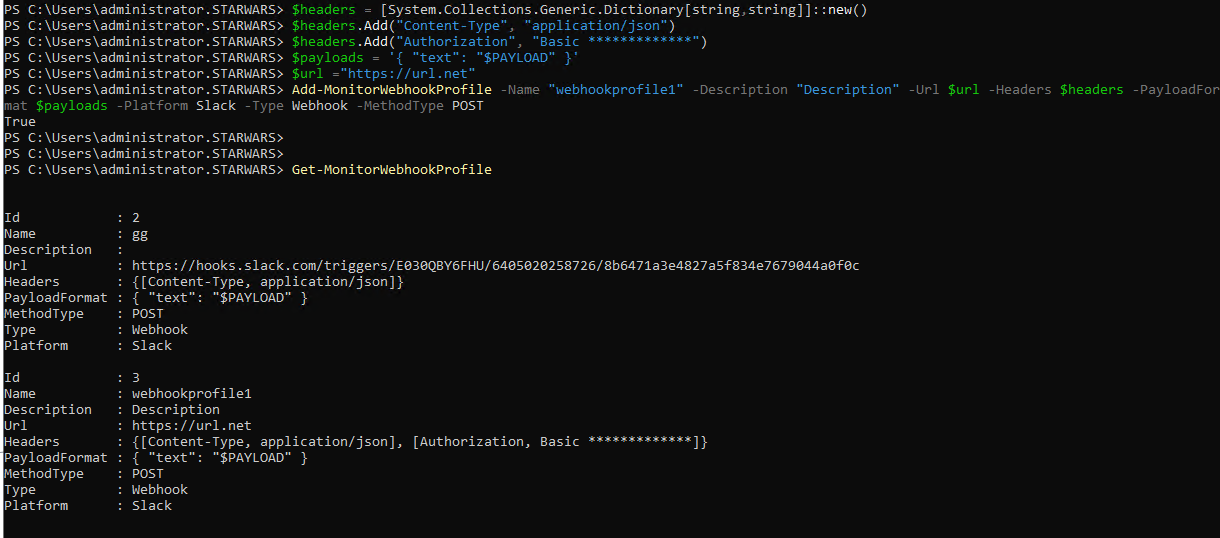
Una vez creado el perfil, puedes comprobarlo en la base de datos. Además, puedes encontrar el perfil de webhook recién creado en la página **Alertas de Citrix**.
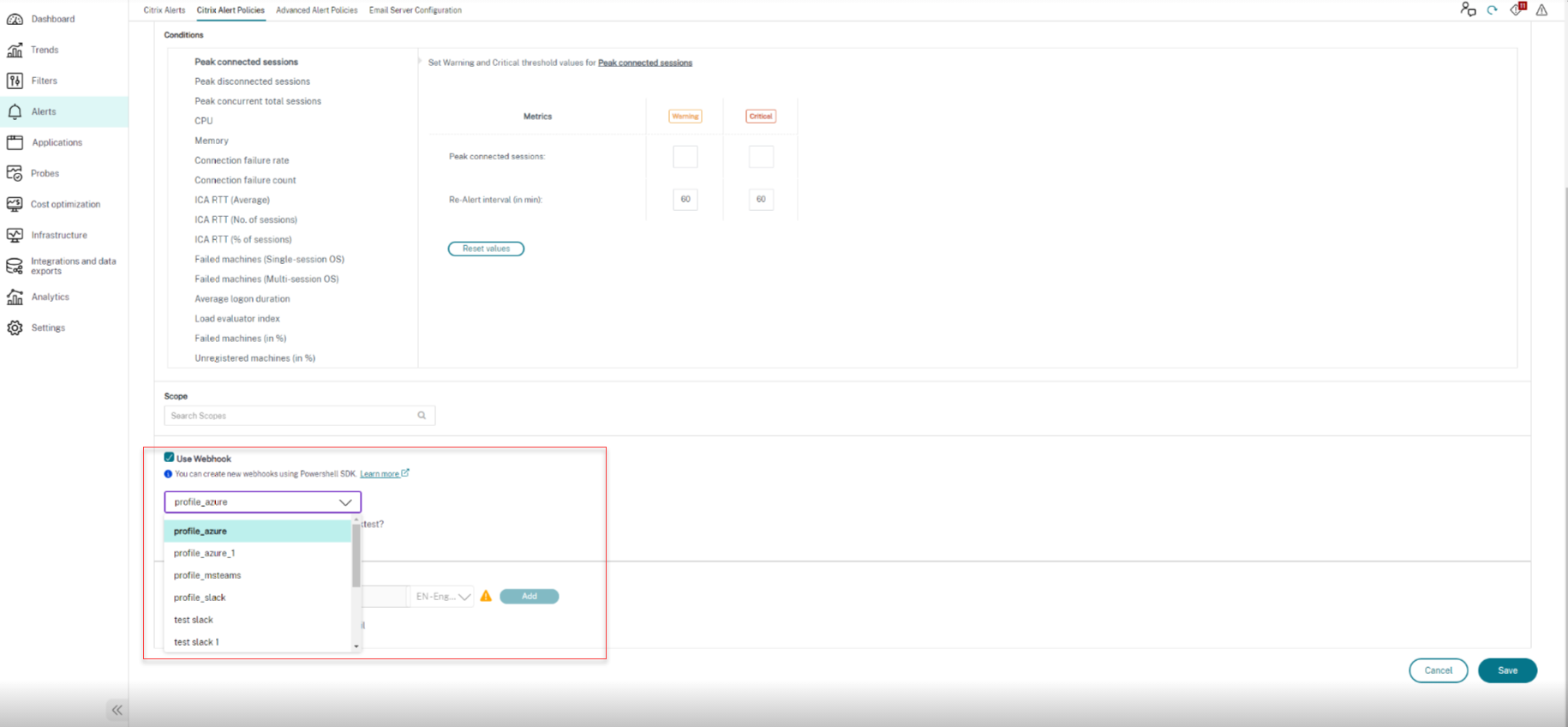
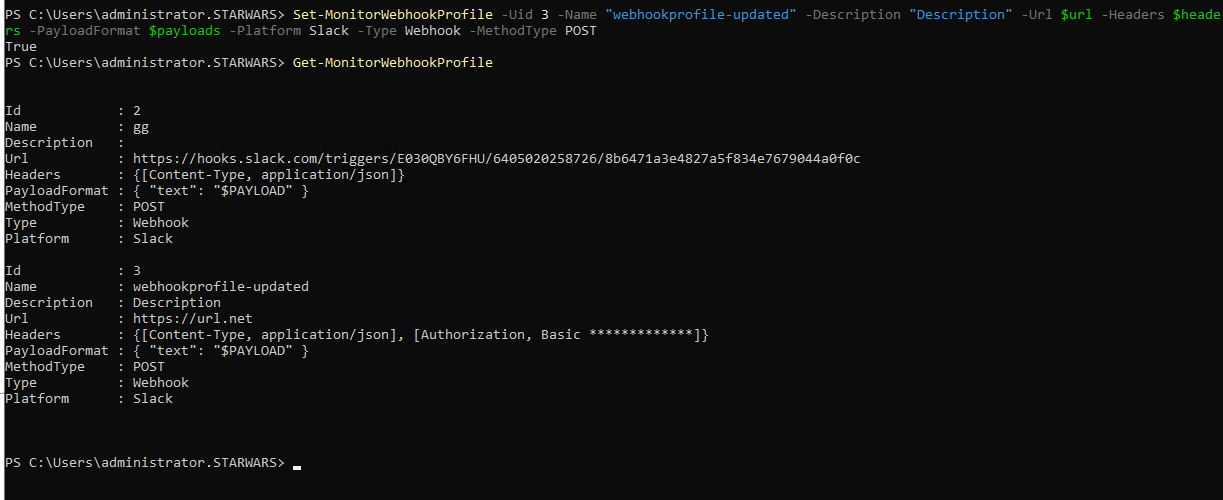
### Actualizar un perfil de webhook
Puedes usar el siguiente comando de PowerShell de ejemplo para actualizar un perfil de webhook:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add(“Content-Type”, “application/json”)
$payloads = ‘{ “text”: “$PAYLOAD” }’
$url = “
Set-MonitorWebhookProfile -Uid 1 -Name “profile_slack_citrix” -Description “webhook profile for citrix slack” -Url $url -Headers $headers -PayloadFormat $payloads -Platform Slack -Type Webhook -MethodType POST
### Obtener una lista de todos los perfiles de webhook
Puedes usar el siguiente comando de PowerShell de ejemplo para obtener una lista de todos los perfiles de webhook disponibles:
Get-MonitorWebhookProfile
Get-MonitorWebhookProfile -Name ‘profile_msteams’
Get-MonitorWebhookProfile -Uid 1
### Quitar un perfil de webhook
Puedes usar el siguiente comando de PowerShell de ejemplo para quitar un perfil de webhook:
Remove-MonitorWebhookProfile -Uid 1
> **Nota:**
>
> Si un perfil de webhook está asignado a alguna política, no se puede quitar. Como solución alternativa, primero debes quitar la asignación del webhook de la política.
### Crear una política con perfil de webhook
Puedes usar el siguiente comando de PowerShell de ejemplo para crear una política con perfil de webhook:
New-MonitorNotificationPolicy -Name “Policy1” -Description “Policy Description” -Enabled $true -WebhookProfileId 1
### Actualizar una política con perfil de webhook
Puedes usar el siguiente comando de PowerShell de ejemplo para actualizar una política con perfil de webhook:
$Policy = Set-MonitorNotificationPolicy -Uid 1 -WebhookProfileId 1
### Quitar la asignación de webhook de una política
Puedes usar el siguiente comando de PowerShell de ejemplo para quitar el perfil de webhook de una política:
$Policy = Set-MonitorNotificationPolicy -Uid 1 -WebhookProfileId 0
### Probar el perfil de webhook
Puedes usar el siguiente comando de PowerShell de ejemplo para probar el perfil de webhook:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add(“Content-Type”, “application/json”)
$headers.Add(“Authorization”, “Basic
$payloads = ‘{ “text”: “$PAYLOAD” }’
$url =”
Test-MonitorWebhookProfile -Url $url -Headers $headers -PayloadFormat $payloads
```
Supervisión de alertas de error de sincronización de configuración de Local Host Cache
Local Host Cache permite que las sesiones de usuario continúen incluso si los Cloud Connectors pierden la conectividad con Citrix Cloud. La caché utilizada por Local Host Cache se sincroniza regularmente con la base de datos principal para garantizar configuraciones actualizadas cuando se activa el modo Local Host Cache. Puedes obtener más información sobre Local Host Cache y el proceso de sincronización de configuración en Local Host Cache. Si la sincronización de la configuración falla más de tres veces consecutivas, Citrix Monitor envía una alerta de advertencia al administrador.
Se ha introducido una política de alertas predefinida llamada Local Host Cache - Config Sync Failure en Citrix Monitor para notificar a los administradores sobre los errores de sincronización de la configuración. Puedes encontrar la política recién introducida en Monitor > Citrix Alerts. Puedes modificar la política predefinida para agregar o modificar destinatarios de correo electrónico o webhooks para recibir notificaciones proactivas en tus herramientas de gestión de alertas o ITSM.
El alcance de la política de alertas Local Host Cache - Config Sync Failure se limita únicamente al sitio.
Supervisión de alertas de hipervisor
Monitor muestra alertas para supervisar el estado del hipervisor. Las alertas de Citrix Hypervisor™ y VMware vSphere ayudan a supervisar los parámetros y estados del hipervisor. También se supervisa el estado de la conexión al hipervisor para proporcionar una alerta si el clúster o el grupo de hosts se reinicia o no está disponible.
Para recibir alertas de hipervisor, asegúrate de que se haya creado una conexión de alojamiento en la ficha Administrar. Para obtener más información, consulta Conexiones y recursos. Solo estas conexiones se supervisan para las alertas de hipervisor. La siguiente tabla describe los diversos parámetros y estados de las alertas de hipervisor.
| Alerta | Hipervisores compatibles | Activado por | Condición | Configuración |
|---|---|---|---|---|
| Uso de CPU | Citrix Hypervisor, VMware vSphere | Hipervisor | Se alcanza o supera el umbral de alerta de uso de CPU | Los umbrales de alerta deben configurarse en el hipervisor. |
| Uso de memoria | Citrix Hypervisor, VMware vSphere | Hipervisor | Se alcanza o supera el umbral de alerta de uso de memoria | Los umbrales de alerta deben configurarse en el hipervisor. |
| Uso de red | Citrix Hypervisor, VMware vSphere | Hipervisor | Se alcanza o supera el umbral de alerta de uso de red | Los umbrales de alerta deben configurarse en el hipervisor. |
| Uso de disco | VMware vSphere | Hipervisor | Se alcanza o supera el umbral de alerta de uso de disco | Los umbrales de alerta deben configurarse en el hipervisor. |
| Conexión de host o estado de energía | VMware vSphere | Hipervisor | El host del hipervisor se ha reiniciado o no está disponible | Las alertas están preintegradas en VMware vSphere. No se necesitan configuraciones adicionales. |
| Conexión de hipervisor no disponible | Citrix Hypervisor, VMware vSphere | Delivery Controller | La conexión al hipervisor (grupo o clúster) se pierde, se apaga o se reinicia. Esta alerta se genera cada hora mientras la conexión no esté disponible. | Las alertas están preintegradas con el Delivery Controller. No se necesitan configuraciones adicionales. |
Nota:
Para obtener más información sobre la configuración de alertas, consulta Citrix XenCenter Alerts o revisa la documentación de VMware vCenter Alerts.
La preferencia de notificación por correo electrónico se puede configurar en Citrix Alerts Policy > Site Policy > Hypervisor Health. Las condiciones de umbral para las políticas de alerta de hipervisor se pueden configurar, modificar, deshabilitar o eliminar solo desde el hipervisor y no desde Monitor. Sin embargo, la modificación de las preferencias de correo electrónico y el descarte de una alerta se pueden realizar en Monitor.
Importante:
- Todas las alertas de hipervisor de más de un día se descartan automáticamente.
- Las alertas activadas por el hipervisor se recuperan y se muestran en Monitor. Sin embargo, los cambios en el ciclo de vida o el estado de las alertas del hipervisor no se reflejan en Monitor.
- Las alertas que están en estado correcto, descartadas o deshabilitadas en la consola del hipervisor seguirán apareciendo en Monitor y deberán descartarse explícitamente.
- Las alertas que se descartan en Monitor no se descartan automáticamente en la consola del hipervisor.
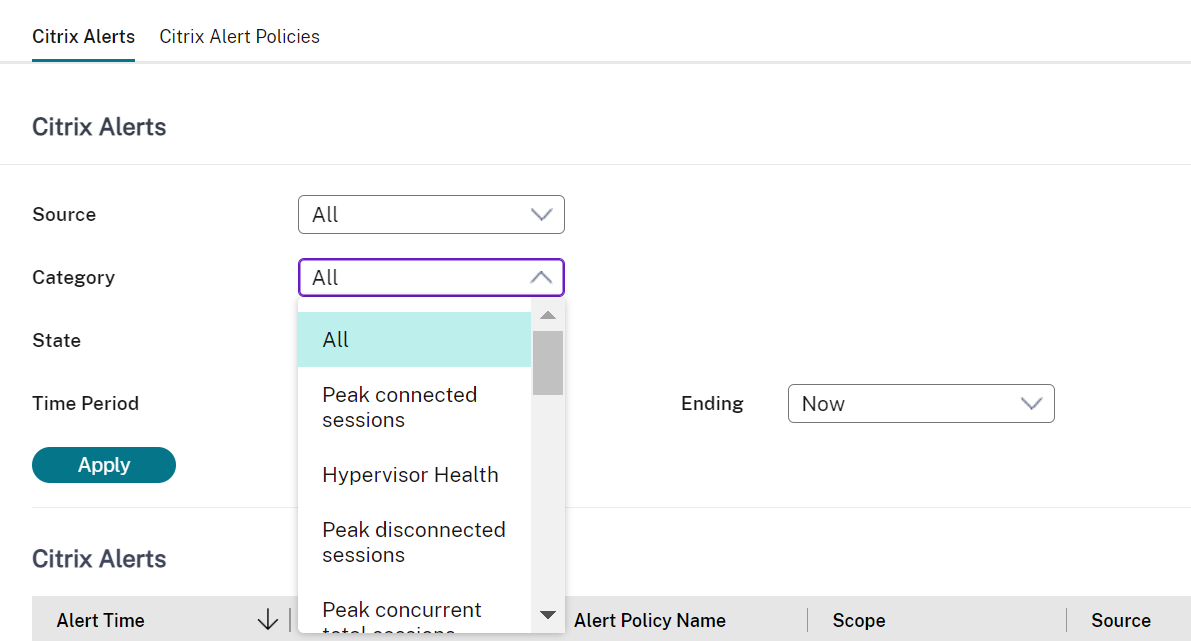
Se ha agregado una nueva categoría de alerta llamada Estado del hipervisor para permitir filtrar solo las alertas del hipervisor. Estas alertas se muestran una vez que se alcanzan o superan los umbrales. Las alertas de hipervisor pueden ser:
- Crítica: se alcanza o supera el umbral crítico de la política de alarma del hipervisor.
- Advertencia: se alcanza o supera el umbral de advertencia de la política de alarma del hipervisor.
- Descartada: la alerta ya no se muestra como una alerta activa.