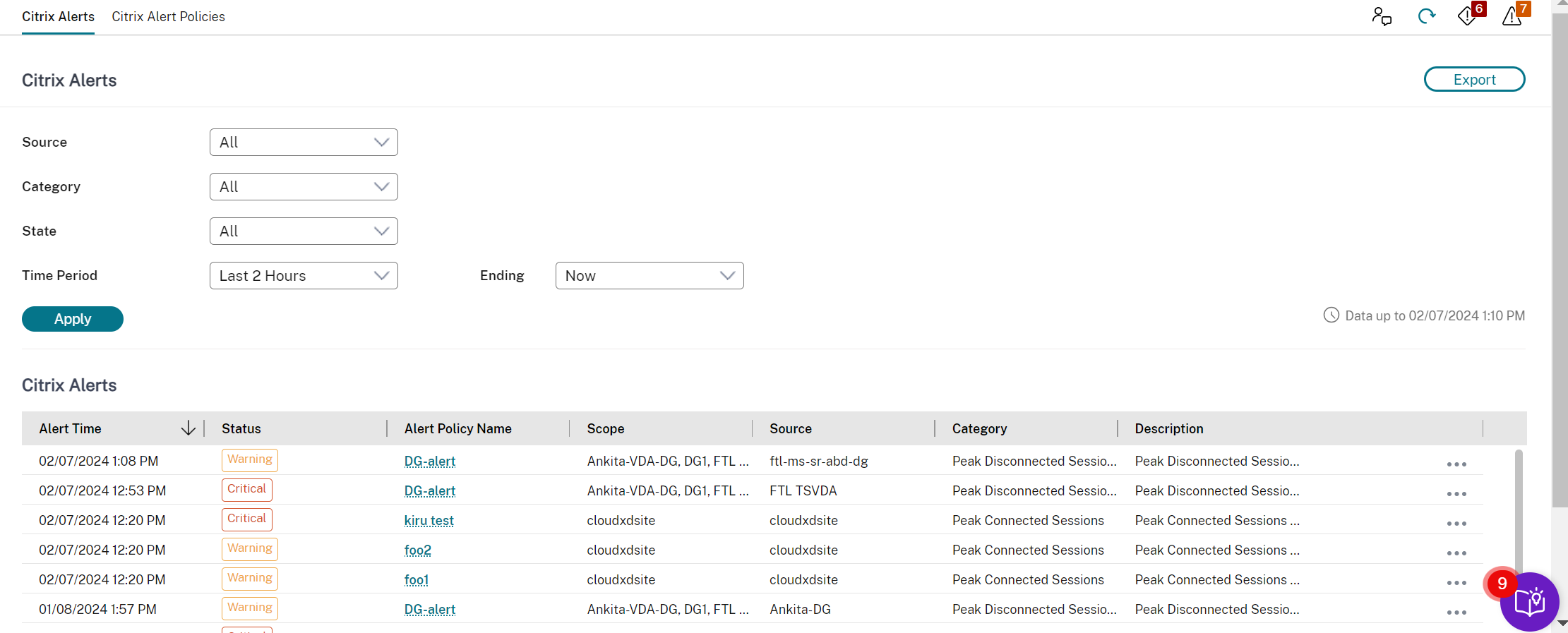
警报和通知
警报在 Monitor 的控制板和其他高级视图中显示,带有警告和严重警报符号。警报每分钟自动更新;您也可以按需更新警报。
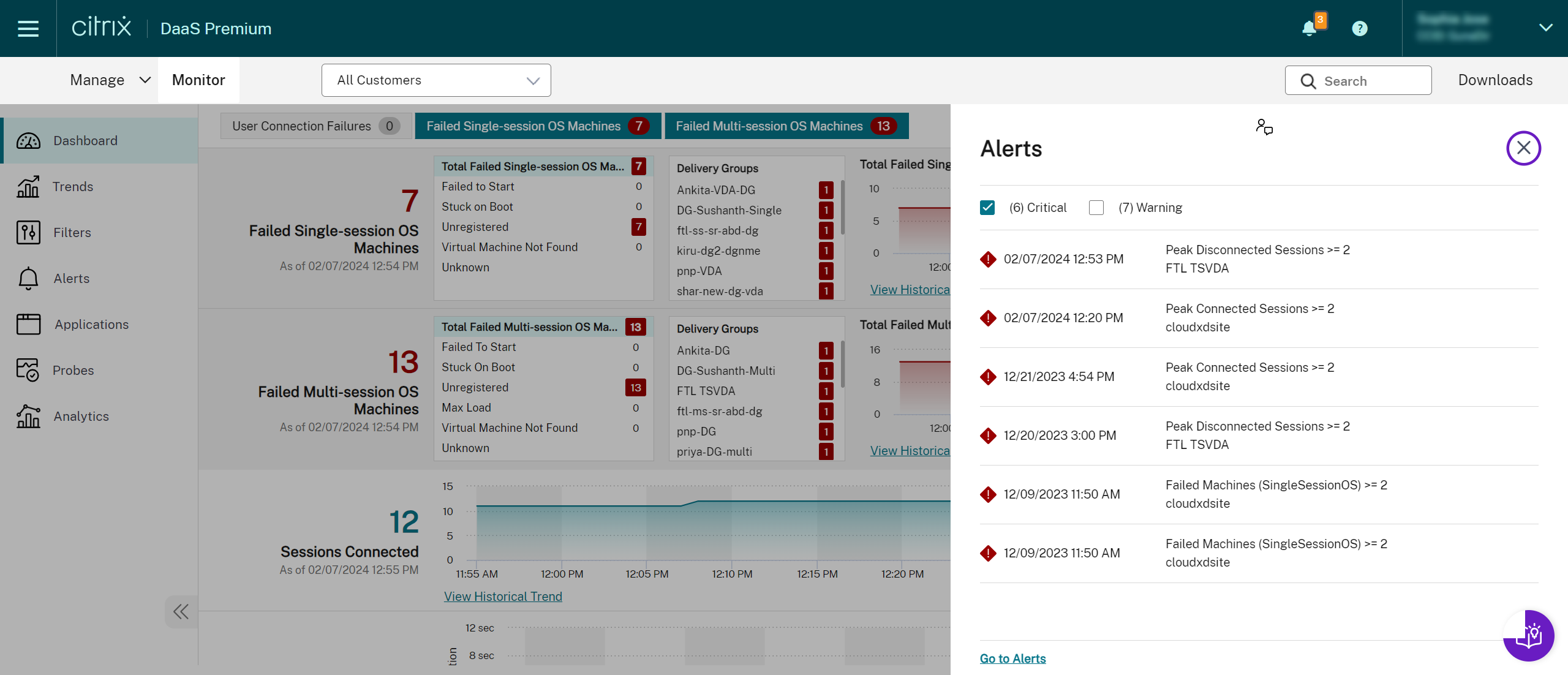
警告警报(琥珀色三角形)表示已达到或超出条件的警告阈值。
严重警报(红色圆形)表示已达到或超出条件的严重阈值。
您可以通过从侧边栏中选择警报、单击侧边栏底部的“转到警报”链接或从 Monitor 页面顶部选择“警报”来查看有关警报的更详细信息。
在警报视图中,您可以筛选和导出警报。例如,上个月特定交付组的失败多会话操作系统计算机,或特定用户的所有警报。有关详细信息,请参阅导出报告。
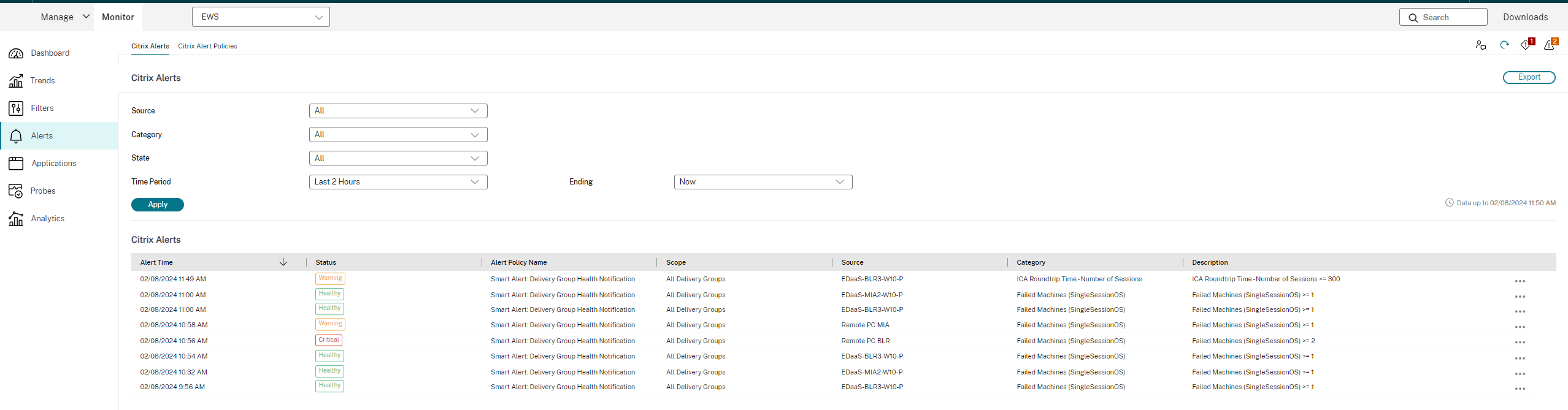
Citrix® 警报
Citrix 警报是源自 Citrix 组件的警报。您可以在 Monitor 的“警报”>“Citrix 警报策略”中配置 Citrix 警报。作为配置的一部分,您可以设置通过电子邮件向个人和组发送通知,当警报超出您设置的阈值时。有关设置 Citrix 警报的详细信息,请参阅创建警报策略。
智能警报策略
- 一组具有预定义阈值的内置警报策略适用于交付组和多会话操作系统 VDA 的范围。您可以在“警报”>“Citrix 警报策略”中修改内置警报策略的阈值参数。
- 当您的站点中定义了至少一个警报目标(一个交付组或一个多会话操作系统 VDA)时,将创建这些策略。此外,这些内置警报会自动添加到新的交付组或多会话操作系统 VDA。
仅当 Monitor 数据库中不存在相应的警报规则时才创建内置警报策略。
有关内置警报策略的阈值,请参阅警报策略条件部分。
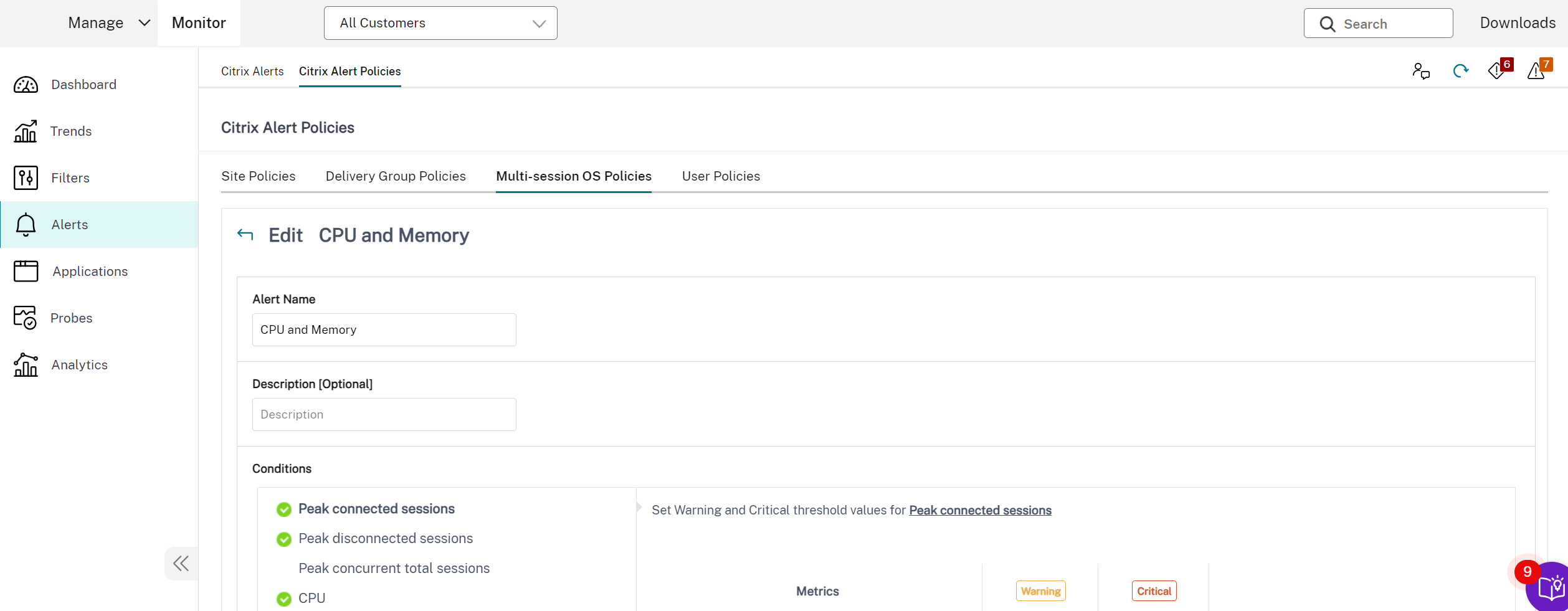
高级警报策略
- Monitor 的主动通知和警报功能已增强,以包含一个名为“**高级警报策略**”的新警报框架。借助此功能,您可以通过包含每个元素或条件的精细详细信息来创建警报,从而增强对警报范围的控制。目前,这些策略包括成本节约和基础架构警报。
- 随着高级警报策略(一种数据源驱动的警报)的引入,您可以使用多条件范围筛选。
此功能可帮助您减少过多的警报,否则可能会导致响应能力或解决重要问题的有效性降低。此策略有助于衡量警报策略的有效性和管理员的参与度。
- 您可以从“**警报**”>“**高级警报策略**”>“**创建策略**”部分创建高级警报策略。
- 您可以选择以下数据源之一:
- 计算机
- Provisioning Service
- StoreFront™
成本节约警报
- 您可以创建成本节约警报,这有助于您优化成本。目前,您可以为计算机创建警报。
- 要在计算机上创建警报,请执行以下操作:
- 单击“警报”选项卡 > “高级警报策略”。此时将显示“高级警报策略”页面。
- 单击“创建策略”。此时将显示“创建高级警报策略”部分。
- 从“数据源”下拉列表中选择“计算机”。此时将显示成本节约条件和相应的条件类型。
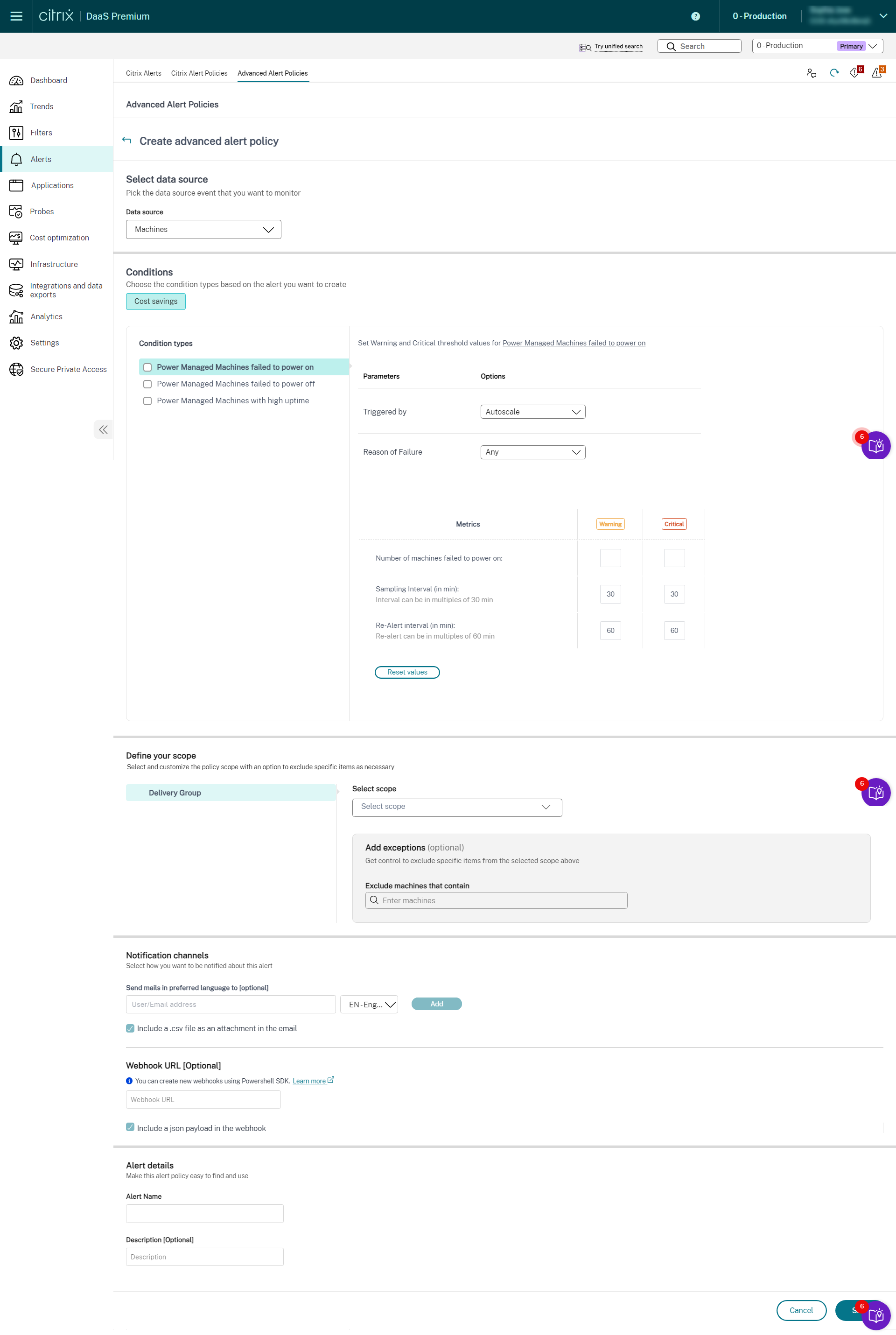
-
根据需要选择以下条件类型:
- **电源管理计算机未能开机** - **电源管理计算机未能关机** - **正常运行时间长的电源管理计算机** -
为每个选定条件选择特定参数和相应选项。 - 1. 为选定的条件类型设置警告和严重指标:
- 对于**正常运行时间长的电源管理计算机**: - 超出正常运行时间阈值的计算机数量 - 重新警报间隔(以分钟为单位),最小间隔为 60 分钟-
对于电源管理计算机未能开机和电源管理计算机未能关机:
- 超出正常运行时间阈值的计算机数量
- 采样间隔(以分钟为单位),间隔可以是 30 分钟的倍数
-
重新警报间隔(以分钟为单位),重新警报可以是 60 分钟的倍数
-
- 根据需要为选定的警报安排重新警报间隔。
-
- 定义警报的范围。
-
设置通知渠道。这可以是电子邮件或 Webhook。
-
您可以选择以下复选框:
- 在 Webhook 中包含 JSON 有效负载作为附件
- 在电子邮件中包含 CSV 文件作为附件
-
- 输入“警报详细信息”,例如“警报名称”和“描述”(可选)。 - 1. 单击“保存”。警报已创建。
配置 SPA 连接延迟警报
-
要创建 SPA 连接延迟警报,请执行以下操作:
-
- 单击“警报”选项卡 > “高级警报策略”。此时将显示“高级警报策略”页面。
-
- 单击“创建策略”。此时将显示“创建高级警报策略”部分。
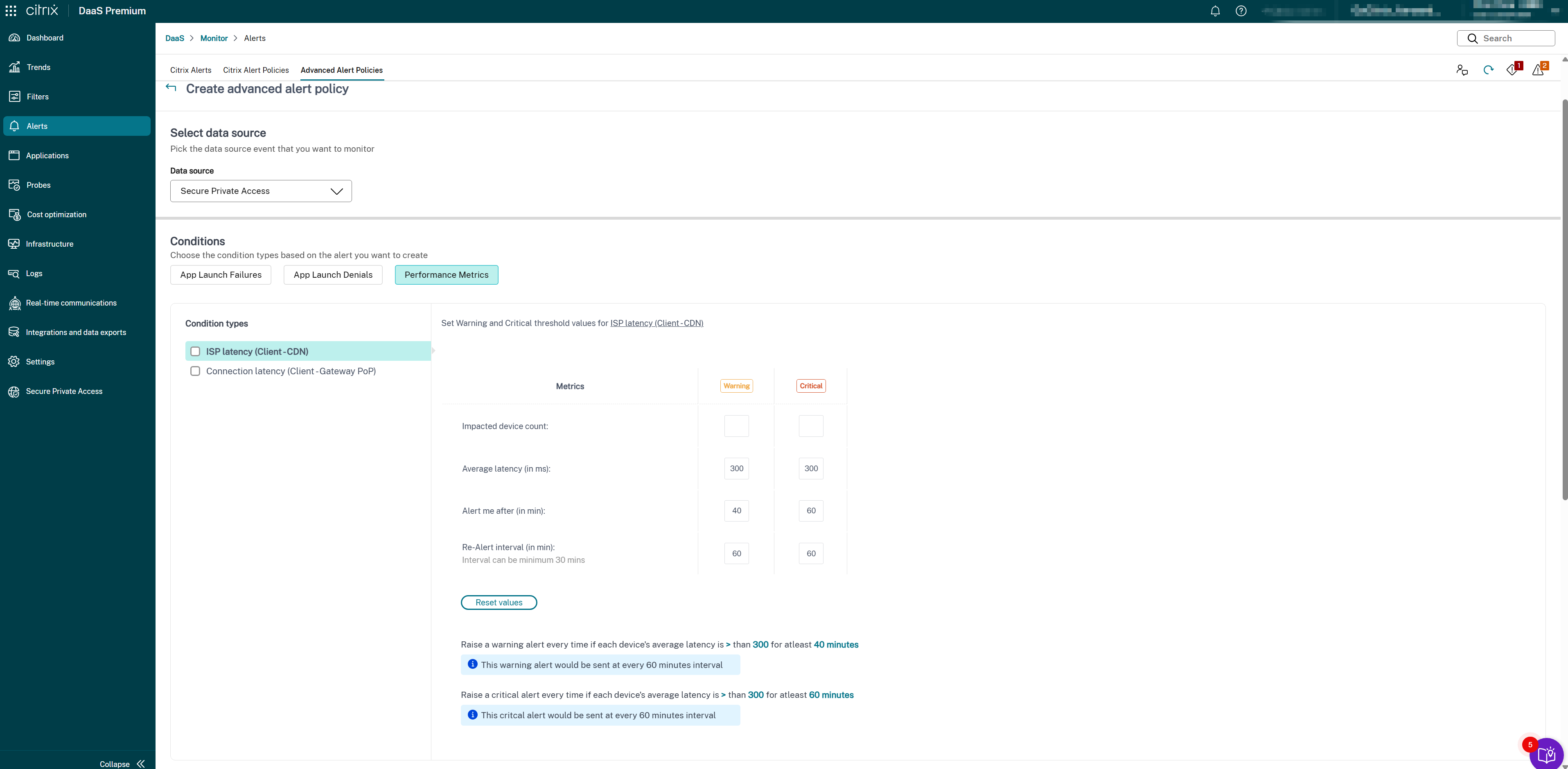
- 从“数据源”下拉列表中选择 Secure Private Access。此时将显示 SPA 连接延迟条件。
-
根据需要选择以下指标类型:
- ISP 延迟(客户端 → CDN)
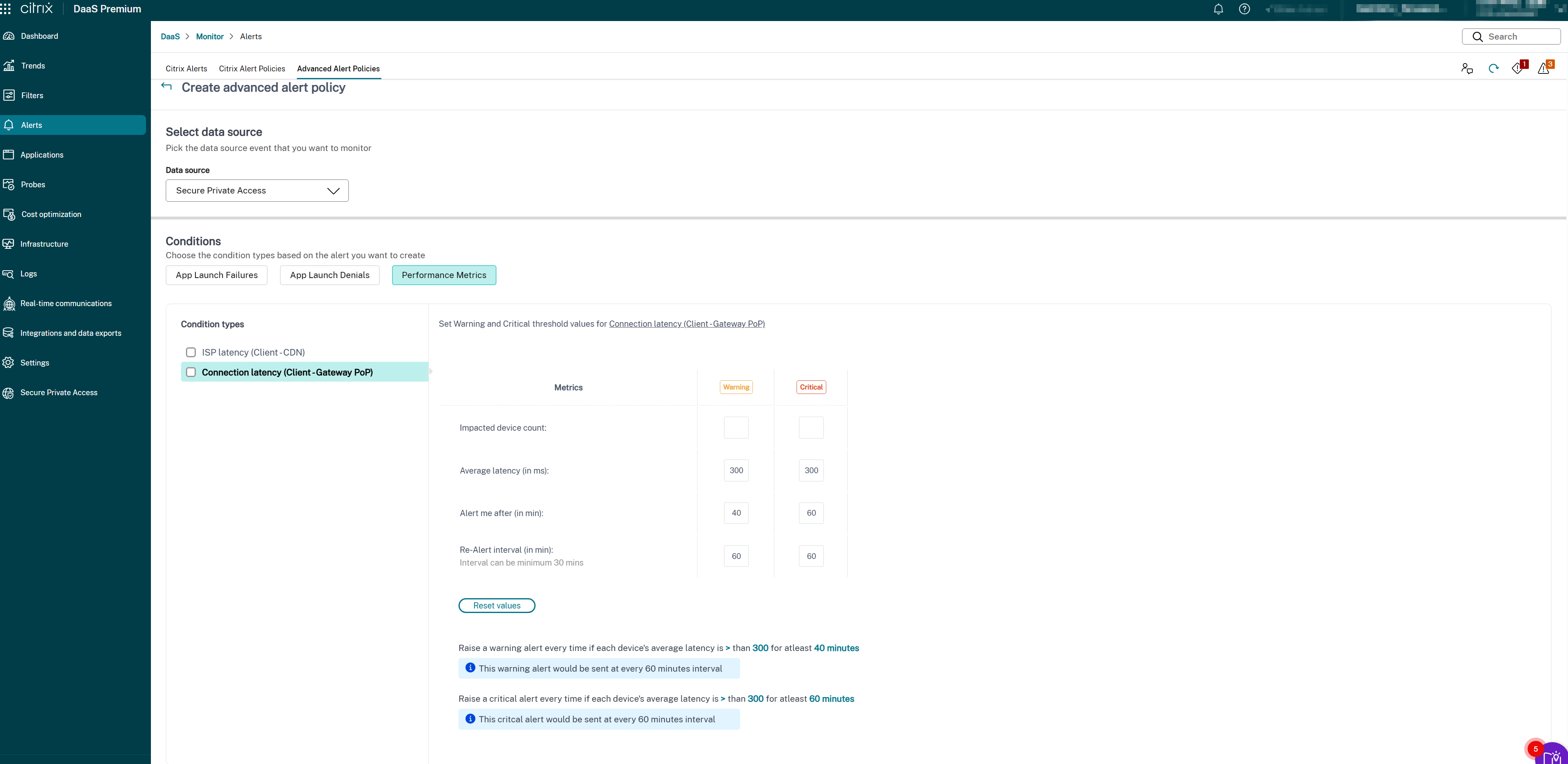
- 连接延迟(客户端 → 网关 PoP)
- ISP 延迟(客户端 → CDN)
- 连接延迟(客户端 → 网关 PoP)
- 为每个选定的指标选择特定参数和相应选项。
-
为选定的条件类型设置“警告”和“严重”指标:
- 延迟阈值(以毫秒为单位):设置“警告”(例如,150–200 毫秒)和“严重”(例如,300–400 毫秒)值
- 受影响的用户(计数):经历延迟高于阈值的用户数
- 采样间隔(以分钟为单位):评估延迟的频率(例如,5–15 分钟)
- 重新警报间隔(以分钟为单位):建议至少 60 分钟,以避免警报疲劳
- 根据需要为选定的警报安排重新警报间隔。
- 定义警报的范围。选择站点、交付组或目标子集。
-
设置通知渠道。这可以是电子邮件或 Webhook。
-
您可以选中以下复选框:
- 在 Webhook 中包含 JSON 有效负载作为附件
- 在电子邮件中包含 CSV 文件作为附件
-
- 输入“警报详细信息”,例如“警报名称”(例如,“SPA Connection Latency – PoP East”)和“描述”(可选)。
- 单击“保存”。警报已创建。
建议:
对于主动警报,请根据每个区域的基线测量值调整延迟阈值。包含 Webhook 集成,将高延迟警报路由到事件管理中,以便更快地进行分类。
基础架构策略
您可以创建警报来监视以下受支持的 Citrix DaaS™ 组件的运行状况:
- 预配服务
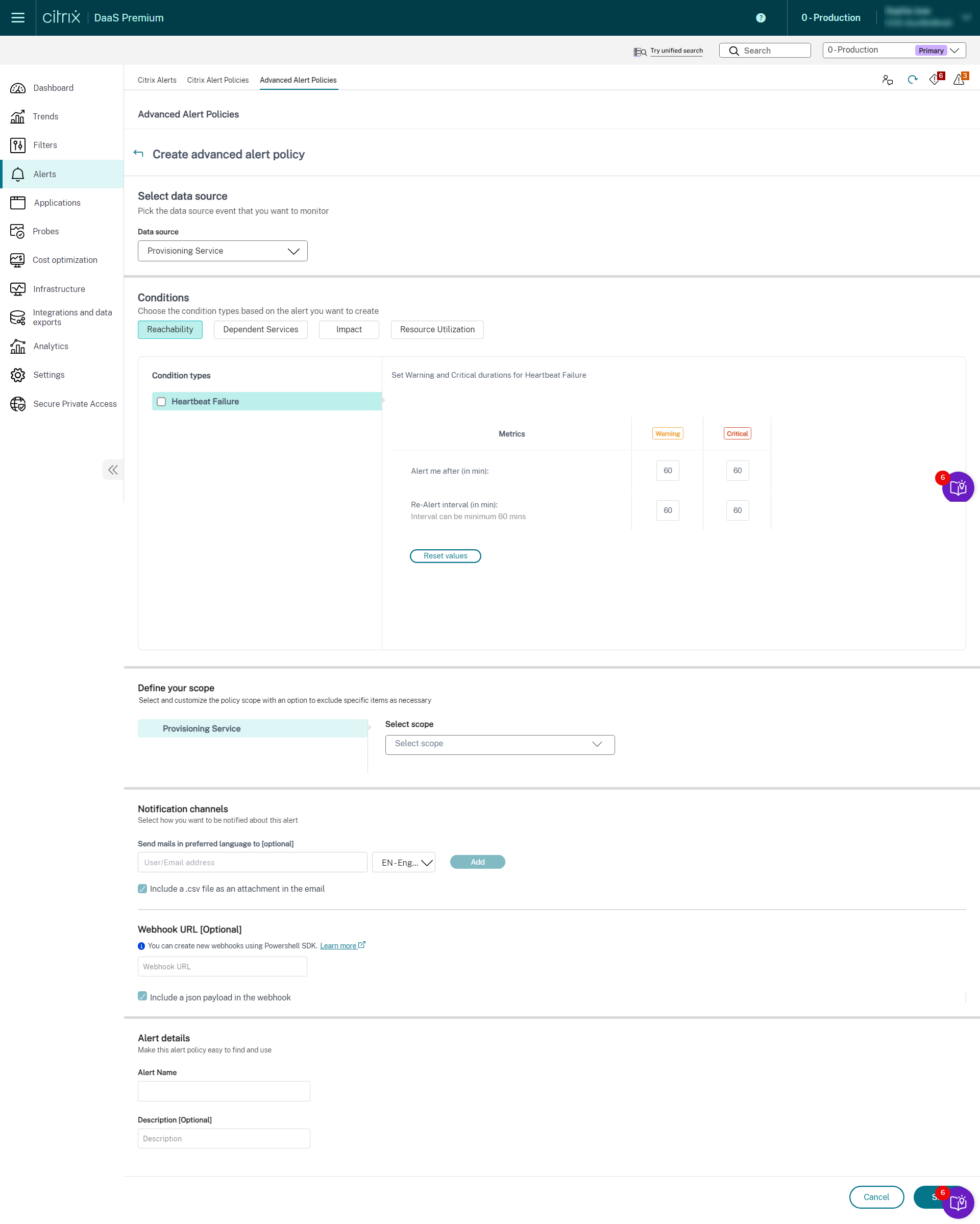
- StoreFront
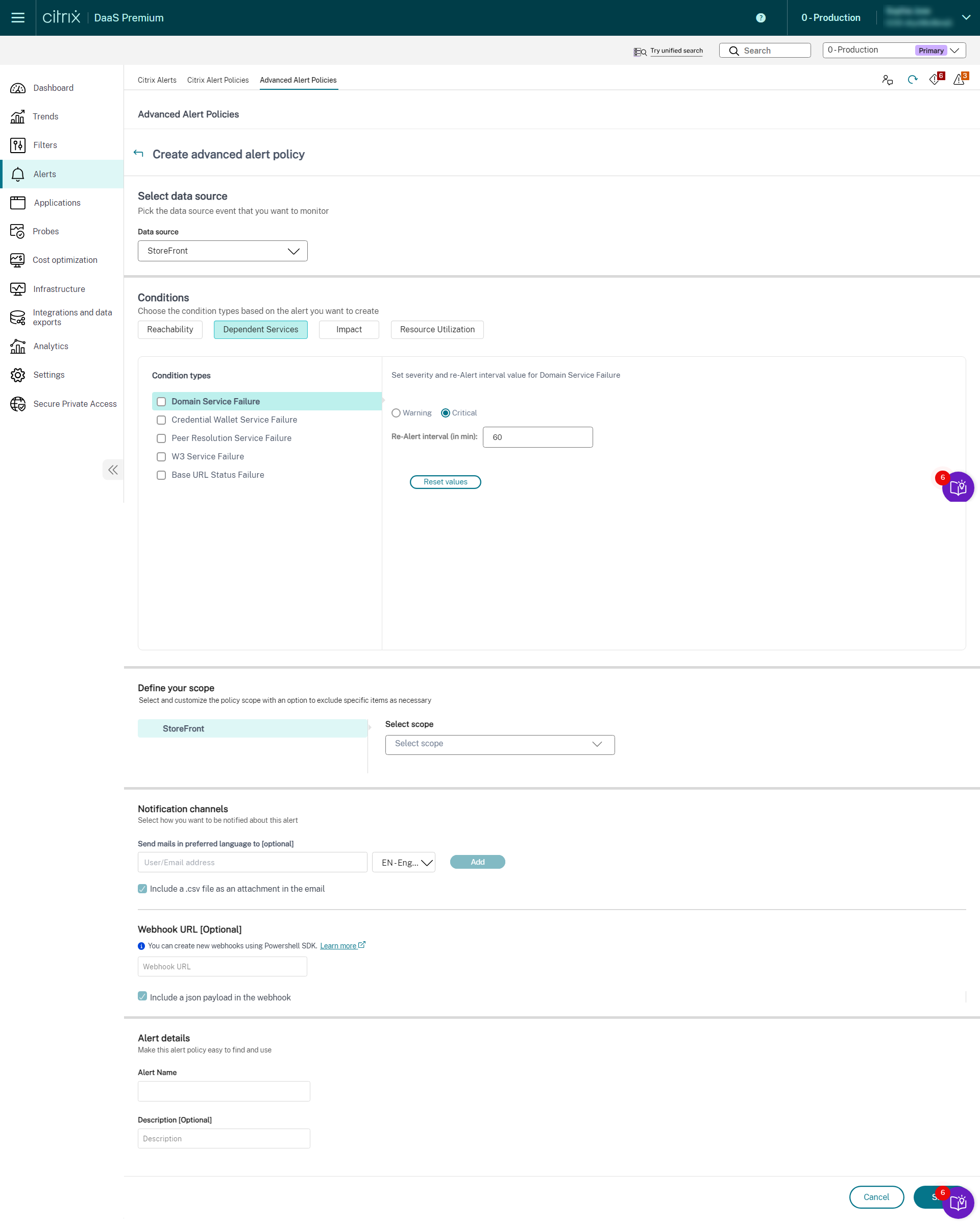
- Cloud Connector
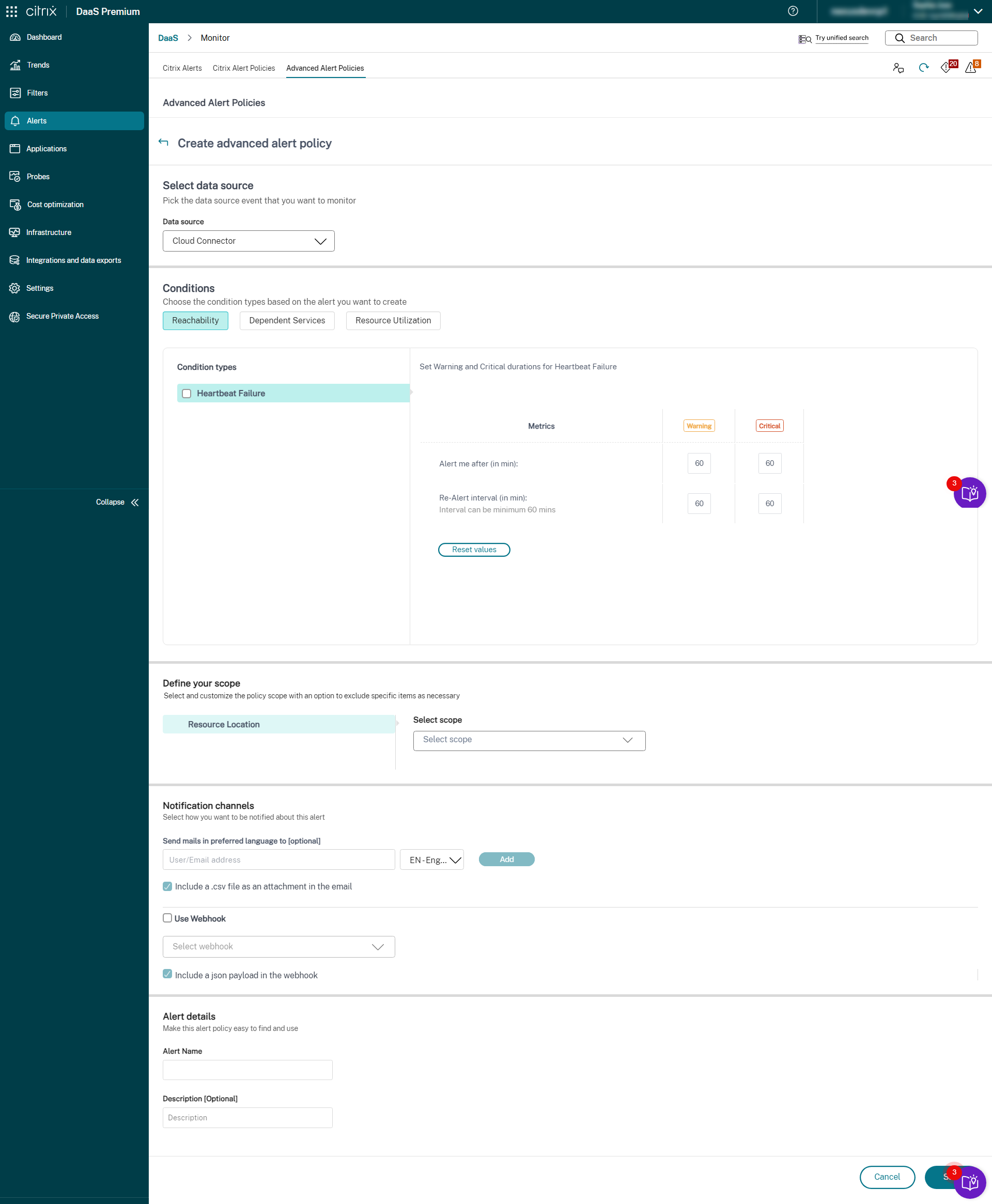
- Connector Appliance
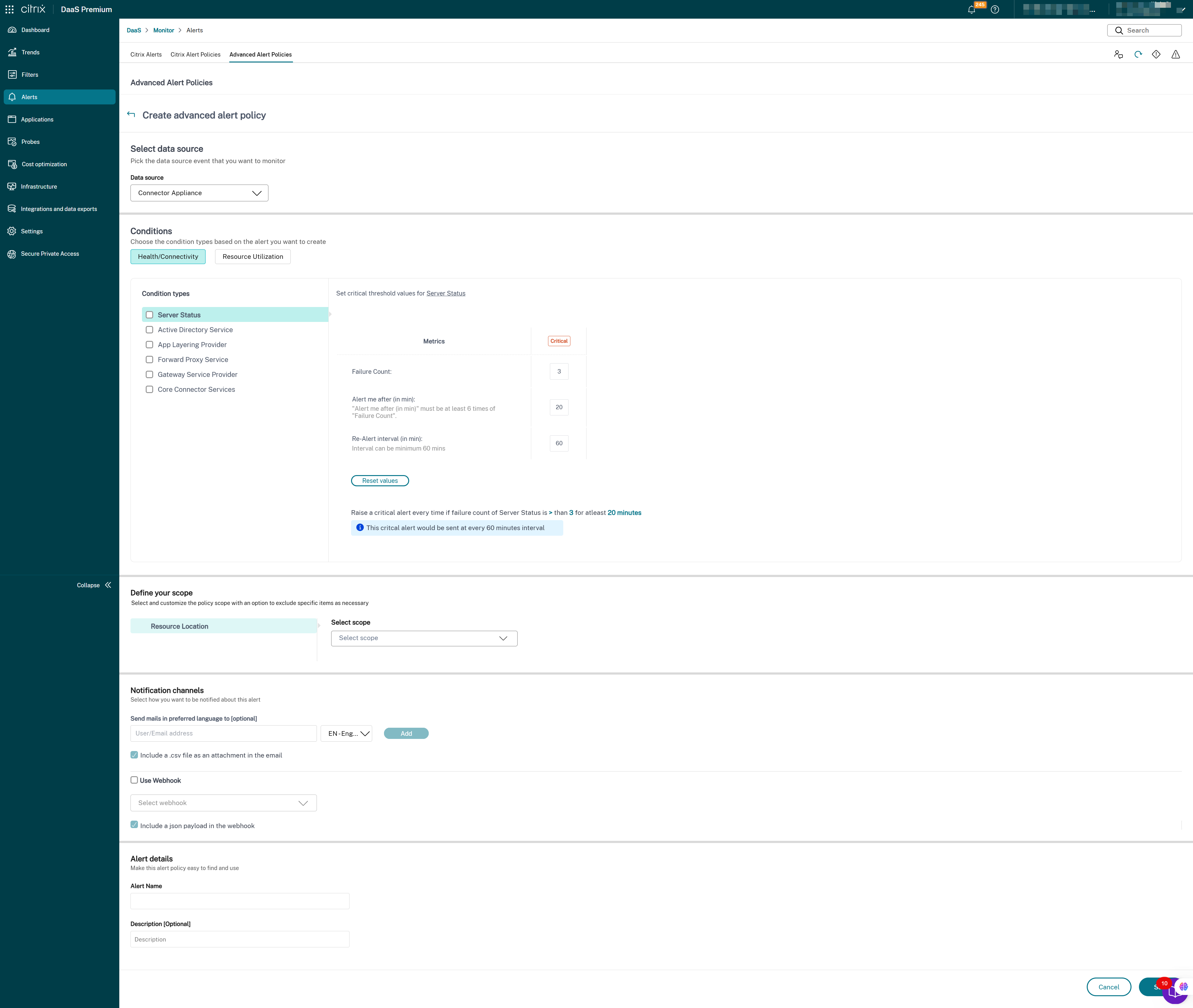
基础架构监视 设置完成后,您可以使用 Monitor 中提供的运行状况数据为任何所需组件配置警报。管理员可以设置条件、范围和通知媒介,以通过电子邮件或 Webhook 接收 JSON 有效负载来接收重要警报。触发的警报也可在“Citrix Alerts”部分中找到,以进行分析和管理。
作为新引入的基础架构策略的一部分,警报条件分为以下四个部分:
- 可达性
- 依赖服务
- 影响
- 资源利用率
每个类别中的条件都可以根据您的组织优先级设置为“严重”和“警告”级别。您还可以为这些警报安排重新警报间隔。
您可以从“警报”>“Citrix Alert Policies”部分创建基础架构策略。您可以选择所需的类别,然后为策略选择所需的条件。有关如何创建策略的详细信息,请参阅创建警报策略。策略创建后,您可以在 Citrix Alerts 页面上编辑、删除或禁用该策略。
有关每个类别和组件中支持的条件的更多详细信息,请参阅以下内容:
通过电子邮件或在 Citrix Alert 页面上收到以下警报数据:
| 字段 | 描述 |
|---|---|
| 客户 ID | 站点的客户 ID。 |
| 警报级别 | 可能的值为“严重”和“警告”。 |
| 目标 | 触发警报的计算机名称。 |
| 时间 | 触发警报的时间。 |
| 范围 | 策略的范围。 |
| 策略 | 策略的名称。 |
| 描述 | 触发警报的问题描述。 |
定义策略的范围
您可以定义警报的范围并添加例外。警报仅针对选定范围生成,使用添加例外排除的子范围不包括在警报生成中。此功能可帮助您在精细级别创建警报。
您可以通过电子邮件或 Webhook URL 创建通知。您还可以选择接收警报的首选语言。您还可以选择通过电子邮件接收 .CSV 文件附件中的警报参数,或通过 Webhook URL 接收 JSON 有效负载中的警报参数。附件包含所需参数的详细信息。有关详细信息,请参阅警报内容的增强功能。
以下数据将通过电子邮件或在 Citrix Alerts 页面上作为警报接收:
| 字段 | 描述 |
|---|---|
| 客户 ID | 站点的客户 ID。 |
| 警报级别 | 此值是为每个警报条件设置的预定义值。可能的值为“严重”和“警告”。 |
| 条件 | 此值是创建策略时设置的条件。例如,未注册计算机的数量等于或大于 20。 |
-
目标 触发警报的交付组或站点的名称。 -
站点 站点的名称。 -
范围 策略的范围。此值也包括子范围。 -
策略 策略的名称。
| 描述 | 触发警报的问题的描述。 |
用于创建警报策略的 PowerShell 脚本:
asnp Citrix.Monitor.*
# Add Parameters
$timeSpan = New-TimeSpan -Seconds 30
$alertThreshold = 1
$alarmThreshold = 2
# Add Target UID's
$targetIds = @()
$targetIds += "e9a211b4-a1f3-4f74-b6c7-85225902e997"
# Add email addresses
$emailaddress = @()
$emailaddress += "loki@abc.com"
# Create new policy
$policy = New-MonitorNotificationPolicy -Name "FailedMachinePercentageAlertCreationViaPowershell" -Description "Policy created to test urm" -Enabled $true
<!--NeedCopy-->
将以下行替换为 FailedMachinePercentage 的正确条件
Add-MonitorNotificationPolicyCondition -Uid $policy.Uid -ConditionType FailedMachinePercentage -AlertThreshold $alertThreshold -AlarmThreshold $alarmThreshold -AlertRenotification $timeSpan -AlarmRenotification $timeSpan
Add-MonitorNotificationPolicyTargets -Uid $policy.Uid -Scope "DG-Multisession" -TargetKind DesktopGroup -TargetIds $targetIds
$policy = Get-MonitorNotificationPolicy -Uid $policy.Uid
$policy
<!--NeedCopy-->
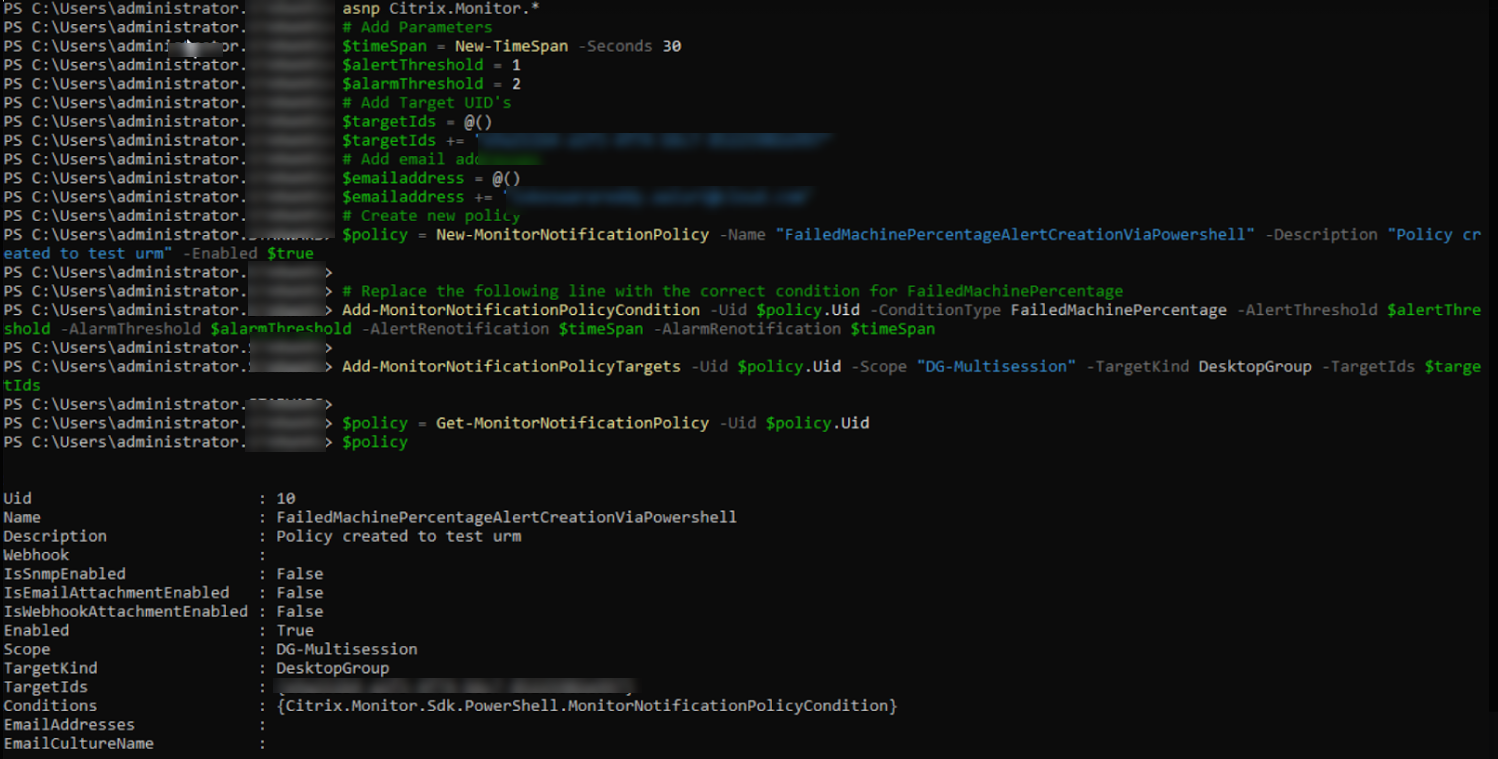
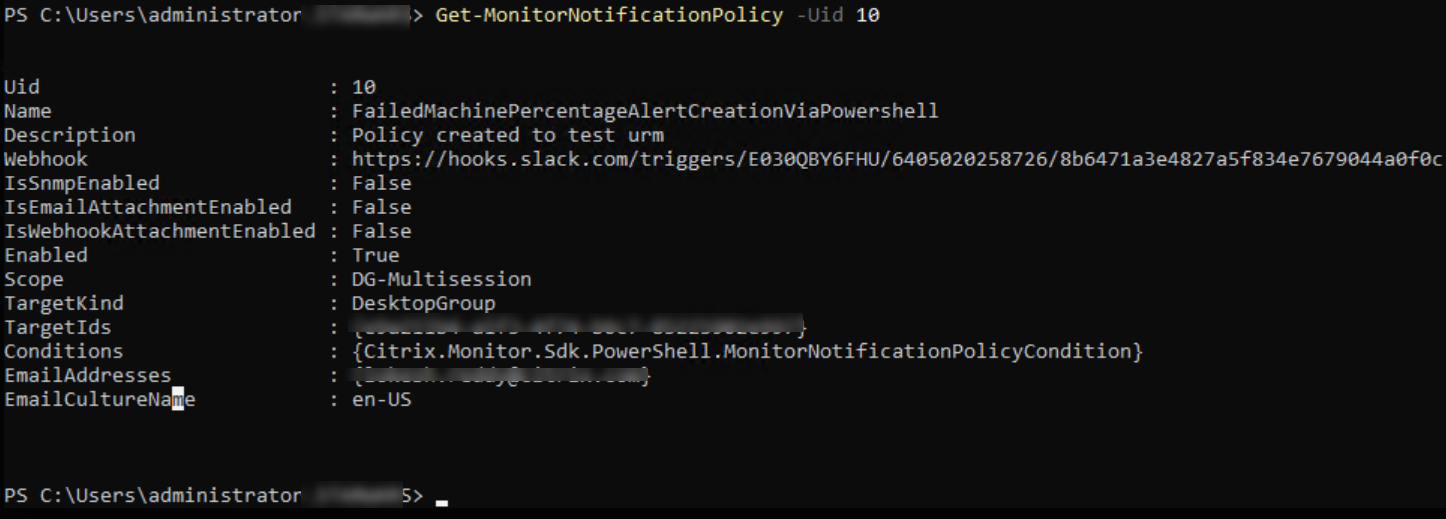
从上图中,您可以看到策略已创建,并且 Uid 为 10。
将电子邮件添加到配置
Set-MonitorNotificationEmailServerConfiguration -ProtocolType SMTP -ServerName NameOfTheSMTPServerOrIPAddress -PortNumber 80 -SenderEmailAddress loki@abc.com -RequiresAuthentication 0
<!--NeedCopy-->
将电子邮件添加到策略
Add-MonitorNotificationPolicyEmailAddresses -Uid $policy.Uid -EmailAddresses $emailaddress -EmailCultureName "en-US"
<!--NeedCopy-->
- **添加电子邮件的示例脚本:**
- Add-MonitorNotificationPolicyEmailAddresses -Uid 10 -EmailAddresses $emailaddress -EmailCultureName "en-US"
<!--NeedCopy-->

将 Webhook URL 添加到策略
- Set-MonitorNotificationPolicy –Uid $polcy.Uid –Webhook 'URL'
<!--NeedCopy-->

添加 Webhook URL 的示例脚本:
Set-MonitorNotificationPolicy –Uid 10 –Webhook 'https://hooks.slack.com/triggers/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'
<!--NeedCopy-->
Get-MonitorNotificationPolicy -Uid 10
<!--NeedCopy-->
创建警报策略
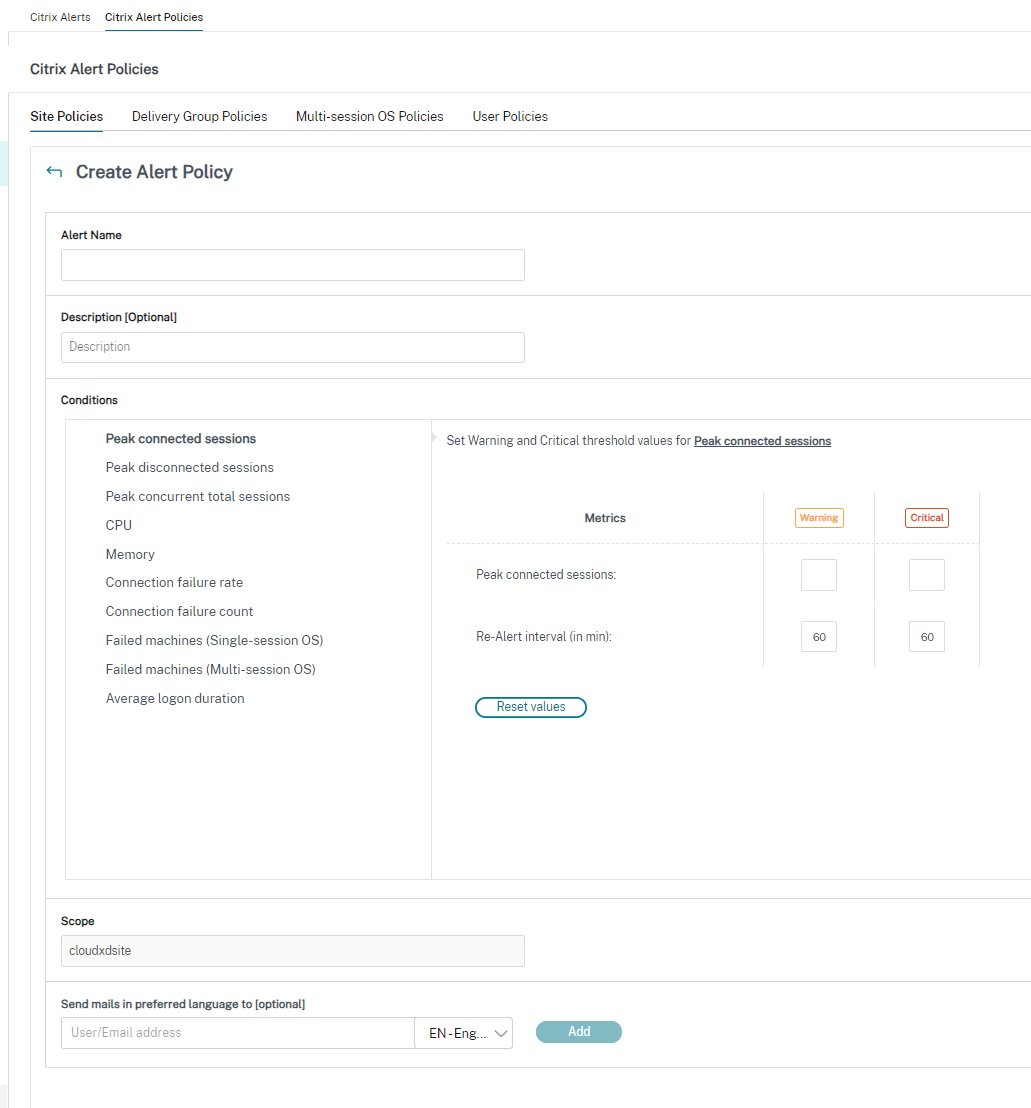
- 要创建警报策略,例如,在满足特定会话计数条件集时生成警报:
- 转到警报 > Citrix 警报策略,然后选择(例如)多会话操作系统策略。
- 单击创建。
-
- 命名并描述策略,然后设置触发警报必须满足的条件。例如,为“峰值连接会话”、“峰值断开连接会话”和“峰值并发总会话”指定警告和严重计数。警告值不得大于严重值。有关详细信息,请参阅警报策略条件。
-
- 设置重新警报间隔。如果警报条件仍然满足,则警报将在此时间间隔再次触发,并且(如果已在警报策略中设置)将生成电子邮件通知。已解除的警报不会在重新警报间隔生成电子邮件通知。
- 设置范围。例如,为特定的交付组设置。
- 在“通知首选项”中,指定警报触发时应通过电子邮件通知谁。电子邮件通知通过 SendGrid 发送。请确保在您的电子邮件设置中将电子邮件地址
donotreplynotifications@citrix.com列入白名单。
-
- 单击保存。
创建在“范围”中定义了 20 个或更多交付组的策略可能需要大约 30 秒才能完成配置。在此期间会显示一个旋转图标。
- 为多达 20 个唯一交付组(总共 1000 个交付组目标)创建 50 个以上的策略可能会导致响应时间增加(超过 5 秒)。
将包含活动会话的计算机从一个交付组移动到另一个交付组可能会触发使用计算机参数定义的错误交付组警报。
- >**注意:** > >删除警报策略后,策略生成的警报通知可能需要长达 30 分钟才能停止。
Monitor 的警报功能已增强,可包含 CSV 附件和 JSON 有效负载。通过此增强功能,您可以通过电子邮件以 CSV 附件形式或在存在 Webhook 时以 JSON 有效负载形式获取警报详细信息。使用此 CSV 附件或 JSON 有效负载,您可以接收详细级别的丰富内容,从而有助于快速识别和解决问题。
目前,此增强功能仅适用于以下警报:
- 计算机正常运行时间
- 电源开启操作失败
- 电源关闭操作失败
-
未注册计算机 (%)
-
要使用此功能,请导航到警报并选择以下复选框:
-
- 在 Webhook 中包含 JSON 有效负载作为附件
- 在电子邮件中包含 CSV 文件作为附件
以下是 Citrix 警报策略部分的屏幕截图:
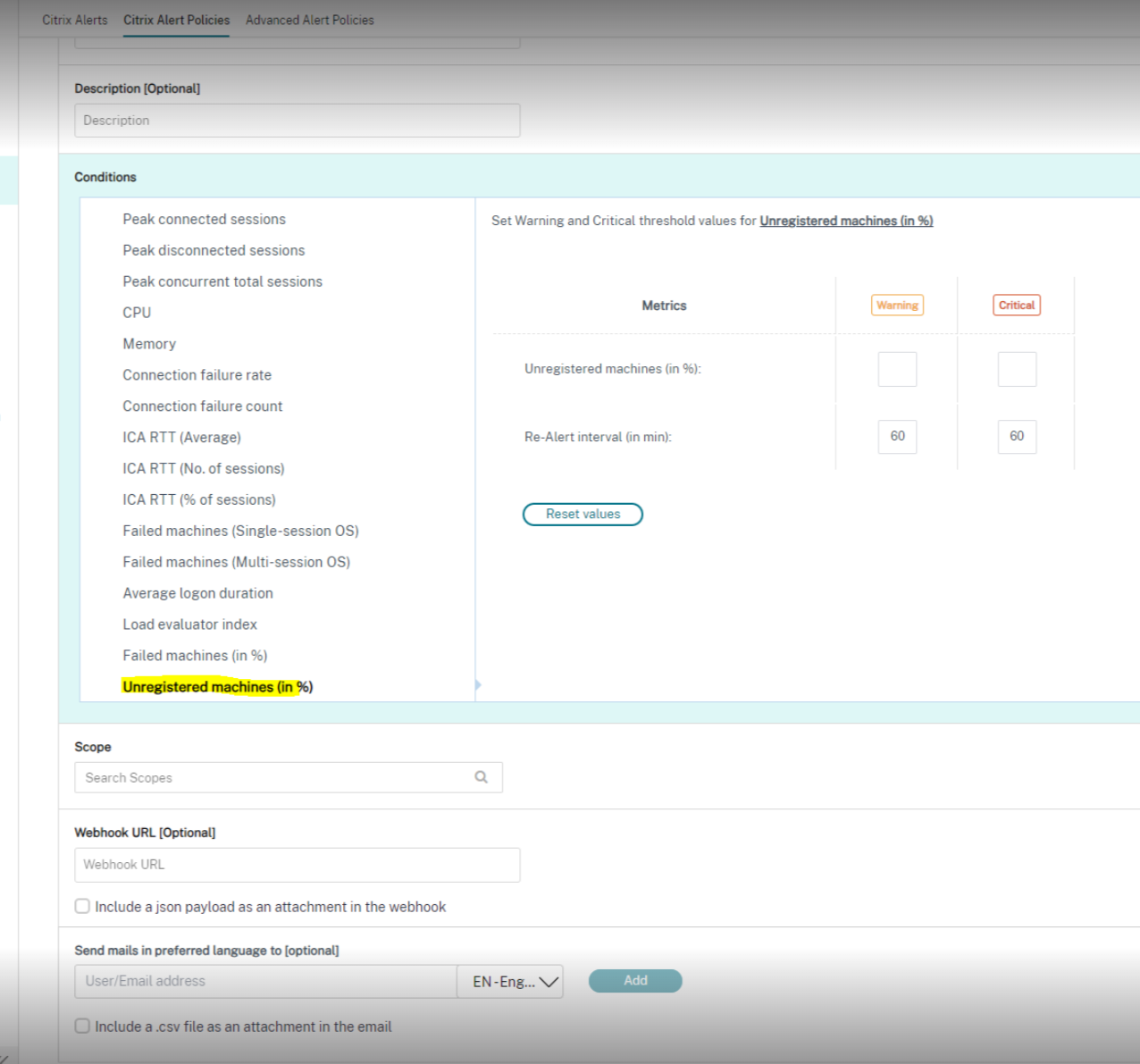
以下是 高级警报策略部分的屏幕截图:
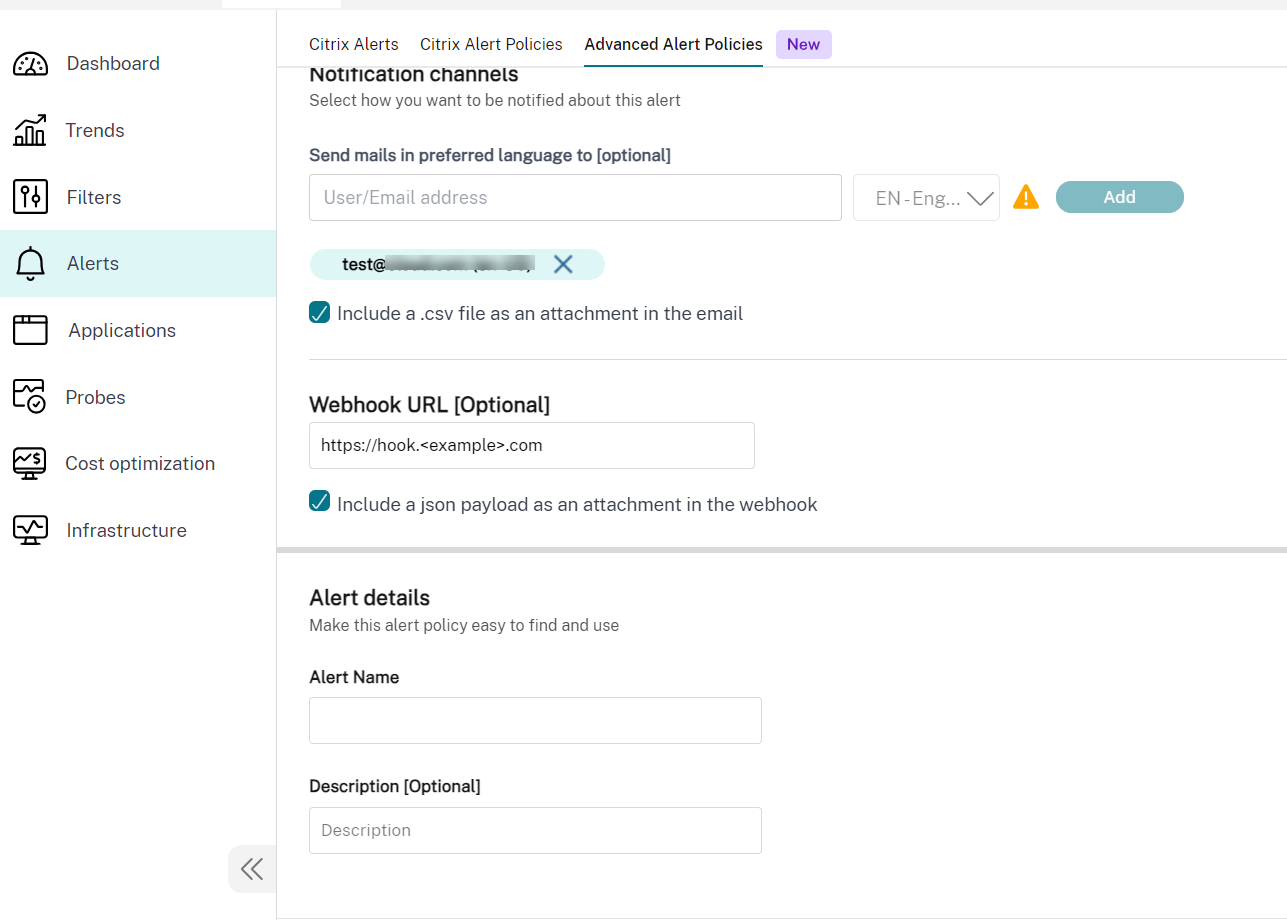
CSV 附件
下表提供了所有受支持警报的 .CSV 附件的列:
| 列 | 适用警报 |
|---|---|
| 计算机名称、IP 地址和交付组名称 | 计算机正常运行时间、关机操作失败和开机操作失败,以及未注册计算机 (%) |
| 当前注册状态、失败日期、故障状态和生命周期状态 | 未注册计算机 (%) |
| 上次电源操作失败原因、上次电源操作触发者、上次电源操作类型和上次电源操作完成日期 | 关机操作失败和开机操作失败 |
- |电源状态、开机日期和总正常运行时间(分钟)|计算机正常运行时间|
Webhook 有效负载
{
"text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Unregistered machines (in %)\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"CurrentRegistrationState\":\"Unregistered\",\"FailureDate\":\"<Date of Failure>\",\"FaultState\":\"<Fault State of the Machine>\",\"LifecycleState\":\"<Lifecycle state of the Machine>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"CurrentRegistrationState\":\"Unregistered\",\"FailureDate\":\"<Date of Failure>\",\"FaultState\":\"<Fault State of the Machine>\",\"LifecycleState\":\"<Lifecycle state of the Machine>\"}]}"
}
<!--NeedCopy-->
开机操作失败警报
- {
- "text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Failure To PowerOn Action\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure, HypervisorRateLimitExceeded, UnknownError, Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User, Administrator, Auto-Scale, Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure, HypervisorRateLimitExceeded, UnknownError, Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User, Administrator, Auto-Scale, Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"}]}"
}
<!--NeedCopy-->
关机操作失败警报
- {
- "text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Failure To PowerOff Action\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IPV4 Address of the Machine>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure,HypervisorRateLimitExceeded,UnknownError,Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User,Administrator,Auto-Scale,Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IPV4 Address of the Machine>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure,HypervisorRateLimitExceeded,UnknownError,Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User,Administrator,Auto-Scale,Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"}]}"
}
<!--NeedCopy-->
计算机正常运行时间警报
{
"text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Machine Uptime Alert\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"PowerState\":\"<On/Off>\",\"PoweredOnDate\":\"2024-05-15T15:04:27.723\",\"TotalUptimeInMinutes\":180},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"PowerState\":\"<ON/OFF>\",\"PoweredOnDate\":\"2024-05-15T15:04:27.723\",\"TotalUptimeInMinutes\":\"<Uptime Duration>\"}]}"
}
<!--NeedCopy-->
警报策略条件
以下是警报类别、建议的警报缓解措施以及(如果已定义)内置策略条件。内置警报策略的警报和重新警报间隔为 60 分钟。
峰值连接会话数
- 检查“监视会话趋势”视图以了解峰值连接会话数。
- 检查以确保有足够的容量来适应会话负载。
- 如果需要,添加新计算机。
峰值断开连接会话数
- 检查“监视会话趋势”视图以了解峰值断开连接会话数。
- 检查以确保有足够的容量来适应会话负载。
- 如果需要,添加新计算机。
- 如果需要,注销断开连接的会话。
峰值并发总会话数
- 在“监视”中的“监视会话趋势”视图中检查峰值并发会话数。
- 检查以确保有足够的容量来适应会话负载。
- 如果需要,添加新计算机。
- 如果需要,注销断开连接的会话。
CPU
-
CPU 使用率百分比表示 VDA 上的整体 CPU 消耗,包括进程的 CPU 消耗。您可以从相应 VDA 的计算机详细信息页面获取有关单个进程 CPU 利用率的更多信息。
- 转到计算机详细信息 > 查看历史利用率 > 前 10 个进程,识别消耗 CPU 的进程。确保已启用进程监视策略以启动进程级别资源使用情况统计信息的收集。
- 如有必要,结束进程。
- 结束进程会导致未保存的数据丢失。
- 如果一切正常,将来请添加更多 CPU 资源。
注意: > > 策略设置启用资源监视默认情况下允许监视具有 VDA 的计算机上的 CPU 和内存性能计数器。如果禁用此策略设置,则不会触发具有 CPU 和内存条件的警报。有关详细信息,请参阅监视策略设置。
**智能策略条件:**
- **范围:** 交付组、多会话操作系统范围
- **阈值:** 警告 - 80%,严重 - 90%
内存
- 内存使用率百分比表示 VDA 上的整体内存消耗,包括进程的内存消耗。您可以从相应 VDA 的**计算机详细信息**页面获取有关单个进程内存使用情况的更多信息。
- 转到**计算机详细信息 > 查看历史利用率 > 前 10 个进程**,识别消耗内存的进程。确保已启用进程监视策略以启动进程级别资源使用情况统计信息的收集。
- 如有必要,结束进程。
- 结束进程会导致未保存的数据丢失。
- 如果一切正常,将来请添加更多内存。
> **注意:**
>
> 策略设置**启用资源监视**默认情况下允许监视具有 VDA 的计算机上的 CPU 和内存性能计数器。如果禁用此策略设置,则不会触发具有 CPU 和内存条件的警报。有关详细信息,请参阅[监视策略设置](/zh-cn/citrix-virtual-apps-desktops/policies/reference/virtual-delivery-agent-policy-settings/monitoring-policy-settings.html)。
**智能策略条件:**
- **范围:** 交付组、多会话操作系统范围
- **阈值:** 警告 - 80%,严重 - 90%
连接失败率
过去一小时的连接失败百分比。
- 基于总连接尝试次数中的总失败次数计算。
- 检查“监视连接失败趋势”视图,查看从配置日志记录的事件。
- 确定应用程序或桌面是否可访问。
连接失败计数
过去一小时内的连接失败次数。
- 检查“监视连接失败趋势”视图,查看从配置日志记录的事件。
- 确定应用程序或桌面是否可访问。
ICA® RTT(平均值)
平均 ICA 往返时间。
- 检查 Citrix ADM 以获取 ICA RTT 的详细信息,从而确定根本原因。有关详细信息,请参阅 Citrix ADM 文档。
- 如果 Citrix ADM 不可用,请检查“监视用户详细信息”视图以获取 ICA RTT 和延迟,并确定是网络问题还是应用程序或桌面问题。
ICA RTT(会话数)
超过阈值 ICA 往返时间的会话数。
- 检查 Citrix ADM 以获取高 ICA RTT 的会话数。有关详细信息,请参阅 Citrix ADM 文档。
-
如果 Citrix ADM 不可用,请联系网络团队以确定根本原因。
智能策略条件:
- 范围: 交付组、多会话操作系统范围
- 阈值: 警告 - 5 个或更多会话的 300 毫秒,严重 - 10 个或更多会话的 400 毫秒
ICA RTT(会话百分比)
超过平均 ICA 往返时间的会话百分比。
- 检查 Citrix ADM 以获取高 ICA RTT 的会话数。有关详细信息,请参阅 Citrix ADM 文档。
- 如果 Citrix ADM 不可用,请联系网络团队以确定根本原因。
ICA RTT(用户)
应用于指定用户启动的会话的 ICA 往返时间。如果至少一个会话中的 ICA RTT 大于阈值,则会触发警报。
失败的计算机(单会话操作系统)
失败的单会话操作系统计算机数量。失败可能由于各种原因而发生,如“监视仪表板”和“筛选器”视图中所示。
-
运行 Citrix Scout 诊断以确定根本原因。有关详细信息,请参阅排查用户问题。
智能策略条件:
- 范围: 交付组范围
- 阈值: 警告 - 1,严重 - 2
失败的计算机(多会话操作系统)
失败的多会话操作系统计算机数量。失败可能由于各种原因而发生,如“监视仪表板”和“筛选器”视图中所示。
-
运行 Citrix Scout 诊断以确定根本原因。
智能策略条件:
- 范围: 交付组、多会话操作系统范围
- 阈值: 警告 - 1,严重 - 2
失败的计算机(百分比)
交付组中失败的单会话和多会话操作系统计算机的百分比,根据失败计算机的数量计算。此警报条件允许您将警报阈值配置为交付组中失败计算机的百分比,并每 30 秒计算一次。 失败可能由于各种原因而发生,如“监视仪表板”和“筛选器”视图中所示。运行 Citrix Scout 诊断以确定根本原因。有关详细信息,请参阅排查用户问题。
失败的开机操作和失败的关机操作
交付组中失败的开机操作次数和失败的关机操作次数,根据未能开机或关机的电源管理计算机数量计算。此警报条件允许您将警报阈值配置为交付组中未能开机或关机的电源管理计算机数量,并每 30 分钟计算一次。
管理员可以在高级警报策略中为这些警报配置以下参数:
- 触发者:触发电源操作的原因
- 失败原因:操作失败的原因
- 阈值:触发策略的失败电源操作的计算机阈值数量
- 采样间隔:检查失败电源操作的间隔
- 重新警报间隔:警报必须重新发送的时间间隔
失败可能由于各种原因而发生,如“监视仪表板”和“筛选器”视图中所示。运行 Citrix Scout 诊断以确定根本原因。有关详细信息,请参阅排查用户问题。
未注册的计算机(百分比)
当计算机因重新启动而变得不稳定,或者交付控制器™与虚拟机之间存在通信问题时,该计算机被视为未注册。未注册的计算机(百分比)是交付组中未注册的单会话和多会话操作系统计算机的百分比,根据未注册计算机的数量计算。此警报条件允许您将警告和严重阈值配置为交付组中未注册计算机的百分比。您可以设置重新警报的间隔。您还可以添加电子邮件,以便在满足未注册的计算机(百分比)条件时收到通知。当超过严重或警告阈值时,将生成警报和电子邮件。您可以在Citrix 警报下查看警报。您可以按未注册的计算机(百分比)类别以及所需的状态和时间进行筛选。
注意:
严重值必须大于警告值。
策略条件:
- 范围:单会话操作系统和多会话操作系统交付组
- 阈值:警告和严重
计算机正常运行时间警报
交付组中计算机的正常运行时间是根据交付组中已开启的计算机每天、每周或每月的小时数计算的。此警报条件允许您将警报阈值配置为交付组中计算机的开启小时数。计算机正常运行时间警报在以下情况下工作方式如下:
- 每天的小时数 - 您可以指定计算机每天开启的小时数,该值每 30 分钟计算一次。您可以设置的最大每天小时数为 24 小时。
- 每周的小时数 - 您可以指定计算机每周开启的小时数,该值每六小时计算一次。您可以设置的最大每周小时数为 168 小时。
- 每月的小时数 - 您可以指定计算机每月开启的小时数,该值每天计算一次。最大每月小时数为 720 小时。
您可以设置的最小重新警报间隔值为 60 分钟。您可以在“警告和严重警报”部分下输入超出计算机正常运行时间阈值的计算机数量。您还可以为任何计算机添加例外。
例如,如果为此警报添加了五个交付组,并且在第一个交付组和第四个交付组中,计算机数量超出了警告或严重阈值,则警报将针对第一个交付组和第四个交付组单独触发。
此警报可帮助管理员分析计算机的正常运行时间,并根据此分析帮助管理员优化成本。您还可以通过电子邮件中的 CSV 附件或在 Webhook 的情况下通过 JSON 有效负载接收警报详细信息。
平均登录持续时间
-
过去一小时内发生的登录的平均登录持续时间。
- 检查 Monitor 控制板以获取有关登录持续时间的最新指标。短时间内大量用户登录可能会增加登录持续时间。
-
检查登录的基线和细分以缩小原因范围。有关详细信息,请参阅诊断用户登录问题。
智能策略条件:
- 范围: 交付组、多会话操作系统范围
- 阈值: 警告 - 45 秒,严重 - 60 秒
登录持续时间(用户)
过去一小时内发生的指定用户的登录持续时间。
负载评估器指数
过去 5 分钟内的负载评估器指数值。
-
检查 Monitor 中的多会话操作系统计算机,这些计算机可能具有峰值负载(最大负载)。查看控制板(故障)和趋势负载评估器指数报告。
智能策略条件:
- 范围: 交付组、多会话操作系统范围
- 阈值: 警告 - 80%,严重 - 90%
使用 Webhook 配置警报策略
除了电子邮件通知之外,您还可以使用 Webhook 配置警报策略。
注意: 此功能需要交付控制器 7.11 或更高版本。
您可以使用 PowerShell cmdlet 配置带有 HTTP 回调或 HTTP POST 的警报策略。它们已扩展以支持 Webhook。
有关创建新的 Octoblu 工作流和获取相应的 Webhook URL 的信息,请参阅 Octoblu 开发人员中心。
要为新的警报策略或现有策略配置 Webhook URL,请使用以下 PowerShell cmdlet。
使用 Webhook URL 创建警报策略:
$policy = New-MonitorNotificationPolicy -Name <Policy name> -Description <Policy description> -Enabled $true -Webhook <Webhook URL>
<!--NeedCopy-->
将 Webhook URL 添加到现有警报策略:
Set-MonitorNotificationPolicy - Uid <Policy id> -Webhook <Webhook URL>
<!--NeedCopy-->
有关 PowerShell 命令的帮助,请使用 PowerShell 帮助,例如:
Get-Help <Set-MonitorNotificationPolicy>
<!--NeedCopy-->
从警报策略生成的通知会通过 POST 调用触发 Webhook。POST 消息包含 JSON 格式的通知信息:
{"NotificationId" : \<Notification Id\>,
"Target" : \<Notification Target Id\>,
"Condition" : \<Condition that was violated\>,
"Value" : \<Threshold value for the Condition\>,
"Timestamp": \<Time in UTC when notification was generated\>,
"PolicyName": \<Name of the Alert policy\>,
"Description": \<Description of the Alert policy\>,
"Scope" : \<Scope of the Alert policy\>,
"NotificationState": \<Notification state critical, warning, healthy or dismissed\>,
"Site" : \<Site name\>}
<!--NeedCopy-->
使用 ServiceNow 配置警报策略
您可以配置警报策略以直接向 ServiceNow (SNOW) 发送通知,从而实现与您的 IT 服务管理 (ITSM) 工作流的无缝集成。此集成允许 Citrix Monitor 中生成的警报自动转发到 ServiceNow,以进行集中跟踪、升级和事件解决。
ServiceNow 集成的优势
- 统一警报管理:直接在 Citrix Monitor 界面中创建、更新和管理 ServiceNow 事件,无需在系统之间切换。
- 自动 ITSM 配置:Monitor 自动检索所需的 ServiceNow 配置(例如 Webhook URL),从而减少手动设置的复杂性。
- 简化事件响应:警报会转发到 ServiceNow,以进行集中事件跟踪和解决,从而提高运营效率。
先决条件
在配置 ServiceNow 集成之前,请确保以下各项:
- ServiceNow 实例已在 ITSM 适配器服务中配置。
- 您拥有在 Monitor 中管理警报策略的必要权限。
检查 ServiceNow 集成状态
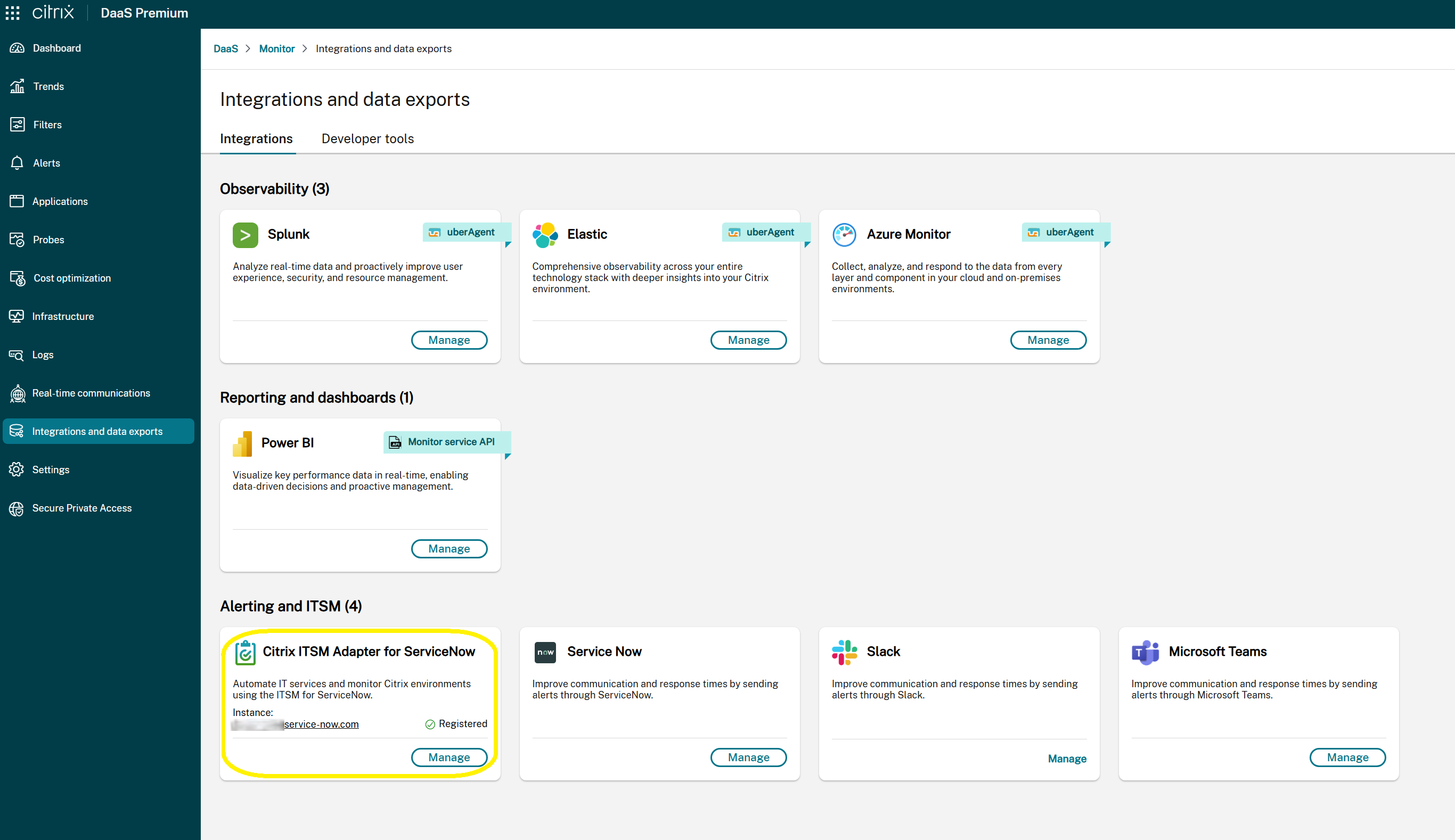
您可以在监视器 > 集成和数据导出页面上查看与 ITSM Adapter 服务的集成状态。此页面显示:
- 当前集成状态:
- 开始:表示 ITSM Adapter 集成尚未配置。选择此选项可开始初始设置过程。
- 管理:表示 ITSM Adapter 集成处于活动状态并正在运行。选择此选项可查看或修改您的 ServiceNow 集成设置。
- 关联的 ServiceNow 实例 URL(仅当在 ITSM Adapter 中配置了 ServiceNow 实例时可见)。
配置使用 ServiceNow 通知的警报策略
要配置警报策略以向 ServiceNow 发送通知,请执行以下操作:
- 转到警报 > Citrix 警报策略,然后选择策略类别(例如,多会话操作系统策略)。
- 单击创建以创建新策略,或选择现有策略并单击编辑。
- 根据需要配置策略条件。
-
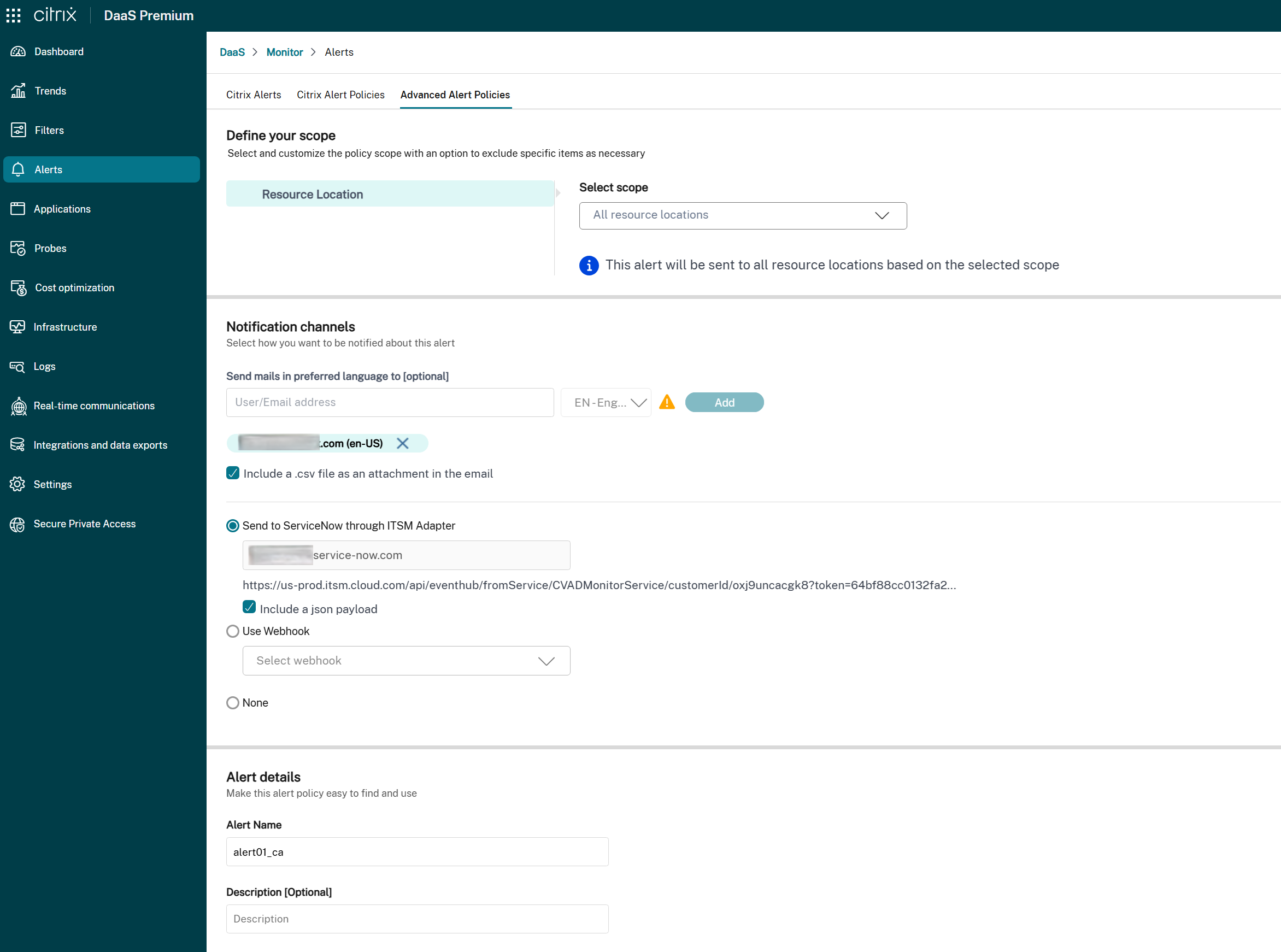
在通知首选项部分中,查找ServiceNow 集成选项:
-
如果 ITSM Adapter 可用:
- 选中此复选框以通过 ServiceNow 为此策略启用警报通知。
- 关联的 ServiceNow 实例 URL 将显示以供参考。
- 如果策略已配置 Webhook,则会显示警告消息,通知您启用 ServiceNow 集成将覆盖现有 Webhook 配置。
-
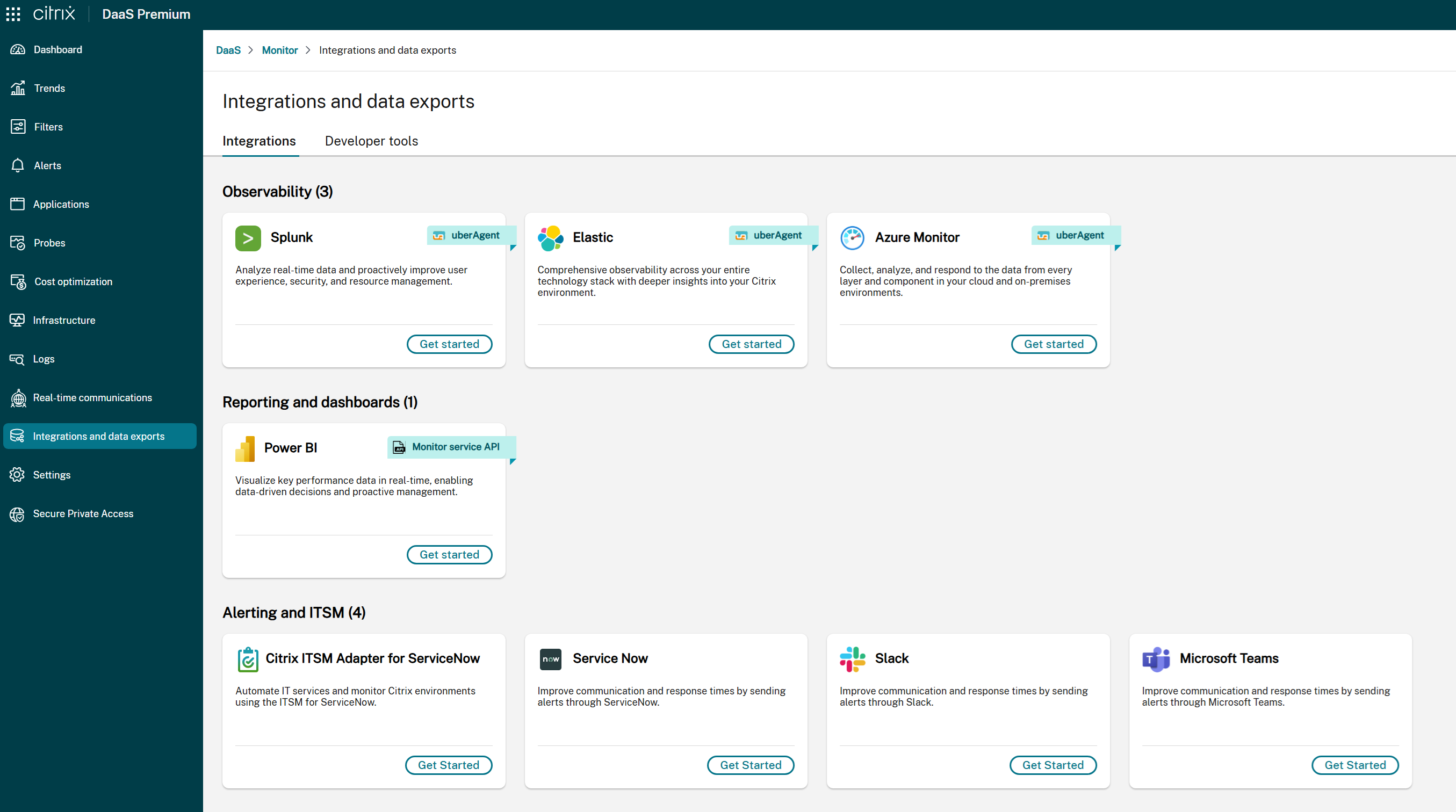
如果 ITSM Adapter 不可用:
- 一条消息指示 ITSM 集成当前未配置。
- 单击开始以访问集成设置。有关详细信息,请参阅文档。
-
如果 ITSM Adapter 可用:
- 单击保存以保存策略。
配置完成后,符合策略条件的警报将自动转发到 ServiceNow,在那里,可以根据您的 ITSM 配置将其作为事件或事件进行管理。
批量解除警报
此功能优化了管理员的警报管理流程,提供了灵活性并减少了警报疲劳。管理员可以根据时间、类型或类别批量解除警报,从而简化了维护期间或处理虚拟机管理程序及其他环境时的警报管理。
批量解除警报有助于管理员高效管理其工作负载,并防止他们被大量警报淹没。
批量解除警报的步骤
-
导航到警报 > Citrix 警报选项卡。将显示警报。
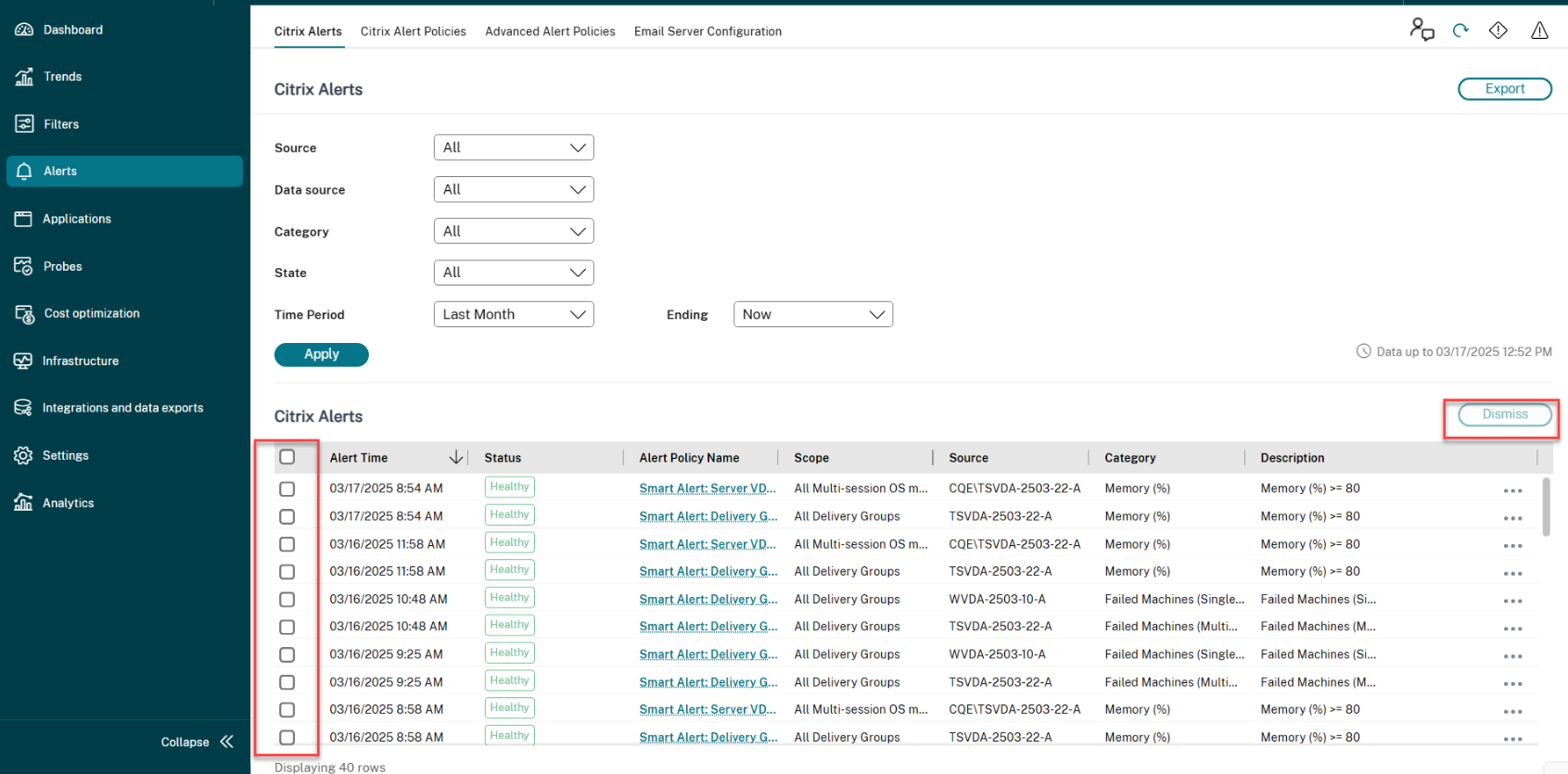
- 从源、类别、状态或时间段中选择一个选项以筛选要解除的警报。将显示特定警报。
- 选中特定警报旁边的复选框,或选中顶部的复选框以选择所有警报。
- 单击解除。将显示一条通知以确认解除警报。
- 单击是。选定的警报将标记为已解除,并且警报状态将相应更新。
使用 PowerShell SDK 配置 Webhook
使用 PowerShell SDK 的 Webhook 配置功能允许管理员创建、修改、删除和列出 Webhook 配置文件。此功能通过允许指定标头、身份验证类型、内容类型、有效负载和 Webhook URL,提供了配置 Webhook 的灵活性。
注意:
支持的有效负载格式为文本,并且最终用户必须在其 Webhook 中启用文本。
最新的有效负载格式为:
{"text": "This is a message from a Webex incoming webhook."}
<!--NeedCopy-->
创建 Webhook
您可以使用以下 PowerShell 示例命令创建 Webhook 配置文件:
创建不带授权标头的 Webhook:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$payloads = '{ "text": "$PAYLOAD" }'
$url = "<Fill this field with the required URL>"
Add-MonitorWebhookProfile -Name "webhookprofile1" -Description "Description" -Url $url -Headers $headers -PayloadFormat $payloads -Platform Slack -Type Webhook -MethodType POST
<!--NeedCopy-->
创建带授权标头的 Webhook:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$headers.Add("Authorization", "Basic <Fill this field with the authorization token>")
$payloads = '{ "text": "$PAYLOAD" }'
$url = "<Fill this field with the required URL>"
Add-MonitorWebhookProfile -Name "webhookprofile1" -Description "Description" -Url $url -Headers $headers -PayloadFormat $payloads -Platform Slack -Type Webhook -MethodType POST
<!--NeedCopy-->
示例:
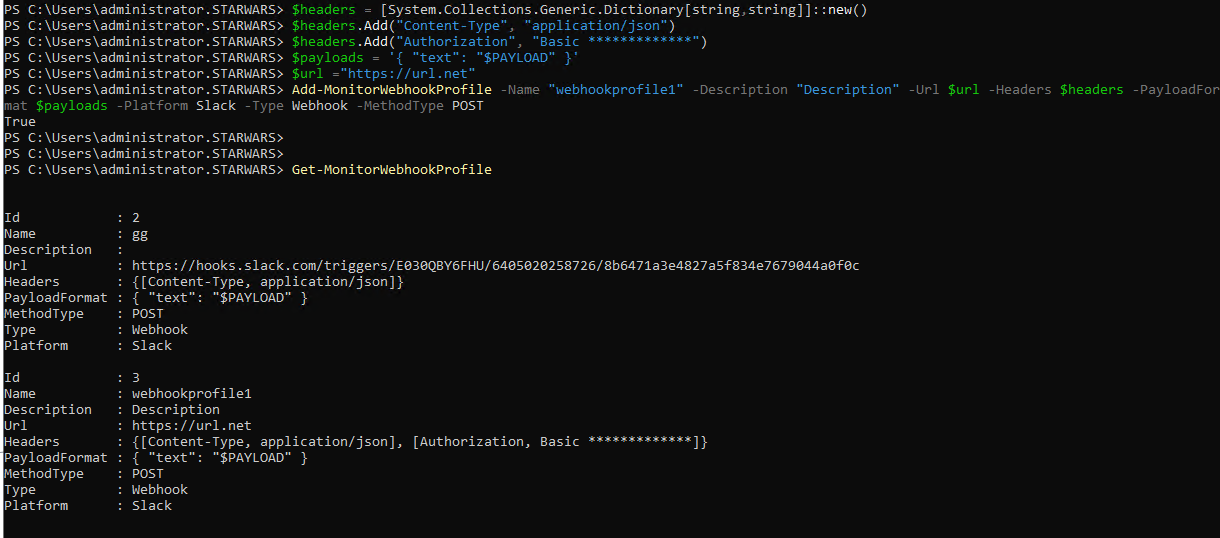
创建配置文件后,您可以在数据库中检查它。此外,您可以在Citrix 警报页面中找到新创建的 Webhook 配置文件。
更新 Webhook 配置文件
您可以使用以下 PowerShell 示例命令更新 Webhook 配置文件:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$payloads = '{ "text": "$PAYLOAD" }'
$url = "<Fill this field with the required URL>"
Set-MonitorWebhookProfile -Uid 1 -Name "profile_slack_citrix" -Description "webhook profile for citrix slack" -Url $url -Headers $headers -PayloadFormat $payloads -Platform Slack -Type Webhook -MethodType POST
<!--NeedCopy-->
示例:
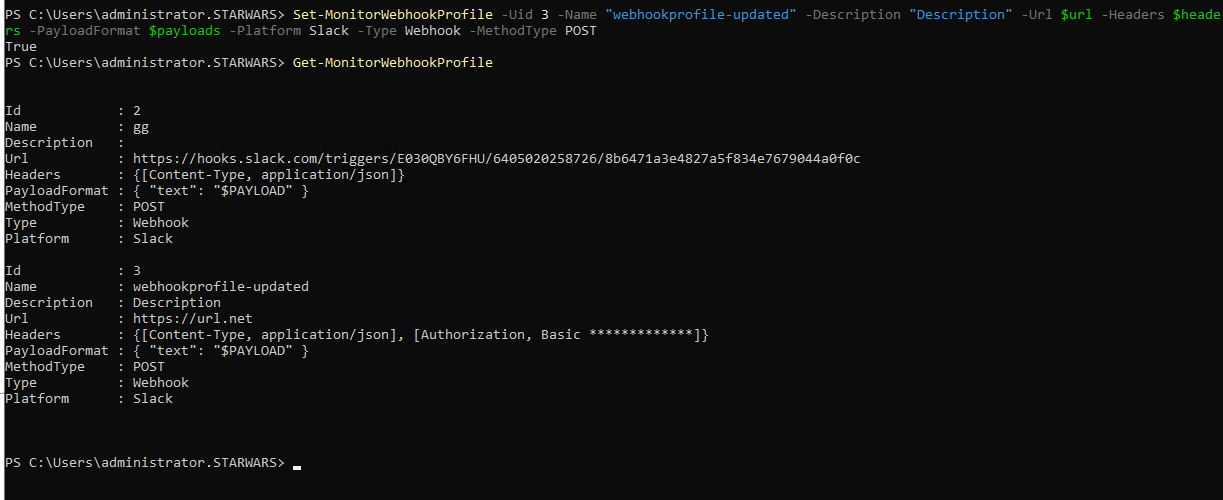
获取所有 Webhook 配置文件列表
您可以使用以下 PowerShell 示例命令获取所有可用的 Webhook 配置文件列表:
Get-MonitorWebhookProfile
Get-MonitorWebhookProfile -Name 'profile_msteams'
Get-MonitorWebhookProfile -Uid 1
<!--NeedCopy-->
删除 Webhook 配置文件
您可以使用以下 PowerShell 示例命令删除 Webhook 配置文件:
Remove-MonitorWebhookProfile -Uid 1
<!--NeedCopy-->
注意:
如果 Webhook 配置文件已映射到任何策略,则无法将其删除。作为一种变通方法,您必须首先从策略中删除 Webhook 映射。
创建包含 Webhook 配置文件的策略
您可以使用以下 PowerShell 示例命令创建包含 Webhook 配置文件的策略:
New-MonitorNotificationPolicy -Name "Policy1" -Description "Policy Description" -Enabled $true -WebhookProfileId 1
<!--NeedCopy-->
更新包含 Webhook 配置文件的策略
您可以使用以下 PowerShell 示例命令更新包含 Webhook 配置文件的策略:
$Policy = Set-MonitorNotificationPolicy -Uid 1 -WebhookProfileId 1
<!--NeedCopy-->
从策略中删除 Webhook 映射
您可以使用以下 PowerShell 示例命令从策略中删除 Webhook 配置文件:
$Policy = Set-MonitorNotificationPolicy -Uid 1 -WebhookProfileId 0
<!--NeedCopy-->
测试 Webhook 配置文件
您可以使用以下 PowerShell 示例命令测试 Webhook 配置文件:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$headers.Add("Authorization", "Basic <Fill this with authorization token>")
$payloads = '{ "text": "$PAYLOAD" }'
$url ="<Fill this field with the required URL>"
Test-MonitorWebhookProfile -Url $url -Headers $headers -PayloadFormat $payloads
<!--NeedCopy-->
本地主机缓存配置同步失败警报监视
即使云连接器与 Citrix Cloud 失去连接,本地主机缓存也允许用户会话继续。本地主机缓存使用的缓存会定期与主数据库同步,以确保在激活本地主机缓存模式时配置是最新的。您可以在本地主机缓存中了解有关本地主机缓存和配置同步过程的更多信息。如果配置同步连续失败三次以上,Citrix Monitor 会向管理员发送警告警报。
Citrix Monitor 中引入了一个名为 本地主机缓存 - 配置同步失败 的预定义警报策略,用于通知管理员配置同步失败。您可以在 Monitor > Citrix Alerts 中找到新引入的策略。您可以修改预定义策略以添加或编辑电子邮件收件人或 Webhook,以便在警报管理或 ITSM 工具中接收主动通知。
本地主机缓存 - 配置同步失败 警报策略的范围仅限于站点。
虚拟机管理程序警报监视
Monitor 显示警报以监视虚拟机管理程序运行状况。来自 Citrix Hypervisor™ 和 VMware vSphere 的警报有助于监视虚拟机管理程序参数和状态。还会监视与虚拟机管理程序的连接状态,以便在主机群集或池重新启动或不可用时提供警报。
要接收虚拟机管理程序警报,请确保在 管理 选项卡中创建了托管连接。有关详细信息,请参阅连接和资源。只有这些连接会受到监视以获取虚拟机管理程序警报。下表描述了虚拟机管理程序警报的各种参数和状态。
| 警报 | 支持的虚拟机管理程序 | 触发者 | 条件 | 配置 |
|---|---|---|---|---|
| CPU 使用率 | Citrix Hypervisor、VMware vSphere | 虚拟机管理程序 | CPU 使用率警报阈值已达到或超出 | 必须在虚拟机管理程序中配置警报阈值。 |
| 内存使用率 | Citrix Hypervisor、VMware vSphere | 虚拟机管理程序 | 内存使用率警报阈值已达到或超出 | 必须在虚拟机管理程序中配置警报阈值。 |
| 网络使用率 | Citrix Hypervisor、VMware vSphere | 虚拟机管理程序 | 网络使用率警报阈值已达到或超出 | 必须在虚拟机管理程序中配置警报阈值。 |
| 磁盘使用率 | VMware vSphere | 虚拟机管理程序 | 磁盘使用率警报阈值已达到或超出 | 必须在虚拟机管理程序中配置警报阈值。 |
| 主机连接或电源状态 | VMware vSphere | 虚拟机管理程序 | 虚拟机管理程序主机已重新启动或不可用 | 警报在 VMware vSphere 中预构建。无需额外配置。 |
| 虚拟机管理程序连接不可用 | Citrix Hypervisor、VMware vSphere | Delivery Controller | 与虚拟机管理程序(池或群集)的连接丢失、断电或重新启动。只要连接不可用,此警报就会每小时生成一次。 | 警报随 Delivery Controller 预构建。无需额外配置。 |
注意:
有关配置警报的更多信息,请参阅 Citrix XenCenter 警报或查看 VMware vCenter 警报文档。
可以在 Citrix Alerts Policy > Site Policy > Hypervisor Health 下配置电子邮件通知首选项。虚拟机管理程序警报策略的阈值条件只能在虚拟机管理程序中配置、编辑、禁用或删除,而不能在 Monitor 中进行。但是,可以在 Monitor 中修改电子邮件首选项和解除警报。
重要提示:
- 所有超过一天的虚拟机管理程序警报都会自动解除。
- 虚拟机管理程序触发的警报会在 Monitor 中获取并显示。但是,虚拟机管理程序警报生命周期/状态的变化不会反映在 Monitor 中。
- 在虚拟机管理程序控制台中处于正常、已解除或已禁用状态的警报将继续显示在 Monitor 中,并且必须明确解除。
- 在 Monitor 中解除的警报不会在虚拟机管理程序控制台中自动解除。
已添加一个名为 虚拟机管理程序运行状况 的新警报类别,以仅筛选虚拟机管理程序警报。一旦达到或超出阈值,就会显示这些警报。虚拟机管理程序警报可以是:
- 严重 — 虚拟机管理程序警报策略的严重阈值已达到或超出
- 警告 — 虚拟机管理程序警报策略的警告阈值已达到或超出
- 已解除 — 警报不再显示为活动警报