ユーザーエクスペリエンス (UX) 要因
UX要因ページでは、UXダッシュボードで選択したユーザーセットの要因およびサブファクターレベルのエクスペリエンスに関するインサイトを提供します。
UXダッシュボードで、[エクセレント]、[フェア]、または[プア]のUXカテゴリのいずれかをクリックすると、UX要因ページが開きます。このページでは、要因およびサブファクターメトリックがユーザーエクスペリエンスに与える影響を定量化します。このページでは、セッション可用性、セッション応答性、セッション回復性、セッションログオン期間という要因に関するエクスペリエンスに基づいて、選択されたユーザーセットを分類します。さらに、選択されたユーザーは、これらの要因内のサブファクターに関するエクスペリエンスに基づいて分類されます。このドリルダウンにより、環境内のユーザーのプアなエクスペリエンスの原因となっている実際のサブファクターを特定できます。
ユーザーエクスペリエンス (UX) 要因ページの使用方法
ユーザーエクスペリエンスに影響を与える要因メトリックをさらに深く掘り下げるには、UXダッシュボードの[エクセレント]、[フェア]、または[プア]カテゴリのいずれかの数字をクリックします。
-
過去2時間で、21人のユーザーがエクセレントなエクスペリエンス、39人がフェアなエクスペリエンス、30人がプアなエクスペリエンスを経験しているシナリオを考えてみましょう。30人のユーザーがプアなユーザーエクスペリエンスに直面している理由を理解するには、ユーザーエクスペリエンスダッシュボードから数字の30をクリックします。
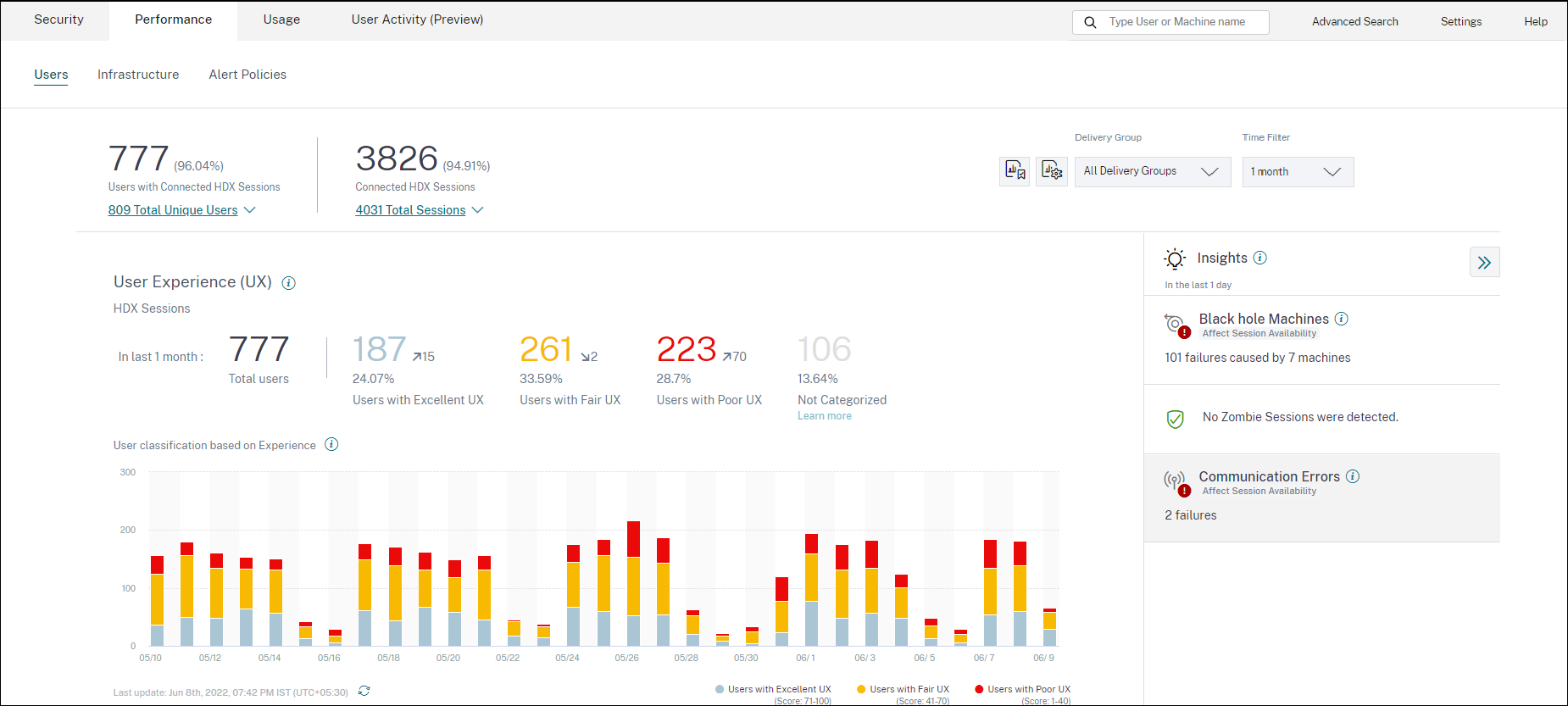
-
ユーザーエクスペリエンス (UX) 要因画面には、過去2時間におけるすべてのサイトでユーザーのプアなエクスペリエンスに影響を与える要因のドリルダウンが表示されます。
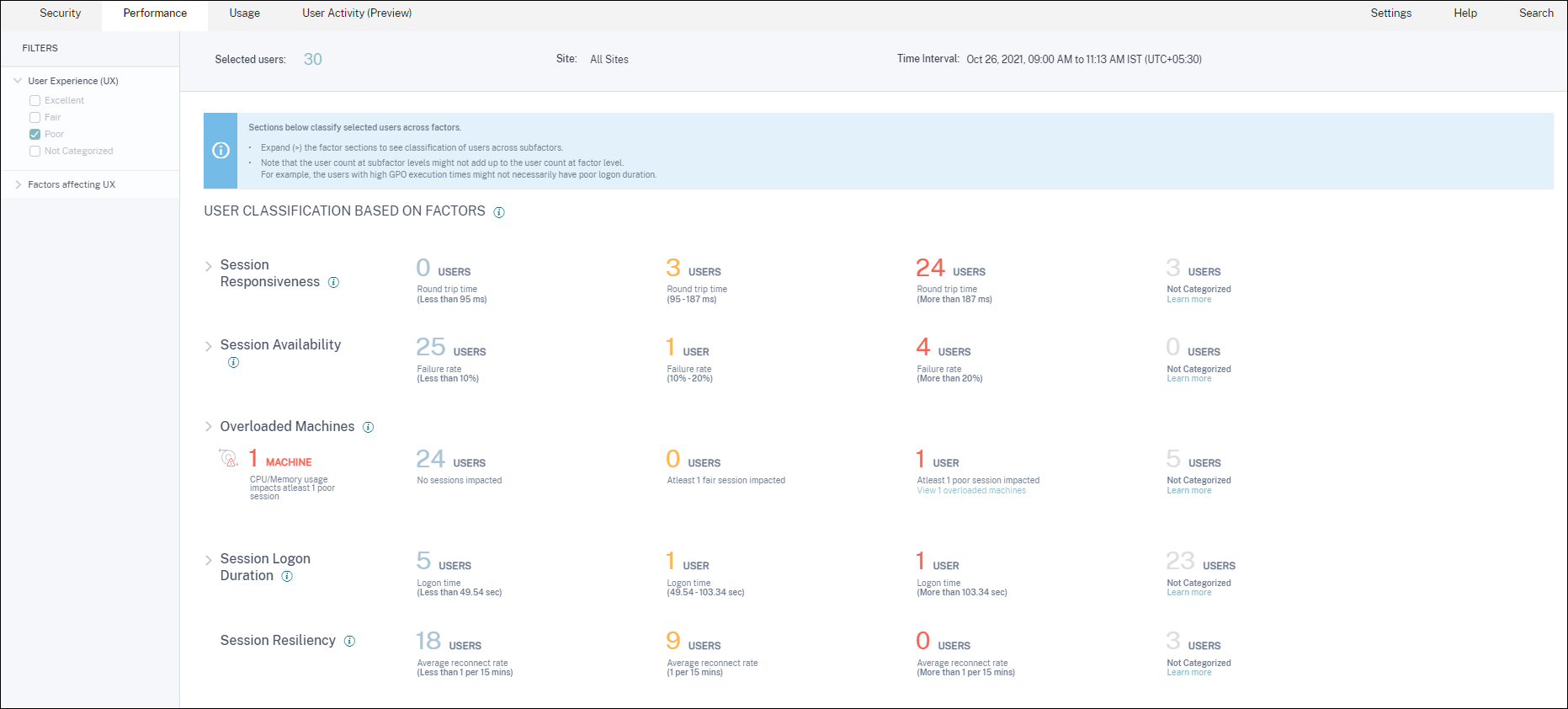
-
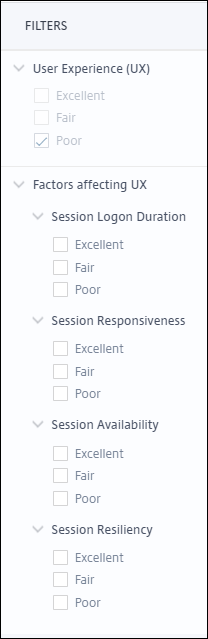
左側のパネルには、ユーザーエクスペリエンスと要因の選択フィルターが表示されます。
[Selected users] の数字をクリックすると、特定のユーザーセットのセルフサービス検索ページにアクセスできます。
-
UX要因ページのセクションでは、セッション可用性、セッション応答性、セッション回復性、セッションログオン期間、過負荷マシンという要因に基づいて、選択されたユーザーセットをさらに分類します。各要因セクションを展開 (クリック >) して、それぞれのサブファクター全体のエクスペリエンスに基づくユーザー分類を確認します。要因は、プアな要因エクスペリエンスを持つユーザーの数に基づいてソートされます。
-
全体的なユーザーエクスペリエンスの分類は、要因レベルのユーザー数と一致しない場合があります。また、1つ以上の要因でプアなエクスペリエンスがあったとしても、必ずしも全体的にプアなユーザーエクスペリエンスを意味するわけではありません。
-
同様に、個々のサブファクターレベルのユーザー数は、要因レベルのユーザー数と合計されない場合があります。たとえば、GPOが多いユーザーでも、他のサブファクターでのエクスペリエンスがエクセレントであった場合、必ずしもログオンエクスペリエンスがプアであるとは限りません。
-
要因およびサブファクターレベルでのユーザーの分類は、全体的なユーザーエクスペリエンスがプアである正確な原因を特定し、トラブルシューティングするのに役立ちます。
-
[未分類] のユーザーに関する情報については、未分類メトリックの記事を参照してください。
セッションログオン期間
セッションログオン期間は、セッションを起動するのにかかる時間です。これは、ユーザーがCitrix Workspaceアプリから接続してから、アプリまたはデスクトップが使用可能になるまでの期間として測定されます。このセクションでは、セッションログオン期間の測定値に基づいてユーザーを分類します。エクスペリエンスをエクセレント、フェア、またはプアに分類するためのログオン期間のしきい値は、動的に計算されます。セッションログオン期間の動的しきい値の詳細については、動的しきい値セクションを参照してください。
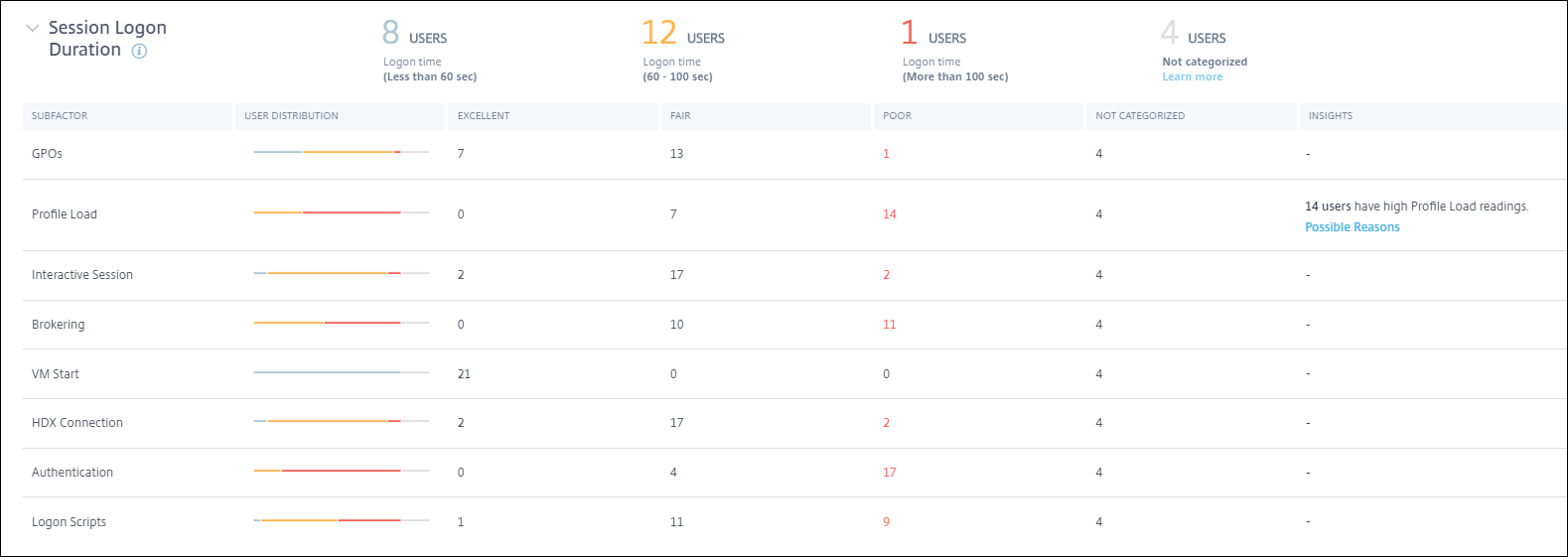 分類されたユーザー数の数字をクリックすると、選択されたユーザーセットの実際のパフォーマンス要因測定値を表示するセルフサービス画面が表示されます。
分類されたユーザー数の数字をクリックすると、選択されたユーザーセットの実際のパフォーマンス要因測定値を表示するセルフサービス画面が表示されます。
セッションログオン期間は、複雑な起動シーケンスにおける個々のフェーズを表すサブファクターに分解されます。セッションログオン期間ドリルダウンテーブルの各行は、セッション起動中に発生する個々のフェーズのユーザー分類を表します。これにより、特定のユーザーログオンの問題をトラブルシューティングし、特定するのに役立ちます。
各サブファクターエクスペリエンスに関連するエクセレント、フェア、プアカテゴリのユーザー数が表示されます。この情報を使用して、ログオン期間の延長に寄与している可能性のある特定のサブファクターフェーズを分析します。
たとえば、GPOでプアなエクスペリエンスに直面しているユーザーの数が最も多い場合、これらのユーザーに適用されるGPOポリシーを確認して、ログオン期間エクスペリエンスの改善に役立ててください。
最後の[未分類] 列には、選択された期間に特定のサブファクター測定値が利用できなかったユーザーの数が表示されます。具体的な理由は、個々のサブファクターの説明で詳しく説明されています。
GPO
GPOは、ログオン中にグループポリシーオブジェクトを適用するのにかかる時間です。GPOの測定は、グループポリシー設定が仮想マシンで構成され、有効になっている場合にのみ利用できます。
GPOインサイトは、選択された期間中に最も長い処理時間を要する環境内のクライアント側拡張機能を表示します。インサイトを表示するには、セッションログオン期間サブファクターテーブルのGPOの[インサイト] 列にある[コントリビューターを表示] リンクをクリックします。GPOインサイトは、GPO実行でプアなエクスペリエンスを持つユーザーセッションの分析に基づいています。

クライアント側拡張機能 (CSE) は、クライアントマシンでグループポリシーを実装するダイナミックリンクライブラリ (DLL) です。処理時間が長いCSEはGPO実行時間を増加させ、CSE処理を最適化することでユーザーの全体的なセッションログオンエクスペリエンスが向上します。
平均CSE実行時間は、適用されるポリシーの数と種類によって異なります。CSEの処理時間を改善するには、次のポインターを使用します。
-
フォルダーリダイレクト: CSE実行時間は、リダイレクトされるフォルダーの数と各フォルダーの内容によって異なります。システムには、すべてのフォルダーリダイレクト後に適用される待機が構成されている場合があります。CSE実行時間を短縮するために、フォルダーの数を最適化します。
-
ドライブマッピング: ログオンスクリプトは、存在しないターゲットサーバーにドライブをマッピングしようとする可能性があり、その結果、実行時間が長くなります。サーバーアドレスが正しいこと、および利用可能であることを確認してください。
GPOインサイトに示されている、最も長い処理時間を要するCSEに関連付けられたポリシーを確認し、調整します。さらに、不要なものは削除することを検討してください。
プロファイルロード
プロファイルロードは、ログオン期間の最も重要なフェーズの1つです。これは、ユーザープロファイル (レジストリハイブ (NTUser.dat) とユーザーファイルを含む) をロードするのにかかる時間です。プロファイルロード時間を最適化することで、全体的なログオン期間エクスペリエンスを改善できます。
プロファイルロードの測定は、仮想マシンでユーザーのプロファイル設定が構成されている場合にのみ利用できます。
プロファイルロードの[インサイト] 列には、プロファイルサイズが長いプロファイルロード時間の原因となっている要因であるというインサイトが表示されます。これは、大きなプロファイルサイズの影響を受ける可能性のあるユーザーを特定します。
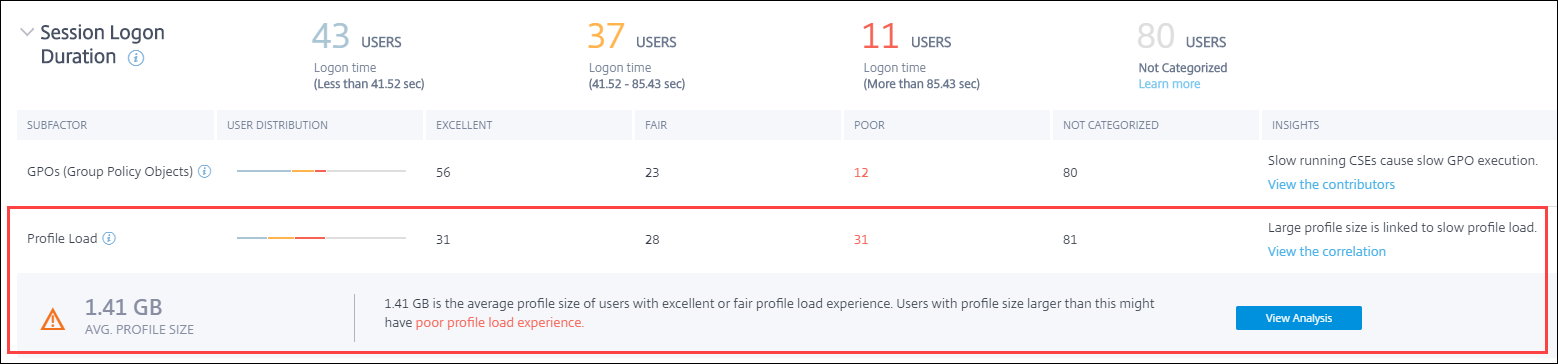
[相関関係を表示] リンクをクリックすると、ユーザーの平均プロファイルサイズが表示されます。平均プロファイルサイズは、過去30日間にエクセレントおよびフェアなプロファイルロードエクスペリエンスを経験したユーザーのプロファイルサイズを使用して計算されます。このプロファイルサイズが最適と識別されます。平均よりも大きなプロファイルサイズを持つユーザーは、プロファイルロード時間がプアになる可能性があります。
[分析を表示] をクリックすると、プロファイルサイズが平均よりも大きいユーザーのリストが表示されます。このビューには、各ユーザーの最後に確認されたプロファイルサイズと平均プロファイルサイズが表示されます。ファセットを使用してこのデータをさらにフィルター処理し、大きなプロファイルサイズとプアなログオン期間エクスペリエンスの両方を持つユーザーを表示します。
ユーザーの詳細を展開して、プアなエクスペリエンスの原因をさらにトラブルシューティングするための特定のパフォーマンスメトリックを表示します。
これらのインサイトを使用して、ユーザーにプロファイル内の大きなファイルを削減するよう推奨します。
プロファイルサイズの測定値または平均プロファイルサイズが利用できない場合、インサイトは表示されません。
-
プロファイルサイズの測定には、Citrix Profile Managementがマシンにインストールされている必要があります。
-
プロファイルサイズの測定は、マシンバージョン1912以降でサポートされています。
-
過去30日間にフェアおよびエクセレントなプロファイルロードエクスペリエンスを経験したユーザーのプロファイルサイズの測定値は、平均プロファイルサイズを計算するために使用されます。この期間のデータポイントが利用できない場合、インサイトは導出されません。
-
プロファイルロードインサイトは、プロファイルサイズが遅いプロファイルロードの原因である場合に導出されます。プロファイル内に複数のプロファイルファイルが存在することも、遅いプロファイルロードの原因となる可能性があります。
インタラクティブセッション
ユーザープロファイルがロードされた後、ユーザーにキーボードとマウスの制御を「引き渡す」のにかかる時間です。通常、ログオンプロセスすべてのフェーズの中で最も長い期間です。
ブローカリング
ユーザーに割り当てるデスクトップを決定するのにかかる時間です。
VM起動
セッションにマシンの起動が必要な場合、これは仮想マシンを起動するのにかかる時間です。この測定は、電源管理されていないマシンでは利用できません。
HDX™接続
エンドポイントから仮想マシンへのHDX接続を確立するために必要な手順を完了するのにかかる時間です。
認証
リモートセッションへの認証を完了するのにかかる時間です。
ログオンスクリプト
ログオンスクリプトの実行にかかる時間です。この測定は、セッションにログオンスクリプトが構成されている場合にのみ利用できます。
セッション応答性
セッションが確立されると、セッション応答性要因は、ユーザーがアプリまたはデスクトップと対話する際に経験する画面の遅延を測定します。セッション応答性は、ユーザーがキーを押してからグラフィカルな応答が表示されるまでの経過時間を表すICA®ラウンドトリップタイム (ICA RTT) を使用して測定されます。
ICA RTTは、サーバーおよびエンドポイントマシンネットワークにおけるトラフィック遅延と、アプリケーションの起動にかかる時間の合計として測定されます。ICA RTTは、実際のユーザーエクスペリエンスの概要を示す重要なメトリックです。
エクスペリエンスをエクセレント、フェア、またはプアに分類するためのセッション応答性のしきい値は、動的に計算されます。セッション応答性の動的しきい値の詳細については、動的しきい値セクションを参照してください。
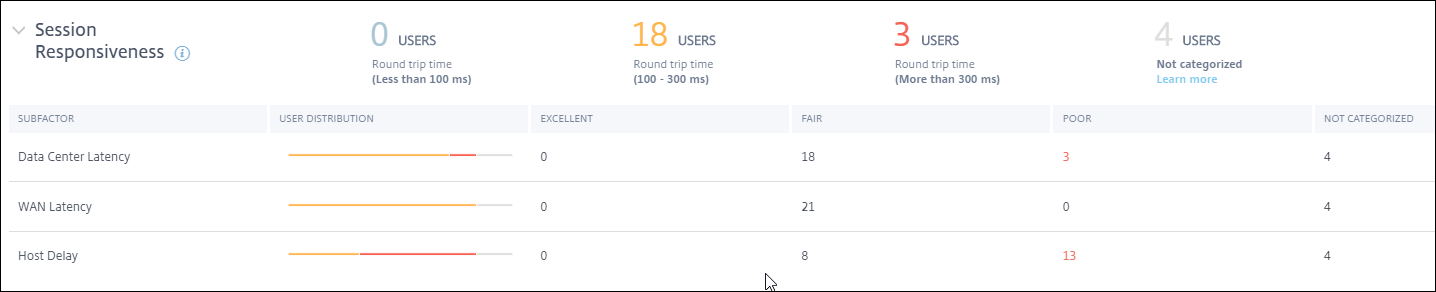
セッション応答性ドリルダウンは、セッションのICA RTT測定値に基づくユーザーの分類を表します。これらの数字をクリックすると、そのカテゴリのメトリックにドリルダウンします。エクセレントなセッション応答性を持つユーザーは非常に反応性の高いセッションを持ち、プアなセッション応答性を持つユーザーはセッションで遅延に直面しました。
注:
ICA RTT測定値はアプリとデスクトップから取得されますが、サブファクター測定値はオンプレミスのCitrix Gatewayから取得されます。したがって、サブファクター値は、ユーザーが構成されたオンプレミスのCitrix Gatewayを介してアプリまたはデスクトップに接続している場合にのみ利用できます。Citrix GatewayをCitrix Analytics for Performanceで構成する手順については、Gatewayデータソースを参照してください。さらに、L7レイテンシーしきい値を構成する必要があります。詳細については、L7レイテンシーしきい値を参照してください。
さらに、これらの測定は次のセッションで利用できます。
- NSAPが有効なマシンから起動されたセッション
- 再接続されたセッションではなく、新しいCGP (Common Gateway Protocol) セッション
ユーザーがCitrix Gateway Serviceを介して接続している場合、これらの測定は利用できません。
セッション応答性ドリルダウンテーブルの行は、サブファクター測定値におけるユーザー分類を表します。各サブファクターについて、各カテゴリのユーザー数が[エクセレント]、[フェア]、[プア]列に表示されます。この情報は、プアなユーザーエクスペリエンスに寄与している特定のサブファクターを分析するのに役立ちます。
たとえば、データセンターレイテンシーで記録されたプアなユーザーの数が最も多い場合、サーバー側ネットワークの問題を示しています。
最後の[未分類] 列には、選択された期間に特定のサブファクター測定値が利用できなかったユーザーの数が表示されます。
次のサブファクターがセッション応答性に寄与します。ただし、サブファクターのICA RTTはレイヤー4までしか測定できないため、合計ICA RTTはサブファクターメトリックの合計ではありません。
-
データセンターレイテンシー: このサブファクターは、Citrix Gatewayからサーバーまでのレイテンシーを測定します。データセンターレイテンシーが高い場合、サーバーネットワークの遅延を示します。
-
WANレイテンシー: このサブファクターは、仮想マシンからGatewayまでのレイテンシーを測定します。WANレイテンシーが高い場合、エンドポイントマシンネットワークの遅延を示します。ユーザーがGatewayから地理的に遠いほど、WANレイテンシーは増加します。
-
ホストレイテンシー: このサブファクターは、サーバーOSによって引き起こされる遅延を測定します。データセンターおよびWANレイテンシーが低く、ホストレイテンシーが高いICA RTTは、ホストサーバー上のアプリケーションエラーを示します。
いずれかのサブファクターでプアなエクスペリエンスに直面しているユーザーの数が多い場合、問題がどこにあるかを理解するのに役立ちます。レイヤー4遅延測定を使用して、問題をさらにトラブルシューティングできます。これらのレイテンシーメトリックのいずれも、パケット損失、順序が異なるパケット、重複する確認応答、または再送信を考慮していません。これらの場合、レイテンシーが増加する可能性があります。
ICA RTTの計算の詳細については、NetScaler InsightでのICA RTTの計算方法を参照してください。 Citrix Gatewayのオンボーディングの詳細については、Gatewayデータソースを参照してください。
セッション可用性
セッション可用性は、失敗率に基づいて計算されます。これは、試行されたセッション接続の総数に対する失敗したセッション接続の割合です。
セッション可用性エクスペリエンスは、セッション失敗率に基づいて次のように分類されます。
エクセレント: 失敗率が10%未満。エクセレントなセッション可用性要因は、ユーザーがアプリまたはデスクトップに正常に接続して使用できることを示します。
フェア: 失敗率が10~20%。
プア: 失敗率が20%を超える。プアなセッション可用性エクスペリエンスを持つ多くのユーザーは、セッションに接続して使用できないことを示します。
セッションの起動失敗はユーザーの生産性を妨げるため、全体的なユーザーエクスペリエンスを定量化する上で重要な要因です。
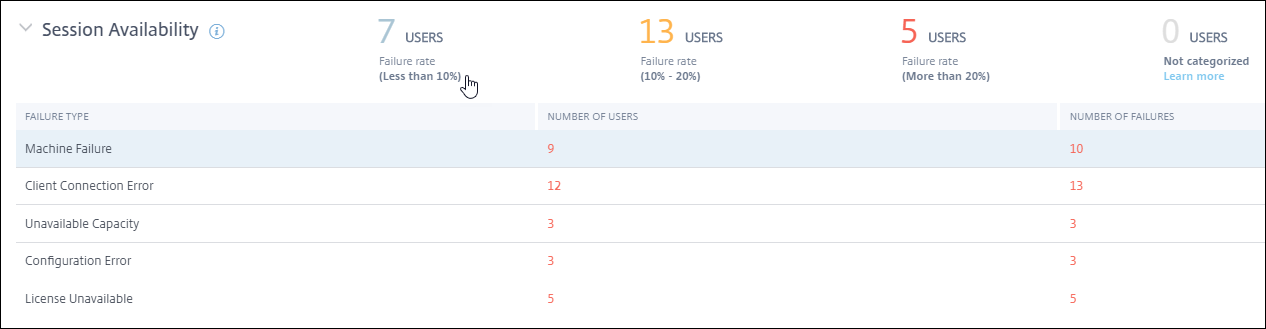
セッション信頼性ドリルダウンテーブルの行には、ユーザー数と各カテゴリの失敗数で分類された失敗の種類が表示されます。リストされた失敗の種類を使用して、失敗をさらにトラブルシューティングします。
特定された失敗の種類内の考えられる理由の詳細については、Citrix Directorの失敗理由とトラブルシューティングドキュメントを参照してください。
セッション回復性
セッション回復性は、ネットワークの中断から回復するためにCitrix Workspace™アプリが自動再接続した回数を示します。自動再接続は、ネットワーク接続が中断されたときにセッションをアクティブに保ちます。ユーザーは、ネットワーク接続が再開されるまで、使用しているアプリケーションを引き続き表示します。エクセレントなセッション回復性要因は、スムーズなユーザーエクスペリエンスと、ネットワークの中断による再接続回数の減少を示します。
自動再接続は、セッション信頼性または自動クライアント再接続ポリシーが有効な場合に有効になります。エンドポイントでネットワーク中断が発生した場合、次の自動再接続ポリシーが有効になります。
- セッション信頼性ポリシーが有効になり (デフォルトで3分以内)、Citrix Workspaceアプリがマシンへの接続を試行します。
- 自動クライアント再接続ポリシーが3分から5分の間に有効になり、エンドポイントがマシンへの接続を試行します。
各ユーザーについて、選択された期間にわたる15分間隔ごとに自動再接続の数が測定されます。ほとんどの15分間隔での自動再接続の数に基づいて、エクスペリエンスはエクセレント、フェア、またはプアに分類されます。

セッション回復性エクスペリエンスは、再接続率に基づいて次のように分類されます。
エクセレント: 選択された期間のほとんどの15分間隔で、再接続はありませんでした。
フェア: 選択された期間のほとんどの15分間隔で、1回の再接続がありました。
プア: 選択された期間のほとんどの15分間隔で、2回以上の再接続がありました。
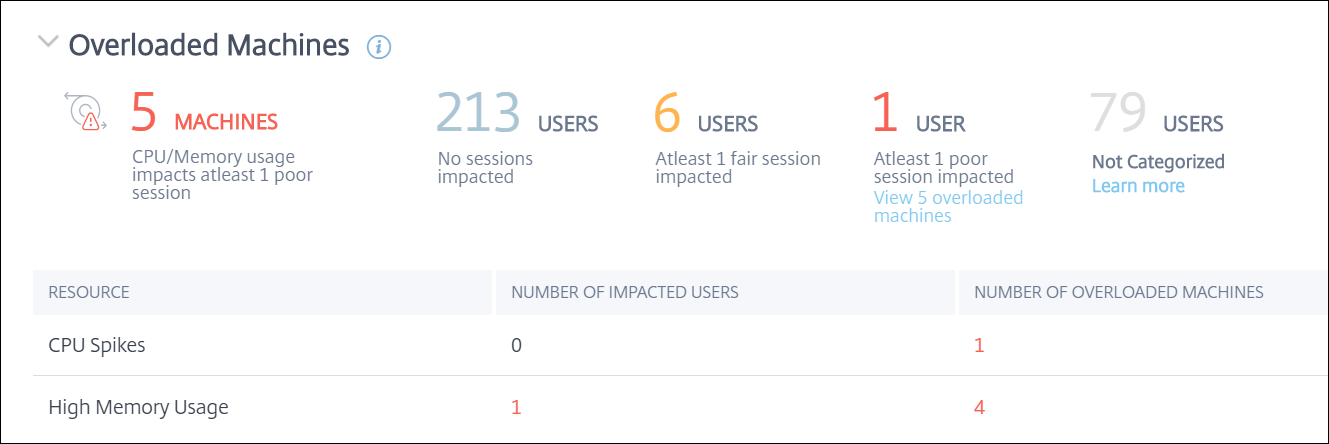
過負荷マシン
過負荷のリソースは、高いレイテンシー、長いログオン期間、および失敗を引き起こし、プアなユーザーエクスペリエンスにつながる可能性があります。[過負荷マシン] 要因は、プアなエクスペリエンスを引き起こしている過負荷のリソースに関する可視性を提供します。
選択された期間に、持続的なCPUスパイク、または高いメモリ使用量、あるいはその両方が5分以上続き、プアなユーザーエクスペリエンスを引き起こしたマシンは、過負荷と見なされます。
注:
[過負荷マシン] 要因セクションは、2時間、12時間、および1日の範囲でのみ利用できます。この機能は、最適化のために1週間および1か月の期間では無効になっています。
[過負荷マシン] セクションには、次のデータが含まれています。
- ユーザーエクスペリエンスに関係なく、CPUまたはメモリ使用量が少なくとも1つのプアなセッションに影響を与えたマシンの数。
- 過負荷のCPUまたはメモリがセッションエクスペリエンスに与える影響により影響を受けたユーザーの数。
- エクセレント – 過負荷マシンによる影響を受けたセッションがないユーザー。
- フェア – 過負荷マシンによる影響を受けたフェアなセッションが少なくとも1つあるユーザー。
- プア – 過負荷マシンによる影響を受けたプアなセッションが少なくとも1つあるユーザー。
- 未分類 – セッションエクスペリエンスがリソースの過負荷と相関できないユーザー。
- 内訳:
- 過負荷リソースによりプアなエクスペリエンスを持つユーザーに影響を与えているマシンの数。
- CPUスパイクと高いメモリ使用量によりプアなエクスペリエンスを持つユーザーの数。
- 過負荷ユーザーの数をクリックすると、過負荷リソースの影響を受けているセッションを持つユーザーを表示するようにフィルター処理されたユーザーセルフサービスビューが表示されます。
- 過負荷マシンの数をクリックすると、分類に基づいて、または過負荷リソース、CPU、またはマシンに基づいて、選択された過負荷マシンのセットを表示するようにフィルター処理されたマシンセルフサービスビューが表示されます。
次のビデオは、過負荷マシン要因を使用した典型的なトラブルシューティングシナリオを示しています。
マシン、ユーザー、およびセッションのセルフサービスビューは、[過負荷マシン] ファセットで強化されています。マシンセルフサービスビューには、マシン内の過負荷の問題をトラブルシューティングするのに役立つ[過負荷CPU/メモリ] ファセットも追加されています。詳細については、セルフサービスの記事の過負荷マシンを参照してください。
マシンセルフサービスビューからさらにドリルダウンして、特定のマシン統計を表示し、リソース過負荷の問題をトラブルシューティングします。