Splunk architecture with Citrix Analytics add-on application
Splunk follows an architecture which contains the following three tiers:
- Collection
- Indexing
- Searching
Splunk supports a wide range of data collection mechanisms that helps ingest data into Splunk easily, such that it can be indexed and made available to search. This tier is nothing but your heavy forwarder or universal forwarder.
You must install the add-on application on the heavy forwarder layer instead of the universal forwarder layer. Because, with few exceptions for well-structured data (such as, json, csv, tsv), the universal forwarder does not parse log sources into events, so it cannot perform any action that requires understanding of the format of the logs.
It also ships with a stripped down version of Python, which makes it incompatible with any modular input applications that require a full Splunk stack to function. The heavy forwarder is nothing but your collection tier.
The key difference between a universal forwarder and a heavy forwarder is that the heavy forwarder contains the full parsing pipeline, performing the identical functions an indexer performs without actually writing and indexing events on disk. This enables the heavy forwarder to understand and act on individual events such as masking data, filtering, and routing based on event data. Since the add-on application has a full Splunk Enterprise installation, it can host modular inputs that require a full Python stack for proper data collection, or act as an endpoint for the Splunk HTTP Event Collector (HEC).
Once the data is collected, it is indexed or processed and stored in a way that makes it searchable.
The primary way for customers to explore their data is through search. A search can be saved as a report and used to power dashboard panels. Searches are the extract information from your data.
In general, the Splunk add-on application is deployed in the Collection tier (at Splunk enterprise level), whereas our dashboarding application is deployed on the search layer (at Splunk Cloud level). On a simple on-prem setup, you can have all these three tiers on a single Splunk host (known as single server deployment).
The collection tier is much better way to use the add-on application for Splunk. There are two ways to install the add-on application. Either you can install it at the collection tier under the customer environment or you can install it at the inputs data manager under the Splunk Cloud instance.
Refer the following diagram to understand the Splunk deployment architecture with our add-on application:
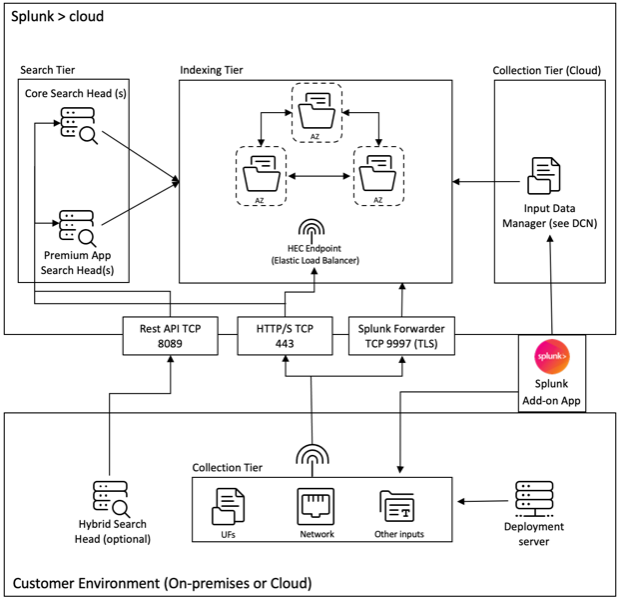
The Inputs Data Manager (IDM) shown in the aforementioned diagram is the Splunk Cloud-managed implementation of a Data Collection Node (DCN) that supports scripted and modular inputs only. For data collection needs beyond that, you can deploy and manage a DCN in your environment using a Splunk heavy forwarder.
Splunk allows to collect, index, and search data from various sources. One way to collect data is through APIs, which allows Splunk to access data stored in other systems or applications. These APIs can include REST, web services, JMS and/or JDBC as the query mechanism. Splunk and any third-party developers offer a range of applications that enable API interactions through the Splunk modular input framework. These applications typically require a full Splunk enterprise software installation to function properly.
To facilitate the collection of data through APIs, it is common to deploy a heavy forwarder as a DCN. Heavy forwarders are more powerful agents than universal forwarders, as they contain the full parsing pipeline and can understand and act on individual events. This enables them to collect data through APIs and process it before forwarding it to a Splunk instance for indexing.
To understand more about the high level architecture of a Splunk Cloud deployment, refer Splunk Validated Architectures.