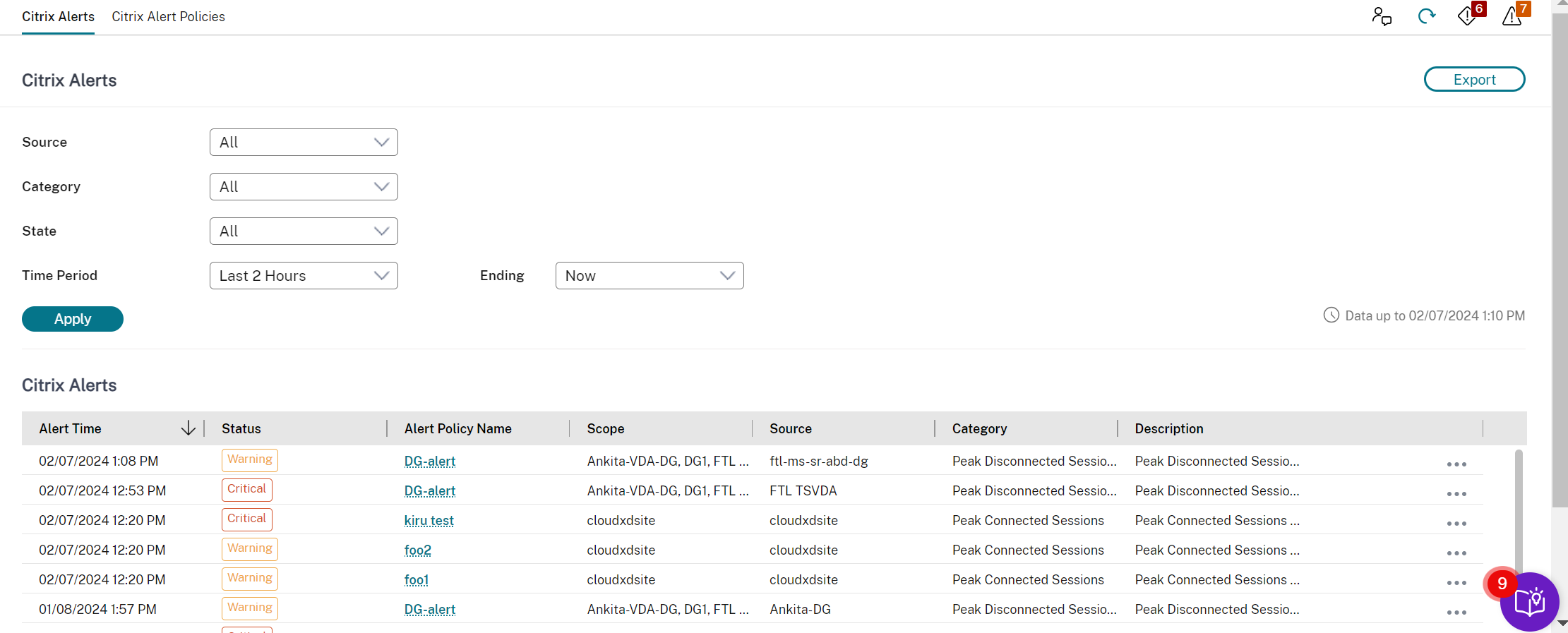
Alertes et notifications
Les alertes s’affichent dans Monitor sur le tableau de bord et d’autres vues de haut niveau avec des symboles d’alerte d’avertissement et critique. Les alertes se mettent à jour automatiquement toutes les minutes ; vous pouvez également les mettre à jour à la demande.
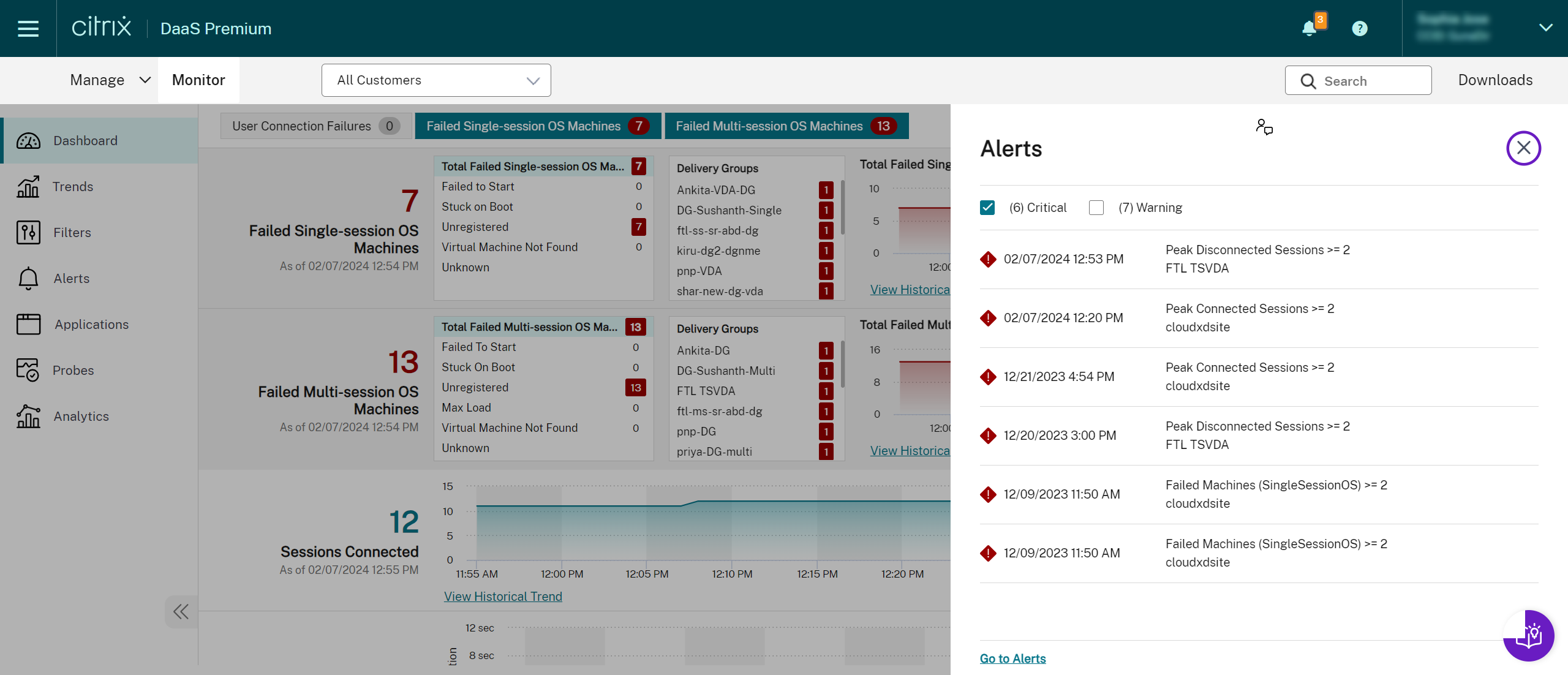
Une alerte d’avertissement (triangle orange) indique que le seuil d’avertissement d’une condition a été atteint ou dépassé.
Une alerte critique (cercle rouge) indique que le seuil critique d’une condition a été atteint ou dépassé.
Vous pouvez afficher des informations plus détaillées sur les alertes en sélectionnant une alerte dans la barre latérale, en cliquant sur le lien Accéder aux alertes au bas de la barre latérale ou en sélectionnant Alertes en haut de la page Monitor.
Dans la vue Alertes, vous pouvez filtrer et exporter les alertes. Par exemple, les machines de système d’exploitation multi-session ayant échoué pour un groupe de mise à disposition spécifique au cours du dernier mois, ou toutes les alertes pour un utilisateur spécifique. Pour plus d’informations, consultez Exporter des rapports.
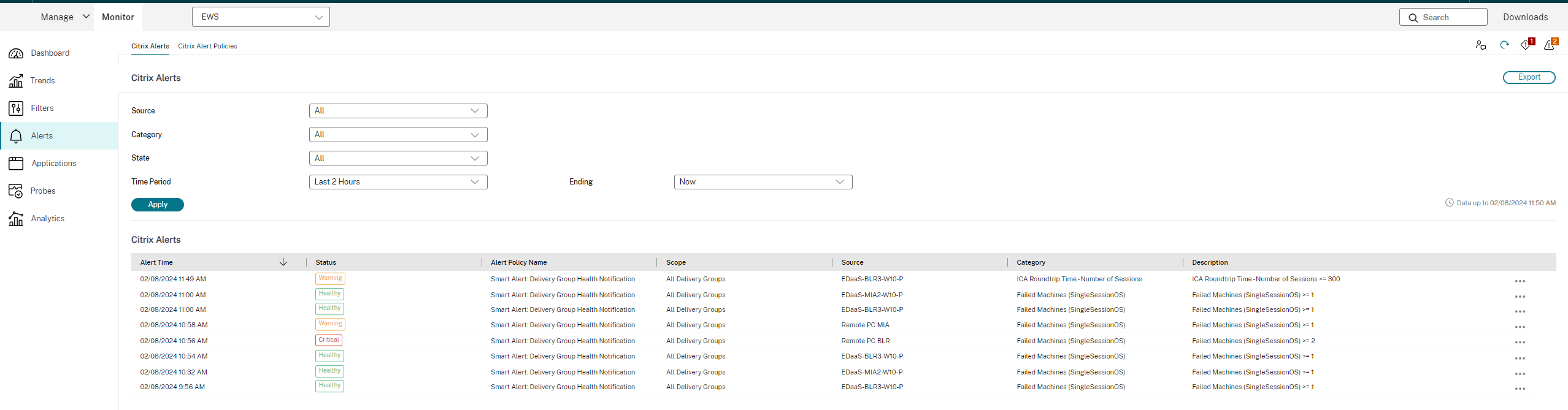
Alertes Citrix®
Les alertes Citrix sont celles qui proviennent des composants Citrix. Vous pouvez configurer les alertes Citrix dans Monitor, dans Alertes > Stratégie d’alertes Citrix. Dans le cadre de la configuration, vous pouvez définir l’envoi de notifications par e-mail à des individus et des groupes lorsque les alertes dépassent les seuils que vous avez définis. Pour plus d’informations sur la configuration des alertes Citrix, consultez Créer des stratégies d’alertes.
Stratégies d’alerte intelligentes
- Un ensemble de stratégies d’alerte intégrées avec des valeurs de seuil prédéfinies est disponible pour les groupes de mise à disposition et l’étendue des VDA de système d’exploitation multi-session. Vous pouvez modifier les paramètres de seuil des stratégies d’alerte intégrées dans Alertes > Stratégie d’alertes Citrix.
- Ces stratégies sont créées lorsqu’il existe au moins une cible d’alerte (un groupe de mise à disposition ou un VDA de système d’exploitation multi-session) définie sur votre site. De plus, ces alertes intégrées sont automatiquement ajoutées à un nouveau groupe de mise à disposition ou à un VDA de système d’exploitation multi-session.
Les stratégies d’alerte intégrées sont créées uniquement si aucune règle d’alerte correspondante n’existe dans la base de données Monitor.
Pour les valeurs de seuil des stratégies d’alerte intégrées, consultez la section Conditions des stratégies d’alertes.
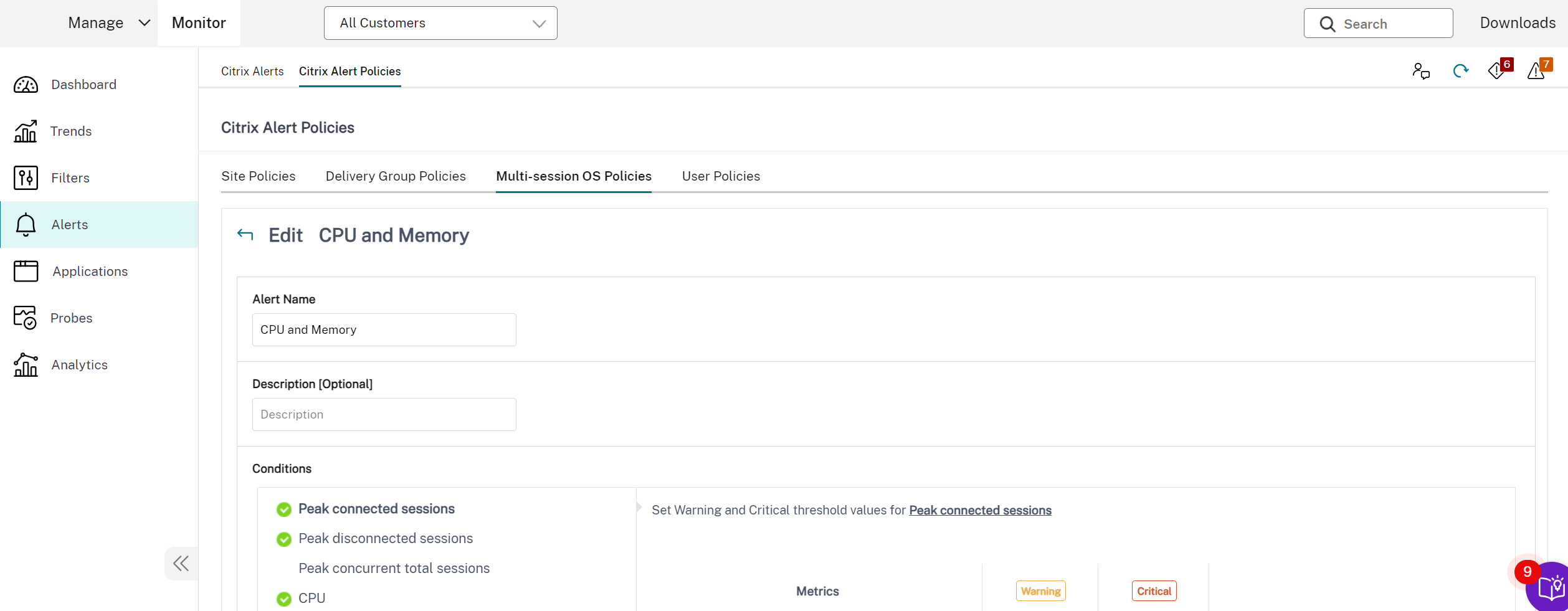
Stratégies d’alerte avancées
- La fonctionnalité de notification et d’alerte proactive de Monitor est améliorée pour inclure un nouveau cadre d’alerte nommé **Stratégies d’alerte avancées**. Grâce à cette fonctionnalité, vous pouvez créer des alertes en incluant des détails granulaires pour chaque élément ou condition, améliorant ainsi le contrôle sur la portée des alertes. Actuellement, ces stratégies incluent des alertes pour les économies de coûts et l’infrastructure.
Avec l’introduction des stratégies d’alerte avancées, qui sont des alertes basées sur des sources de données, vous pouvez utiliser le filtrage de portée multi-conditions.
- Cette fonctionnalité vous aide à réduire les alertes excessives qui pourraient entraîner une réactivité ou une efficacité réduite dans la résolution des problèmes importants. Cette stratégie permet de mesurer l’efficacité des stratégies d’alerte et l’engagement des administrateurs.
- Vous pouvez créer une stratégie d’alerte avancée à partir de la section **Alertes** > **Stratégie d’alerte avancée** > **Créer une stratégie**.
- Vous pouvez sélectionner l’une des sources de données suivantes :
- Machines
- Provisioning Service
- StoreFront™
Alertes pour les économies de coûts
- Vous pouvez créer des alertes pour les économies de coûts, ce qui vous aide à optimiser les coûts. Actuellement, vous pouvez créer des alertes pour les machines.
Pour créer des alertes sur les machines, procédez comme suit :
- Cliquez sur l’onglet Alertes > Stratégies d’alerte avancées. La page Stratégies d’alerte avancées s’affiche.
- Cliquez sur Créer une stratégie. La section Créer des stratégies d’alerte avancées s’affiche.
- Sélectionnez Machines dans la liste déroulante Source de données. La condition d’économies de coûts et les types de conditions correspondants s’affichent.
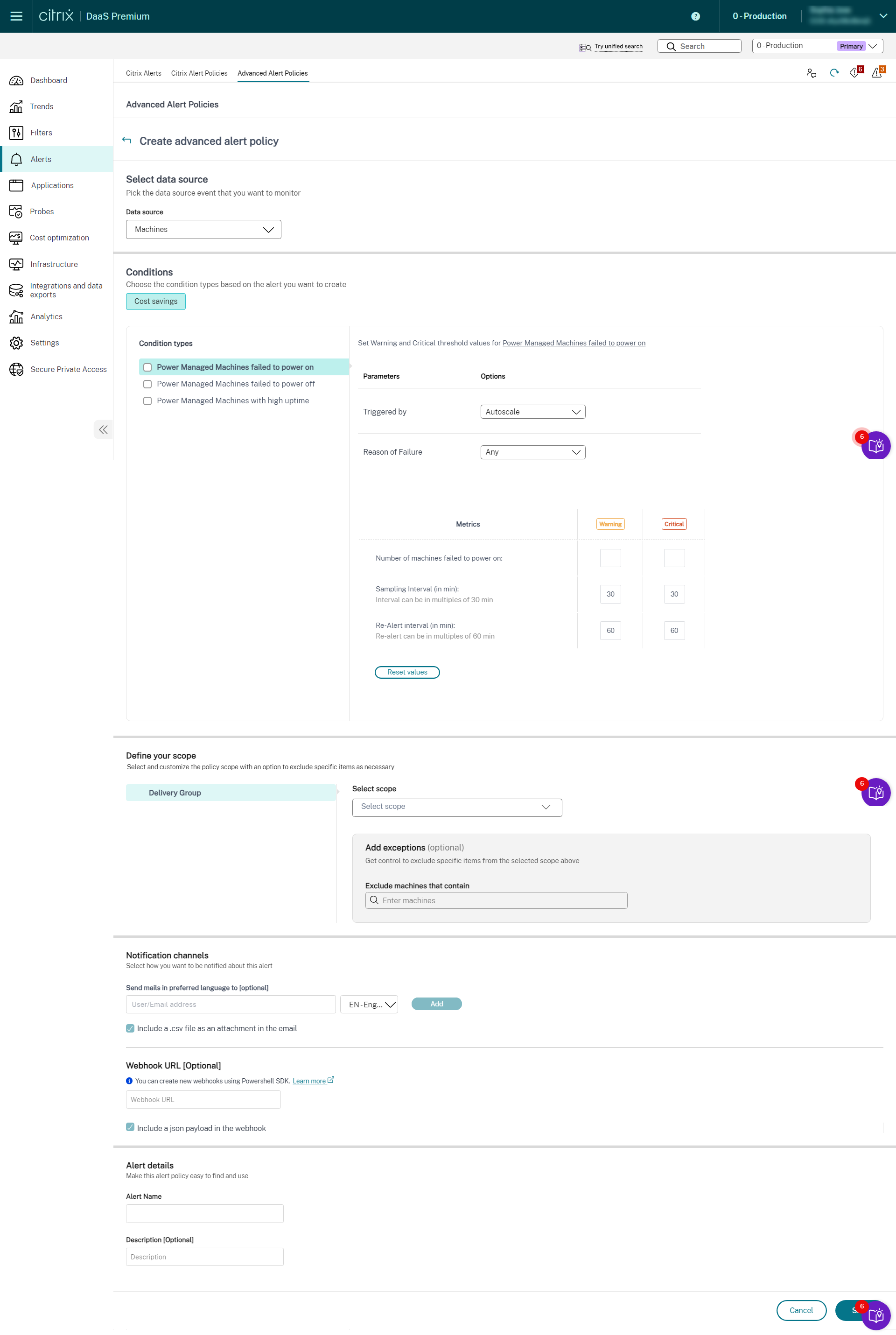
-
Sélectionnez les types de conditions suivants selon vos besoins :
- **Machines gérées par l’alimentation n’ayant pas pu démarrer** - **Machines gérées par l’alimentation n’ayant pas pu s’éteindre** - **Machines gérées par l’alimentation avec une disponibilité élevée**-
- Sélectionnez les paramètres spécifiques et les options correspondantes pour chacune des conditions sélectionnées.
-
-
Définissez les métriques d’avertissement et critiques pour le type de condition sélectionné :
- Pour les **Machines gérées par l’alimentation avec une disponibilité élevée** : - Nombre de machines dépassant le seuil de disponibilité - Intervalle de ré-alerte (en min), l’intervalle peut être d’un minimum de 60 min-
Pour les Machines gérées par l’alimentation n’ayant pas pu démarrer et les Machines gérées par l’alimentation n’ayant pas pu s’éteindre :
- Nombre de machines dépassant le seuil de disponibilité
- Intervalle d’échantillonnage (en min), les intervalles peuvent être des multiples de 30 min
- Intervalle de ré-alerte (en min), la ré-alerte peut être des multiples de 60 min
-
- Planifiez les intervalles de ré-alerte pour les alertes sélectionnées selon vos besoins.
- Définissez la portée de l’alerte.
-
Définissez les canaux de notification. Il peut s’agir d’un e-mail ou d’un Webhook.
-
Vous pouvez cocher les cases suivantes :
- Inclure une charge utile JSON en pièce jointe dans le webhook
- Inclure un fichier CSV en pièce jointe dans l’e-mail
-
- Saisissez les Détails de l’alerte tels que le Nom de l’alerte et la Description (facultatif).
-
- Cliquez sur Enregistrer. L’alerte est créée.
Alertes pour la latence de connexion SPA
Le cadre des stratégies d’alerte avancées prend en charge les alertes proactives pour la connectivité Secure Private Access (SPA). Utilisez cette stratégie pour détecter et agir sur la latence de bout en bout affectant les connexions utilisateur SPA.
Configurer l’alerte de latence de connexion SPA
- Pour créer des alertes de latence de connexion SPA, procédez comme suit :
- 1. Cliquez sur l'onglet **Alertes** > **Stratégies d'alerte avancées**. La page **Stratégies d'alerte avancées** s'affiche.
- Cliquez sur Créer une stratégie. La section Créer des stratégies d’alerte avancées s’affiche.
- Sélectionnez Secure Private Access dans la liste déroulante Source de données. La condition Latence de connexion SPA s’affiche.
-
Sélectionnez les types de métriques suivants selon vos besoins :
- Latence FAI (Client → CDN)
- Latence de connexion (Client → PoP de passerelle)
- Latence FAI (Client → CDN)
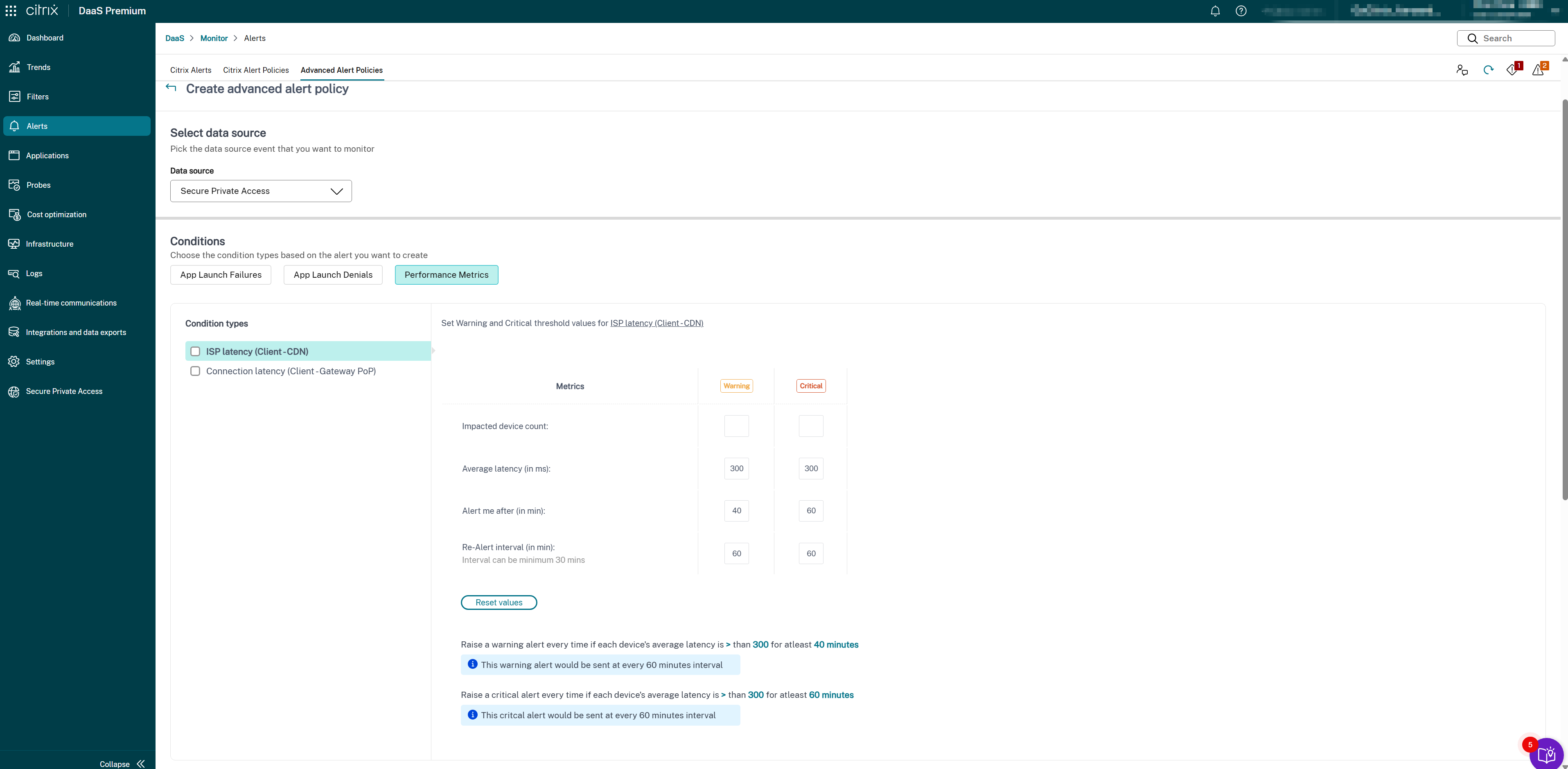
- Latence de connexion (Client → PoP de passerelle)
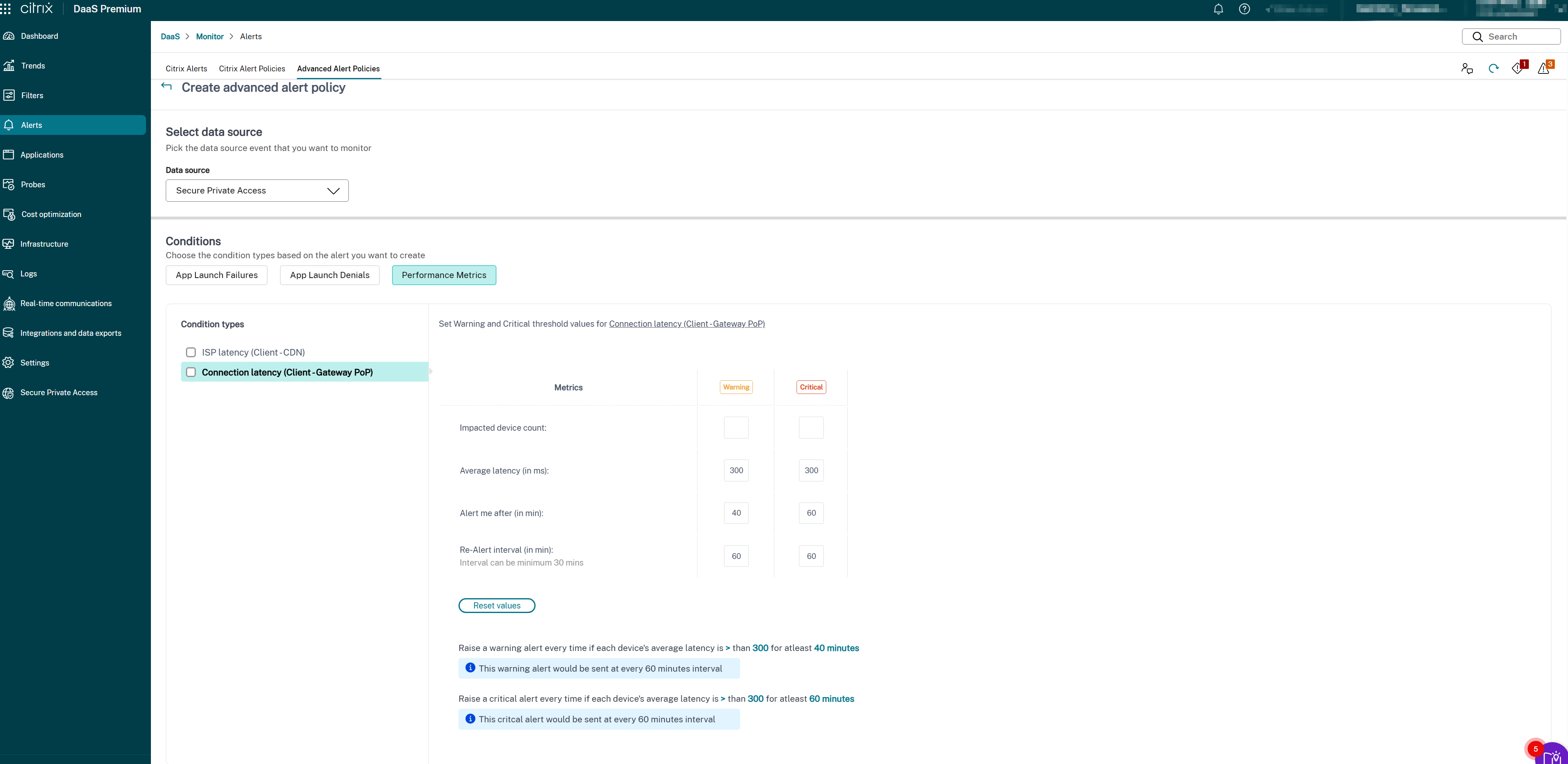
- Sélectionnez les paramètres spécifiques et les options correspondantes pour chacune des métriques sélectionnées.
-
Définissez les métriques d’avertissement et critiques pour le type de condition sélectionné :
- Seuil de latence (en ms) : Définissez les valeurs d’avertissement (par exemple, 150–200 ms) et critiques (par exemple, 300–400 ms)
- Utilisateurs impactés (nombre) : Nombre d’utilisateurs subissant une latence supérieure au seuil
- Intervalle d’échantillonnage (en min) : Fréquence d’évaluation de la latence (par exemple, 5–15 minutes)
- Intervalle de ré-alerte (en min) : Minimum 60 minutes recommandé pour éviter la fatigue d’alerte
- Planifiez les intervalles de ré-alerte pour les alertes sélectionnées selon vos besoins.
- Définissez la portée de l’alerte. Sélectionnez le site, le groupe de mise à disposition ou le sous-ensemble ciblé.
-
Définissez les canaux de notification. Il peut s’agir d’un e-mail ou d’un Webhook.
-
Vous pouvez cocher les cases suivantes :
- Inclure une charge utile JSON en pièce jointe dans le webhook
- Inclure un fichier CSV en pièce jointe dans l’e-mail
-
- Saisissez les Détails de l’alerte tels que le Nom de l’alerte (par exemple, « Latence de connexion SPA – PoP Est ») et la Description (facultatif).
- Cliquez sur Enregistrer. L’alerte est créée.
Recommandation :
Pour une alerte proactive, ajustez les seuils de latence en fonction des mesures de référence par région. Incluez l’intégration de webhook pour acheminer les alertes de latence élevée vers la gestion des incidents pour un triage plus rapide.
Stratégies d’infrastructure
Vous pouvez créer des alertes pour surveiller l’état des composants Citrix DaaS™ pris en charge suivants :
- Service de provisioning
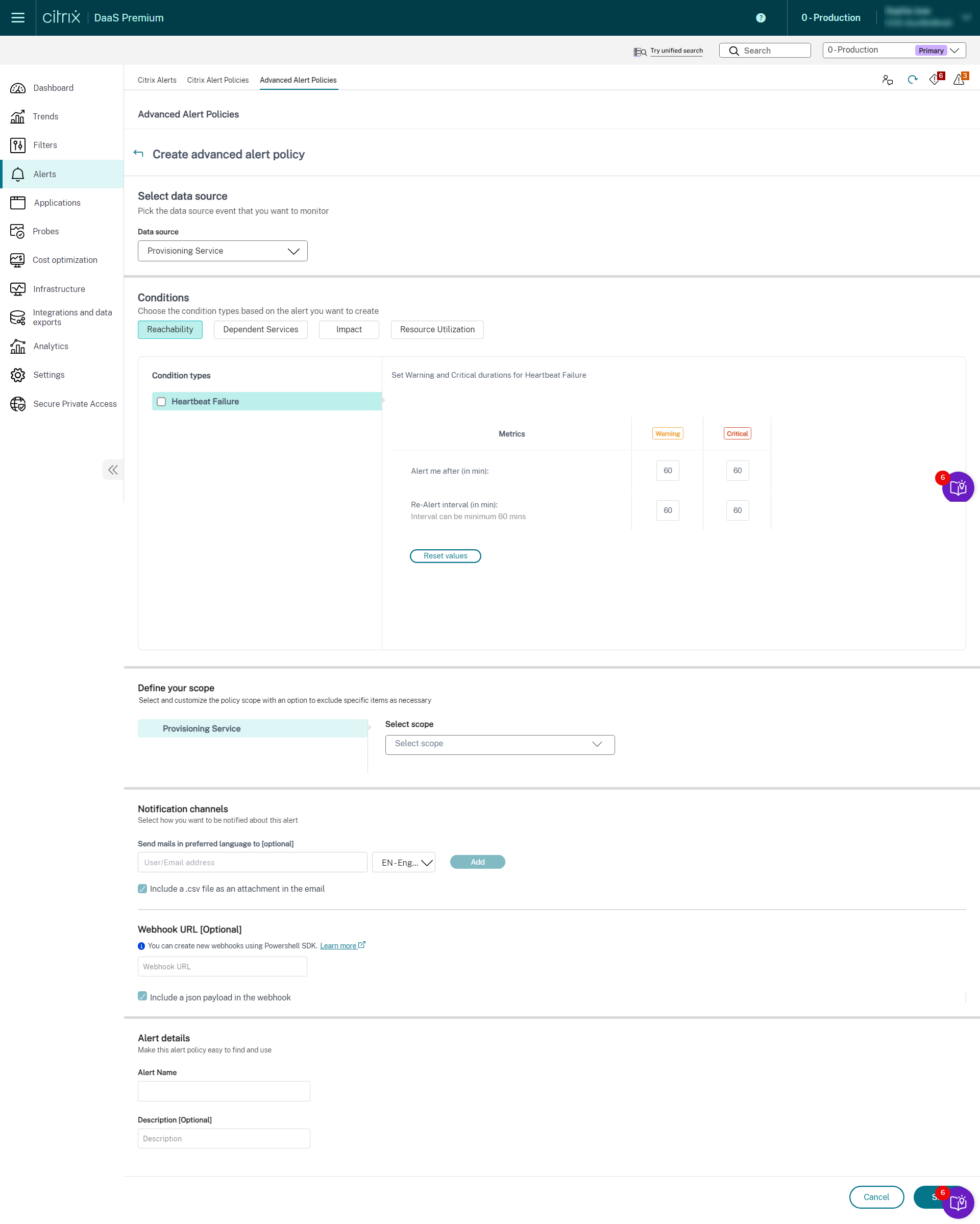
- StoreFront
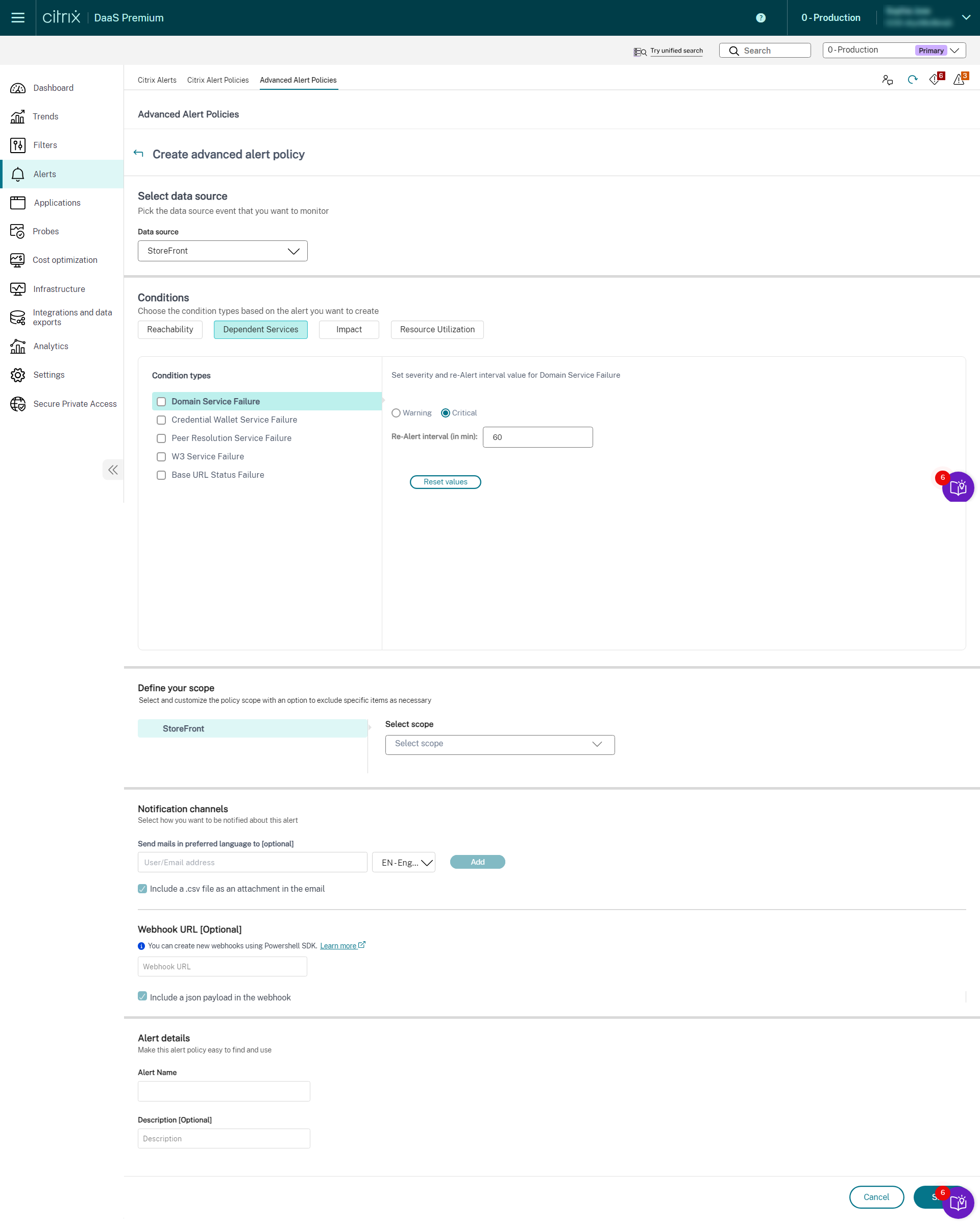
- Cloud Connector
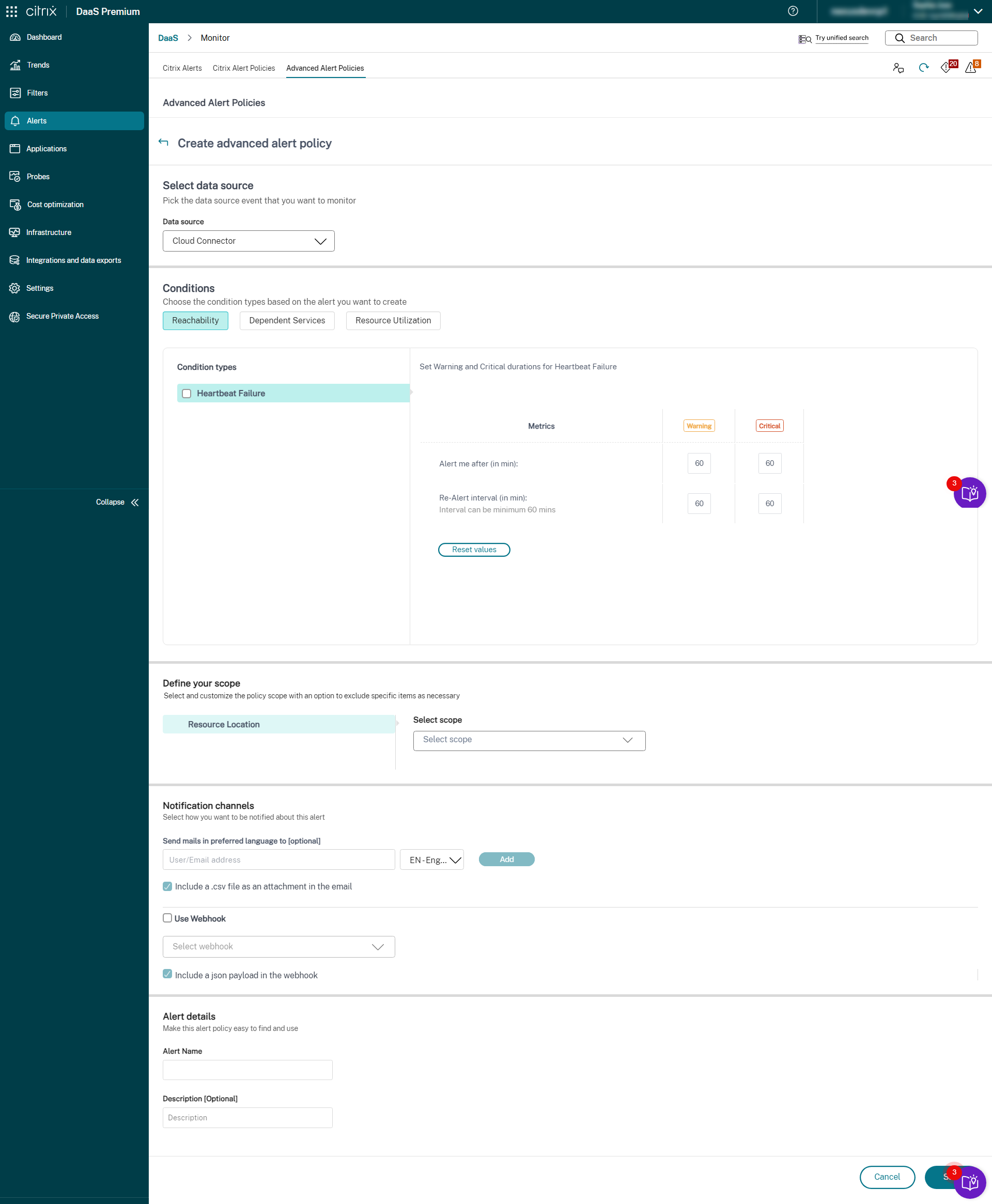
- Connector Appliance
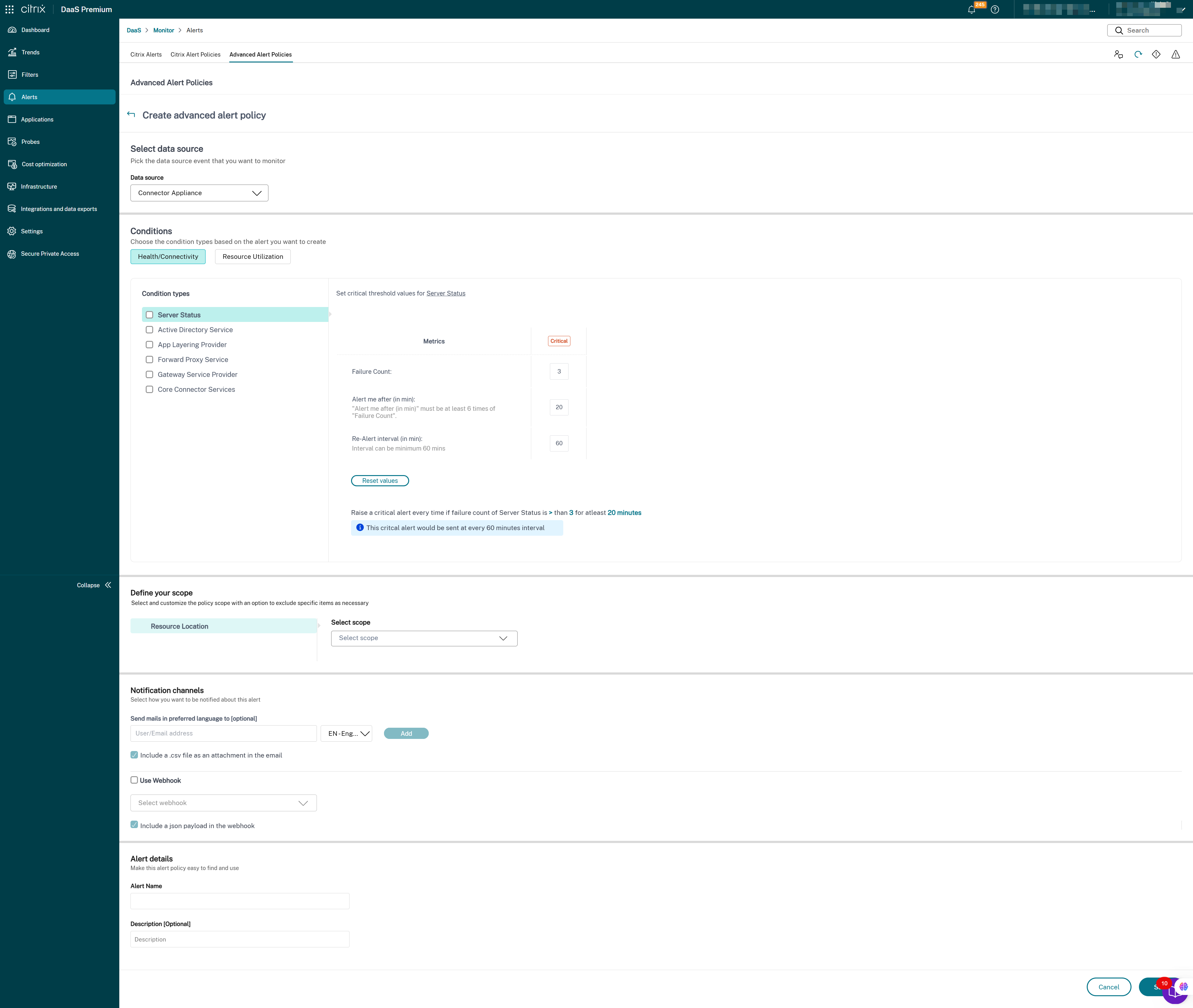
Une fois la configuration de la surveillance de l’infrastructure terminée, vous pouvez utiliser les données d’état disponibles dans Monitor pour configurer des alertes pour tout composant requis. Les administrateurs peuvent définir des conditions, des portées et des supports de notification pour recevoir des alertes importantes par e-mail ou une charge utile JSON via des webhooks. Les alertes déclenchées sont également disponibles dans la section Alertes Citrix pour analyse et gestion.
Dans le cadre de la stratégie d’infrastructure nouvellement introduite, les conditions d’alerte sont classées en quatre sections comme suit :
- Accessibilité
- Services dépendants
- Impact
- Utilisation des ressources
Les conditions de chaque catégorie peuvent être définies avec la gravité Critique et Avertissement en fonction des priorités de votre organisation. Vous pouvez également planifier des intervalles de ré-alerte pour ces alertes.
Vous pouvez créer une stratégie d’infrastructure à partir de la section Alertes > Stratégies d’alerte Citrix. Vous pouvez sélectionner la catégorie requise, puis sélectionner les conditions requises pour la stratégie. Pour plus d’informations sur la création d’une stratégie, consultez Créer des stratégies d’alerte. Une fois la stratégie créée, vous pouvez la modifier, la supprimer ou la désactiver sur la page Alertes Citrix.
Pour plus de détails sur les conditions prises en charge dans chaque catégorie et composant, consultez les éléments suivants :
- Métriques d’état du provisioning
- Métriques d’état de StoreFront
- Métriques d’état de Cloud Connector
- Métriques d’état de Connector Appliance
Les données suivantes sont reçues sous forme d’alerte par e-mail ou sur la page Alertes Citrix :
| Champ | Description |
|---|---|
| ID client | L’ID client du site. |
| Niveau d’alerte | Les valeurs possibles sont Critique et Avertissement. |
| Cible | Le nom de la machine pour laquelle l’alerte est déclenchée. |
| Heure | L’heure à laquelle l’alerte est déclenchée. |
| Portée | La portée de la stratégie. |
| Stratégie | Le nom de la stratégie. |
| Description | La description du problème pour lequel l’alerte est déclenchée. |
Définir la portée de la stratégie
Vous pouvez définir la portée de votre alerte et ajouter des exceptions. L’alerte est générée uniquement pour la portée sélectionnée et la sous-portée exclue à l’aide des exceptions n’est pas incluse dans la génération d’alertes. Cette fonctionnalité vous aide à créer des alertes à un niveau granulaire.
Vous pouvez créer des notifications par e-mail ou via des URL de webhook. Vous pouvez également sélectionner votre langue préférée dans laquelle vous souhaitez recevoir les alertes. Vous pouvez également sélectionner une option pour recevoir les paramètres d’alerte dans un fichier .CSV joint à l’e-mail ou dans une charge utile JSON via une URL de webhook. La pièce jointe contient les détails des paramètres requis. Pour plus d’informations, consultez Améliorations du contenu des alertes.
Les données suivantes sont reçues sous forme d’alerte par e-mail ou sur la page Alertes Citrix :
| Champ | Description |
|---|---|
| ID client | L’ID client du site. |
| Niveau d’alerte | Cette valeur est la valeur prédéfinie pour chaque condition d’alerte. Les valeurs possibles sont Critique et Avertissement. |
-
Condition Cette valeur est la condition définie lors de la création de la stratégie. Par exemple, le nombre de machines non enregistrées est égal ou supérieur à 20. -
Cible Le nom du groupe de mise à disposition ou du site pour lequel l’alerte est déclenchée. -
Site Le nom du site. -
Étendue L’étendue de la stratégie. Cette valeur inclut également la sous-étendue.
| Stratégie | Le nom de la stratégie. |
-
Description La description du problème pour lequel l’alerte est déclenchée.
Comment créer une stratégie d’alerte avancée à l’aide d’un script PowerShell ?
Script PowerShell pour créer une stratégie d’alerte :
asnp Citrix.Monitor.*
# Add Parameters
$timeSpan = New-TimeSpan -Seconds 30
$alertThreshold = 1
$alarmThreshold = 2
# Add Target UID's
$targetIds = @()
$targetIds += "e9a211b4-a1f3-4f74-b6c7-85225902e997"
# Add email addresses
$emailaddress = @()
$emailaddress += "loki@abc.com"
# Create new policy
$policy = New-MonitorNotificationPolicy -Name "FailedMachinePercentageAlertCreationViaPowershell" -Description "Policy created to test urm" -Enabled $true
<!--NeedCopy-->
Remplacez la ligne suivante par la condition correcte pour FailedMachinePercentage
Add-MonitorNotificationPolicyCondition -Uid $policy.Uid -ConditionType FailedMachinePercentage -AlertThreshold $alertThreshold -AlarmThreshold $alarmThreshold -AlertRenotification $timeSpan -AlarmRenotification $timeSpan
Add-MonitorNotificationPolicyTargets -Uid $policy.Uid -Scope "DG-Multisession" -TargetKind DesktopGroup -TargetIds $targetIds
$policy = Get-MonitorNotificationPolicy -Uid $policy.Uid
$policy
<!--NeedCopy-->
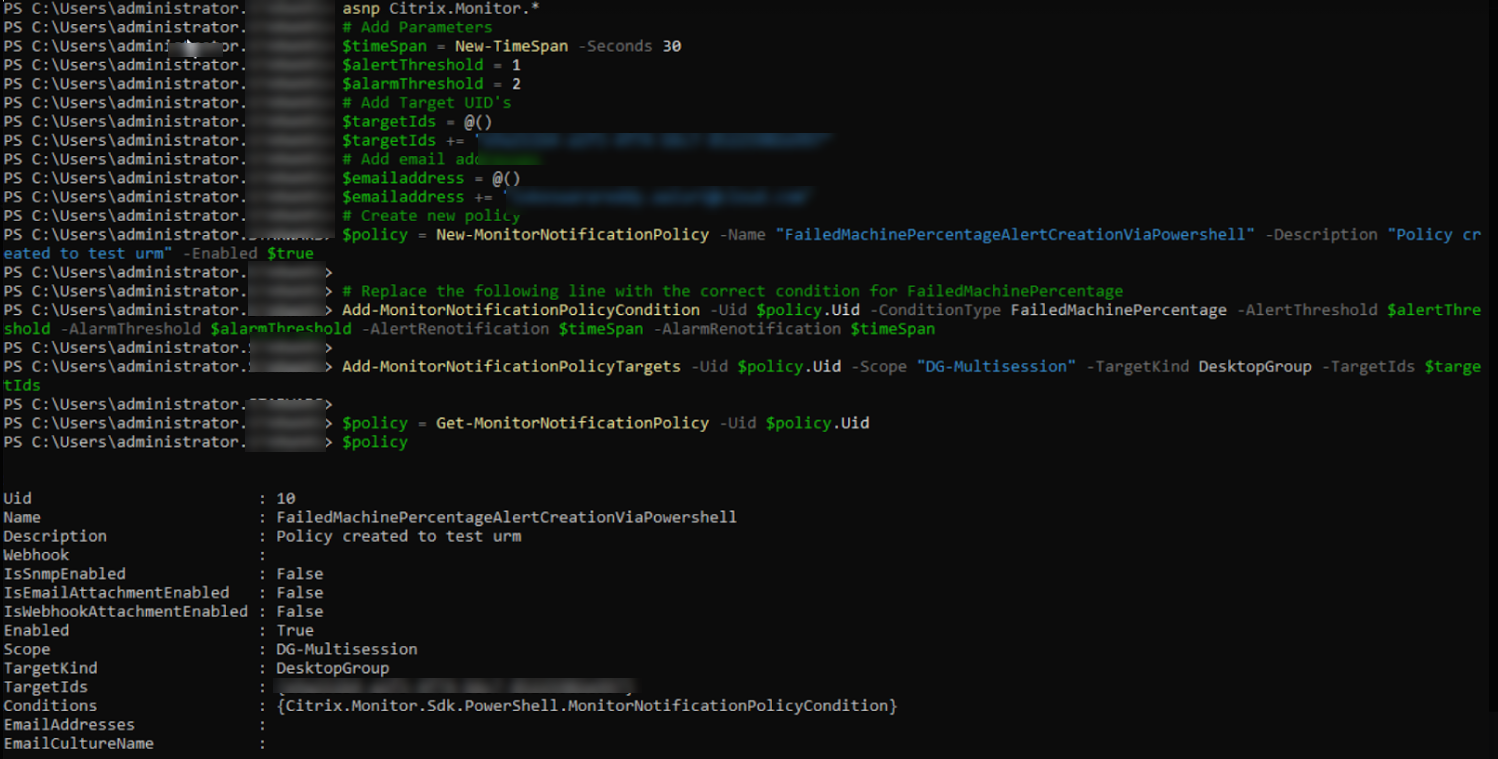
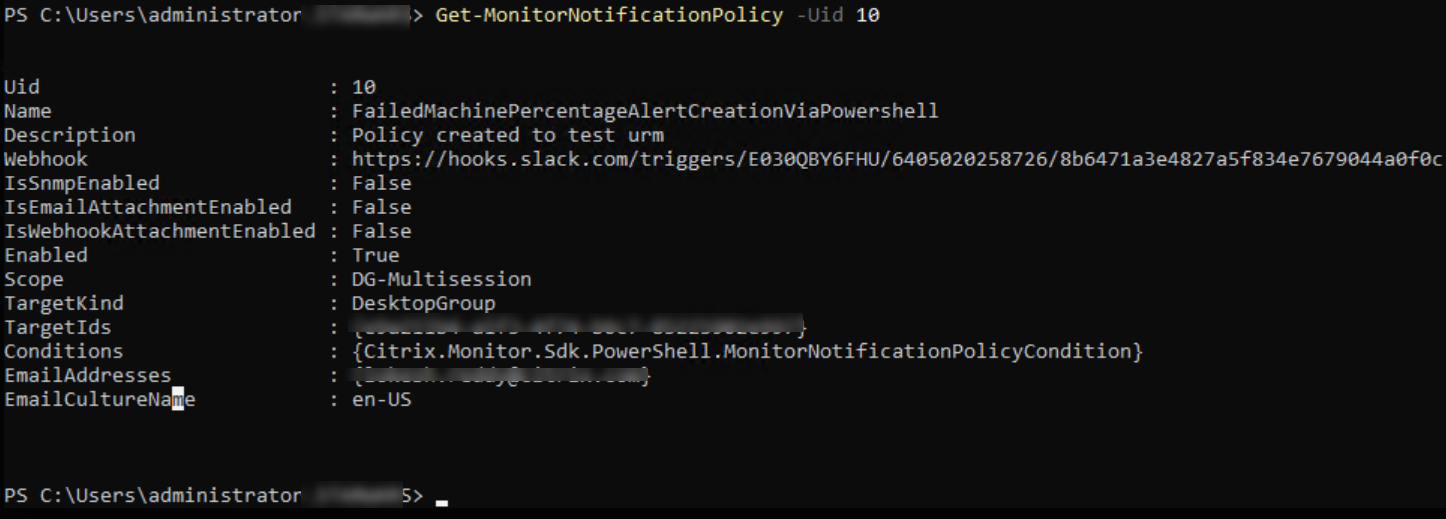
D’après l’image précédente, vous pouvez voir que la stratégie est créée et que l’Uid est 10.
Pour ajouter un e-mail à la configuration
Set-MonitorNotificationEmailServerConfiguration -ProtocolType SMTP -ServerName NameOfTheSMTPServerOrIPAddress -PortNumber 80 -SenderEmailAddress loki@abc.com -RequiresAuthentication 0
<!--NeedCopy-->
Pour ajouter un e-mail à la stratégie
- Add-MonitorNotificationPolicyEmailAddresses -Uid $policy.Uid -EmailAddresses $emailaddress -EmailCultureName "en-US"
- <!--NeedCopy-->
-
Exemple de script pour ajouter un e-mail :
-
```
- Add-MonitorNotificationPolicyEmailAddresses -Uid 10 -EmailAddresses $emailaddress -EmailCultureName “en-US”
-
```

Pour ajouter une URL de webhook à la stratégie
- ```
- Set-MonitorNotificationPolicy –Uid $polcy.Uid –Webhook ‘URL’

- **Exemple de script pour ajouter une URL de webhook :**
Set-MonitorNotificationPolicy –Uid 10 –Webhook ‘https://hooks.slack.com/triggers/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’
#### Obtenir les détails de la stratégie créée
Get-MonitorNotificationPolicy -Uid 10
- 
## Créer des stratégies d'alerte
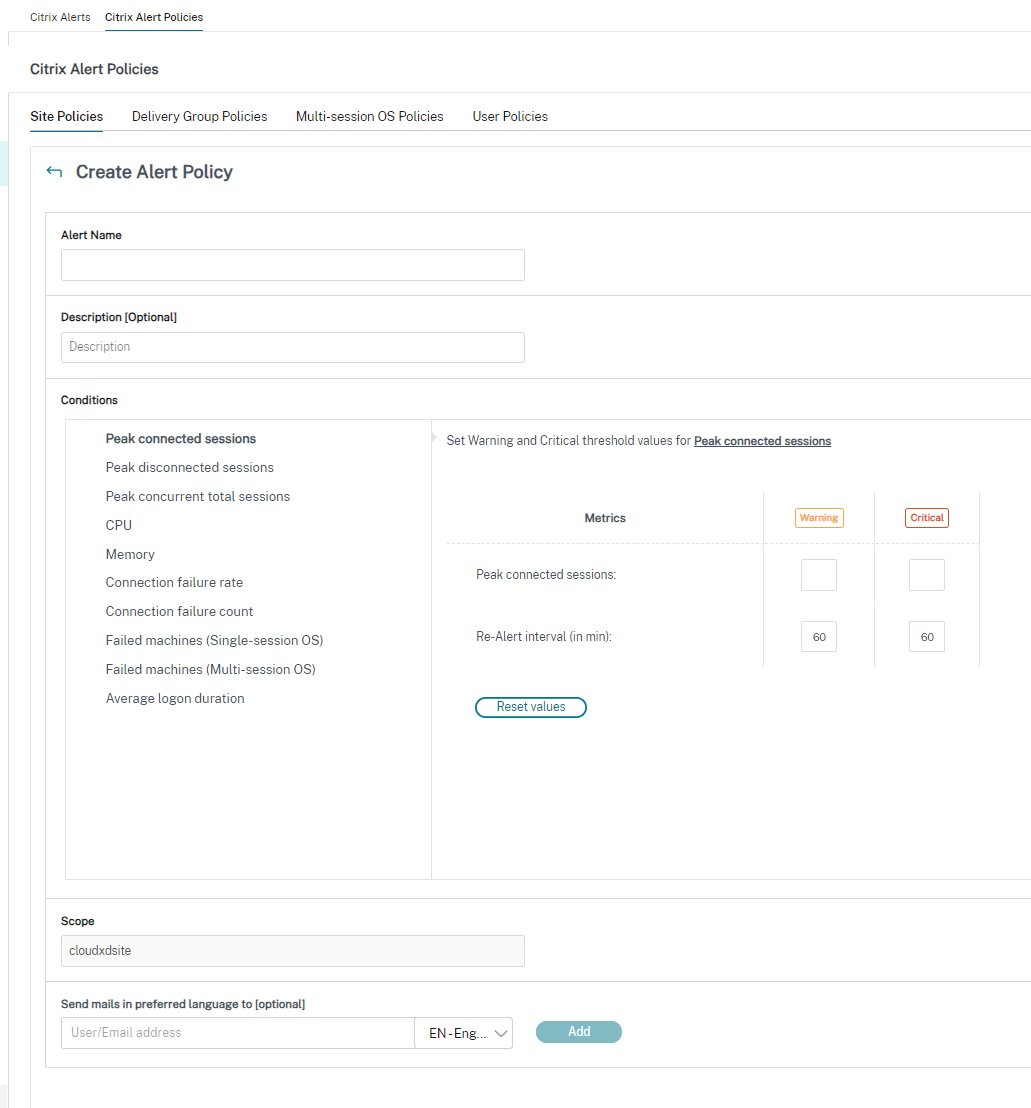
Pour créer une stratégie d'alerte, par exemple, pour générer une alerte lorsqu'un ensemble spécifique de critères de nombre de sessions est rempli :
1. Accédez à **Alertes** \> **Stratégie d'alertes Citrix** et sélectionnez, par exemple, Stratégie de SE multisession.
1. Cliquez sur **Créer**.
1. Nommez et décrivez la stratégie, puis définissez les conditions qui doivent être remplies pour que l'alerte soit déclenchée. Par exemple, spécifiez les nombres d'avertissements et critiques pour les sessions connectées maximales, les sessions déconnectées maximales et le total des sessions concurrentes maximales. Les valeurs d'avertissement ne doivent pas être supérieures aux valeurs critiques. Pour plus d'informations, consultez [Conditions des stratégies d'alerte](/fr-fr/citrix-daas/monitor/site-analytics/alerts-notifications.html#alerts-policies-conditions).
1. Définissez l'intervalle de ré-alerte. Si les conditions de l'alerte sont toujours remplies, l'alerte est déclenchée à nouveau à cet intervalle de temps et, si elle est configurée dans la stratégie d'alerte, une notification par e-mail est générée. Une alerte ignorée ne génère pas de notification par e-mail à l'intervalle de ré-alerte.
1. Définissez l'étendue. Par exemple, définissez-la pour un groupe de mise à disposition spécifique.
1. Dans les préférences de notification, spécifiez qui doit être averti par e-mail lorsque l'alerte est déclenchée. Les notifications par e-mail sont envoyées via SendGrid. Assurez-vous que l'adresse e-mail `donotreplynotifications@citrix.com` est ajoutée à la liste blanche de votre configuration de messagerie.
1. Cliquez sur **Enregistrer**.
La création d'une stratégie avec 20 groupes de mise à disposition ou plus définis dans l'étendue peut prendre environ 30 secondes pour terminer la configuration. Un indicateur de chargement s'affiche pendant ce temps.
La création de plus de 50 stratégies pour un maximum de 20 groupes de mise à disposition uniques (1000 cibles de groupes de mise à disposition au total) peut entraîner une augmentation du temps de réponse (plus de 5 secondes).
Le déplacement d'une machine contenant des sessions actives d'un groupe de mise à disposition à un autre peut déclencher des alertes de groupe de mise à disposition erronées définies à l'aide de paramètres de machine.
>**Remarque :**
>
>Après la suppression d'une stratégie d'alerte, il peut s'écouler jusqu'à 30 minutes avant que les notifications d'alerte générées par la stratégie ne cessent.
### Améliorations du contenu des alertes
La fonctionnalité d'alerte du Moniteur est améliorée pour inclure une pièce jointe CSV et une charge utile JSON. Grâce à cette amélioration, vous pouvez obtenir les détails de l'alerte dans une pièce jointe CSV par e-mail ou sous forme de charge utile JSON s'il existe un webhook. L'utilisation de cette pièce jointe CSV ou de cette charge utile JSON vous permet de recevoir un contenu enrichi à un niveau détaillé, ce qui facilite l'identification et la résolution rapides des problèmes.
Actuellement, cette amélioration est disponible uniquement pour les alertes suivantes :
- Temps de disponibilité de la machine
- Actions de mise sous tension ayant échoué
- Actions de mise hors tension ayant échoué
- Machines non enregistrées (%)
Pour utiliser cette fonctionnalité, accédez à l'alerte et cochez les cases suivantes :
- **Inclure une charge utile JSON en pièce jointe dans le webhook**
- **Inclure un fichier CSV en pièce jointe dans l'e-mail**
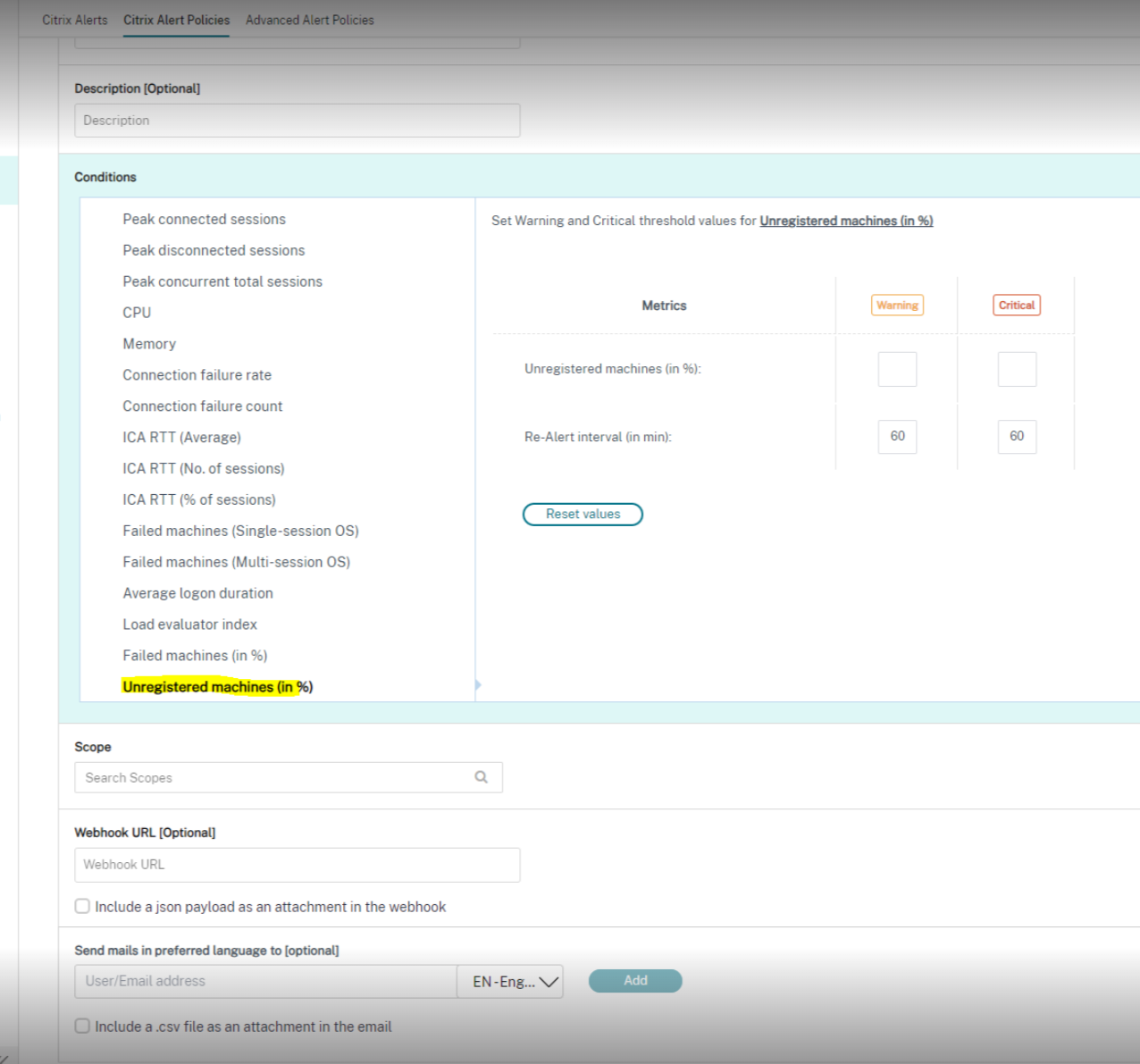
Voici une capture d'écran de la section **Stratégies d'alerte Citrix** :
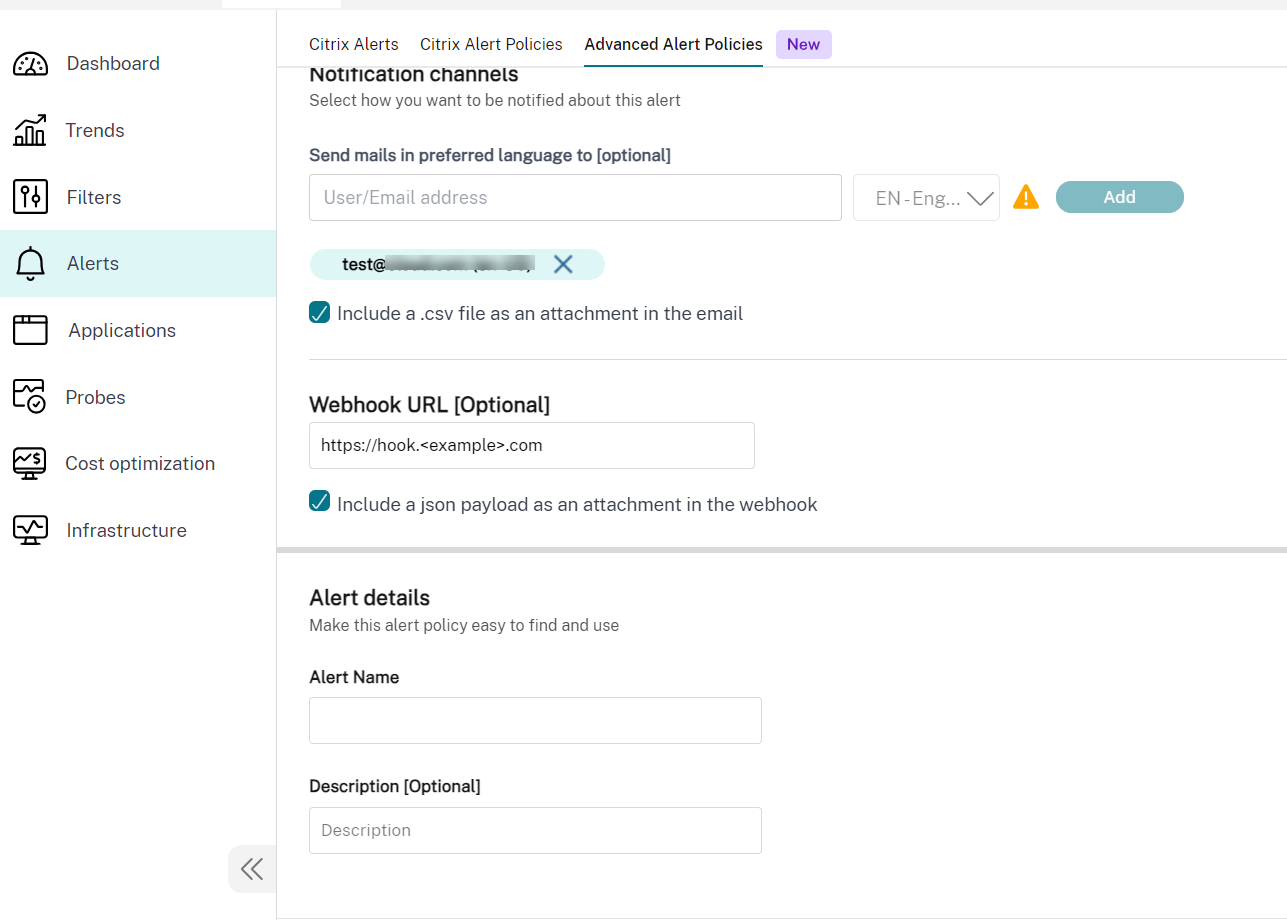
Voici une capture d'écran de la section **Stratégies d'alerte avancées** :
#### Pièce jointe CSV
Le tableau suivant fournit les colonnes de la pièce jointe .CSV pour toutes les alertes prises en charge :
|Colonne|Alerte applicable|
|--|--|
|Nom de la machine, adresse IP et nom du groupe de mise à disposition|Temps de disponibilité de la machine, action d'arrêt échouée et action de démarrage échouée, et machines non enregistrées \(%)|
|État d'enregistrement actuel, date d'échec, état de panne et état du cycle de vie|Machine non enregistrée \(%)|
- |Raison du dernier échec d'action d'alimentation, déclencheur de la dernière action d'alimentation, type de la dernière action d'alimentation et date de fin de la dernière action d'alimentation|Action d'arrêt échouée et action de démarrage échouée|
- |État d'alimentation, date de mise sous tension et temps de disponibilité total en minutes|Temps de disponibilité de la machine|
#### Charge utile du webhook
##### Alerte de pourcentage de machines non enregistrées
{
“text”: “{"Address":"
##### Alerte d'actions de démarrage échouées
- { "text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Failure To PowerOn Action\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure, HypervisorRateLimitExceeded, UnknownError, Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User, Administrator, Auto-Scale, Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure, HypervisorRateLimitExceeded, UnknownError, Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User, Administrator, Auto-Scale, Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"}]}" }
##### Alerte d'actions d'arrêt échouées
- { "text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Failure To PowerOff Action\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IPV4 Address of the Machine>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure,HypervisorRateLimitExceeded,UnknownError,Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User,Administrator,Auto-Scale,Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IPV4 Address of the Machine>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure,HypervisorRateLimitExceeded,UnknownError,Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User,Administrator,Auto-Scale,Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"}]}" }
##### Alerte de temps de disponibilité de la machine
{
“text”: “{"Address":"
## Conditions des stratégies d'alerte
Vous trouverez ci-dessous les catégories d'alertes, les actions recommandées pour atténuer l'alerte et les conditions de stratégie intégrées, le cas échéant. Les stratégies d'alerte intégrées sont définies pour des intervalles d'alerte et de ré-alerte de 60 minutes.
### Sessions connectées maximales
- Vérifiez la vue Tendances des sessions du Moniteur pour les sessions connectées maximales.
- Assurez-vous qu'il y a suffisamment de capacité pour gérer la charge de sessions.
- Ajoutez de nouvelles machines si nécessaire.
### Sessions déconnectées maximales
- Vérifiez la vue Tendances des sessions du Moniteur pour les sessions déconnectées maximales.
- Assurez-vous qu'il y a suffisamment de capacité pour gérer la charge de sessions.
- Ajoutez de nouvelles machines si nécessaire.
- Déconnectez les sessions déconnectées si nécessaire.
### Sessions concurrentes totales maximales
- Vérifiez la vue Tendances des sessions du Moniteur pour les sessions concurrentes maximales.
- Assurez-vous qu'il y a suffisamment de capacité pour gérer la charge de sessions.
- Ajoutez de nouvelles machines si nécessaire.
- Déconnectez les sessions déconnectées si nécessaire.
### Processeur
- Le pourcentage d'utilisation du processeur indique la consommation globale du processeur sur le VDA, y compris celle des processus. Vous pouvez obtenir plus d'informations sur l'utilisation du processeur par les processus individuels à partir de la page **Détails de la machine** du VDA correspondant.
- Accédez à **Détails de la machine > Afficher l'utilisation historique > 10 premiers processus**, identifiez les processus qui consomment le processeur. Assurez-vous que la stratégie de surveillance des processus est activée pour lancer la collecte des statistiques d'utilisation des ressources au niveau des processus.
- Terminez le processus si nécessaire.
- La fin du processus entraîne la perte des données non enregistrées.
- Si tout fonctionne comme prévu, ajoutez davantage de ressources processeur à l'avenir.
> **Remarque :**
>
> Le paramètre de stratégie, **Activer la surveillance des ressources**, est autorisé par défaut pour la surveillance des compteurs de performance du processeur et de la mémoire sur les machines avec des VDA. Si ce paramètre de stratégie est désactivé, les alertes avec des conditions de processeur et de mémoire ne sont pas déclenchées. Pour plus d'informations, consultez [Paramètres de stratégie de surveillance](/fr-fr/citrix-virtual-apps-desktops/policies/reference/virtual-delivery-agent-policy-settings/monitoring-policy-settings.html).
**Conditions de stratégie intelligentes :**
- **Portée :** Groupe de mise à disposition, portée du système d'exploitation multi-session
- **Valeurs de seuil :** Avertissement - 80 %, Critique - 90 %
### Mémoire
Le pourcentage d'utilisation de la mémoire indique la consommation globale de mémoire sur le VDA, y compris celle des processus. Vous pouvez obtenir plus d'informations sur l'utilisation de la mémoire par les processus individuels à partir de la page **Détails de la machine** du VDA correspondant.
- Accédez à **Détails de la machine > Afficher l'utilisation historique > 10 premiers processus**, identifiez les processus qui consomment de la mémoire. Assurez-vous que la stratégie de surveillance des processus est activée pour lancer la collecte des statistiques d'utilisation des ressources au niveau des processus.
- Terminez le processus si nécessaire.
- La fin du processus entraîne la perte des données non enregistrées.
- Si tout fonctionne comme prévu, ajoutez davantage de mémoire à l'avenir.
> **Remarque :**
>
> Le paramètre de stratégie **Activer la surveillance des ressources**, est autorisé par défaut pour la surveillance des compteurs de performance du processeur et de la mémoire sur les machines avec des VDA. Si ce paramètre de stratégie est désactivé, les alertes avec des conditions de processeur et de mémoire ne sont pas déclenchées. Pour plus d'informations, consultez [Paramètres de stratégie de surveillance](/fr-fr/citrix-virtual-apps-desktops/policies/reference/virtual-delivery-agent-policy-settings/monitoring-policy-settings.html).
**Conditions de stratégie intelligentes :**
- **Portée :** Groupe de mise à disposition, portée du système d'exploitation multi-session
- **Valeurs de seuil :** Avertissement - 80 %, Critique - 90 %
### Taux d'échec de connexion
Pourcentage d'échecs de connexion au cours de la dernière heure.
- Calculé en fonction du nombre total d’échecs par rapport au nombre total de tentatives de connexion.
- Consultez la vue Tendances des échecs de connexion du Moniteur pour les événements enregistrés dans le journal de configuration.
- Déterminez si les applications ou les bureaux sont accessibles.
### Nombre d’échecs de connexion
Nombre d’échecs de connexion au cours de la dernière heure.
- Consultez la vue Tendances des échecs de connexion du Moniteur pour les événements enregistrés dans le journal de configuration.
- Déterminez si les applications ou les bureaux sont accessibles.
### Temps d’aller-retour ICA® (Moyenne)
Temps d’aller-retour ICA moyen.
- Consultez Citrix ADM pour une analyse détaillée du temps d’aller-retour ICA afin de déterminer la cause première. Pour plus d’informations, consultez la documentation de [Citrix ADM](/fr-fr/netscaler-mas/12-1.html).
- Si Citrix ADM n’est pas disponible, consultez la vue Détails de l’utilisateur du Moniteur pour le temps d’aller-retour ICA et la latence, et déterminez s’il s’agit d’un problème réseau ou d’un problème avec les applications ou les bureaux.
### Temps d’aller-retour ICA (Nombre de sessions)
Nombre de sessions qui dépassent le seuil de temps d’aller-retour ICA.
- Consultez Citrix ADM pour connaître le nombre de sessions avec un temps d’aller-retour ICA élevé. Pour plus d’informations, consultez la documentation de [Citrix ADM](/fr-fr/netscaler-mas/12-1.html).
- Si Citrix ADM n’est pas disponible, contactez l’équipe réseau pour déterminer la cause première.
**Conditions de la stratégie intelligente :**
- **Portée :** Groupe de mise à disposition, portée du système d’exploitation multi-session
- **Valeurs de seuil :** Avertissement - 300 ms pour 5 sessions ou plus, Critique - 400 ms pour 10 sessions ou plus
### Temps d’aller-retour ICA (% de sessions)
Pourcentage de sessions qui dépassent le temps d’aller-retour ICA moyen.
- Consultez Citrix ADM pour connaître le nombre de sessions avec un temps d’aller-retour ICA élevé. Pour plus d’informations, consultez la documentation de [Citrix ADM](/fr-fr/netscaler-mas/12-1.html).
- Si Citrix ADM n’est pas disponible, contactez l’équipe réseau pour déterminer la cause première.
### Temps d’aller-retour ICA (Utilisateur)
Temps d’aller-retour ICA appliqué aux sessions lancées par l’utilisateur spécifié. L’alerte est déclenchée si le temps d’aller-retour ICA est supérieur au seuil dans au moins une session.
### Machines défaillantes (OS à session unique)
Nombre de machines OS à session unique défaillantes. Des défaillances peuvent survenir pour diverses raisons, comme indiqué dans les vues Tableau de bord du Moniteur et Filtres.
- Exécutez les diagnostics Citrix Scout pour déterminer la cause première. Pour plus d’informations, consultez [Dépanner les problèmes utilisateur](/fr-fr/citrix-daas/monitor/troubleshoot-deployments/user-issues.html).
**Conditions de la stratégie intelligente :**
- **Portée :** Portée du groupe de mise à disposition
- **Valeurs de seuil :** Avertissement - 1, Critique - 2
### Machines défaillantes (OS multi-session)
Nombre de machines OS multi-session défaillantes. Des défaillances peuvent survenir pour diverses raisons, comme indiqué dans les vues Tableau de bord du Moniteur et Filtres.
- Exécutez les diagnostics Citrix Scout pour déterminer la cause première.
**Conditions de la stratégie intelligente :**
- **Portée :** Groupe de mise à disposition, portée du système d’exploitation multi-session
- **Valeurs de seuil :** Avertissement - 1, Critique - 2
### Machines défaillantes (en %)
Le pourcentage de machines OS à session unique et multi-session défaillantes dans un groupe de mise à disposition, calculé en fonction du nombre de machines défaillantes. Cette condition d’alerte vous permet de configurer des seuils d’alerte sous forme de pourcentage de machines défaillantes dans un groupe de mise à disposition et est calculée toutes les 30 secondes.
Des défaillances peuvent survenir pour diverses raisons, comme indiqué dans les vues Tableau de bord du Moniteur et Filtres. Exécutez les diagnostics Citrix Scout pour déterminer la cause première. Pour plus d’informations, consultez [Dépanner les problèmes utilisateur](/fr-fr/citrix-daas/monitor/troubleshoot-deployments/user-issues.html).
### Action de mise sous tension échouée et action de mise hors tension échouée
Nombre d’actions de mise sous tension échouées et nombre d’actions de mise hors tension échouées dans un groupe de mise à disposition, calculé en fonction du nombre de **machines gérées par l’alimentation** qui n’ont pas pu être mises sous tension ou hors tension. Cette condition d’alerte vous permet de configurer des seuils d’alerte sous forme de nombre de **machines gérées par l’alimentation** qui n’ont pas pu être mises sous tension ou hors tension dans un groupe de mise à disposition et est calculée toutes les 30 minutes.
L’administrateur peut configurer les paramètres suivants pour ces alertes dans la stratégie d’alerte avancée :
- Déclenchée par : Ce qui a déclenché l’action d’alimentation
- Raison de l’échec : Pourquoi l’action a échoué
- Seuil : Nombre seuil de machines dont l’action d’alimentation a échoué pour déclencher la stratégie
- Intervalle d’échantillonnage : L’intervalle dans lequel l’action d’alimentation échouée doit être vérifiée
- Intervalle de ré-alerte : Après combien de temps l’alerte doit être renvoyée
Des défaillances peuvent survenir pour diverses raisons, comme indiqué dans les vues Tableau de bord du Moniteur et Filtres. Exécutez les diagnostics Citrix Scout pour déterminer la cause première. Pour plus d’informations, consultez [Dépanner les problèmes utilisateur](/fr-fr/citrix-daas/monitor/troubleshoot-deployments/user-issues).
### Machines non enregistrées (en %)
Une machine est considérée comme non enregistrée lorsqu’elle devient instable en raison d’un redémarrage ou lorsqu’il y a un problème de communication entre le Delivery Controller™ et les machines virtuelles. Le pourcentage de **machines non enregistrées (en %)** est le pourcentage de machines OS à session unique et multi-session non enregistrées dans un groupe de mise à disposition, calculé en fonction du nombre de machines non enregistrées. Cette condition d’alerte vous permet de configurer des valeurs de seuil d’avertissement et critiques sous forme de pourcentage de machines non enregistrées dans un groupe de mise à disposition. Vous pouvez définir un intervalle pour la ré-alerte. Vous pouvez également ajouter un e-mail pour recevoir une notification lorsque les conditions sont remplies pour les **machines non enregistrées (en %)**. Lorsque la valeur de seuil critique ou d’avertissement est dépassée, des alertes et des e-mails sont générés. Vous pouvez afficher les alertes sous **Alertes Citrix**. Vous pouvez les filtrer par catégorie **Machines non enregistrées (en %)** et pour l’état et l’heure requis.
>**Remarque :**
>
> La valeur critique doit être supérieure à la valeur d’avertissement.
**Conditions de la stratégie :**
- **Portée** : OS à session unique et groupe de mise à disposition OS multi-session
- **Valeurs de seuil** : Avertissement et Critique
### Alerte de disponibilité des machines
La disponibilité des machines dans un groupe de mise à disposition est calculée en fonction du nombre d'heures par jour, par semaine ou par mois pendant lesquelles une machine est allumée dans un groupe de mise à disposition. Cette condition d'alerte vous permet de configurer des seuils d'alerte en fonction du nombre d'heures pendant lesquelles une machine est allumée dans un groupe de mise à disposition. Les alertes de disponibilité des machines fonctionnent comme suit dans les cas suivants :
- Heures par jour - Vous pouvez spécifier le nombre d'heures pendant lesquelles une machine est allumée par jour. Ce nombre est calculé toutes les 30 minutes. Le nombre maximal d'heures par jour que vous pouvez définir est de 24 heures.
- Heures par semaine - Vous pouvez spécifier le nombre d'heures pendant lesquelles une machine est allumée par semaine. Ce nombre est calculé toutes les six heures. Le nombre maximal d'heures par semaine que vous pouvez définir est de 168 heures.
- Heures par mois - Vous pouvez spécifier le nombre d'heures pendant lesquelles une machine est allumée par mois. Ce nombre est calculé une fois par jour. Le nombre maximal d'heures par mois est de 720 heures.
La valeur minimale de l'intervalle de ré-alerte que vous pouvez définir est de 60 minutes. Vous pouvez saisir le nombre de machines qui dépassent la valeur seuil de disponibilité des machines dans la section Alertes d'avertissement et critiques. Vous pouvez également ajouter des exceptions pour certaines machines.
Par exemple, si cinq groupes de mise à disposition sont ajoutés pour cette alerte et si, dans le premier et le quatrième groupe de mise à disposition, le nombre de machines dépasse les valeurs seuils d'avertissement ou critiques, l'alerte est déclenchée séparément pour le premier groupe de mise à disposition et pour le quatrième groupe de mise à disposition.
Cette alerte aide les administrateurs à analyser la disponibilité des machines et, sur la base de cette analyse, les administrateurs peuvent contribuer à optimiser les coûts. Vous pouvez également recevoir les détails de l'alerte dans une pièce jointe CSV dans un e-mail ou via une charge utile JSON dans le cas d'un webhook.
### Durée moyenne d'ouverture de session
- Durée moyenne d'ouverture de session pour les ouvertures de session qui ont eu lieu au cours de la dernière heure.
- Consultez le tableau de bord de Monitor pour obtenir des métriques à jour concernant la durée d'ouverture de session. Un grand nombre d'utilisateurs se connectant pendant une courte période peut augmenter la durée d'ouverture de session.
- Vérifiez la ligne de base et la répartition des ouvertures de session pour en identifier la cause. Pour plus d'informations, consultez [Diagnostiquer les problèmes d'ouverture de session utilisateur](/fr-fr/citrix-daas/monitor/troubleshoot-deployments/user-issues/user-logon.html).
**Conditions de stratégie intelligente :**
- **Portée :** Groupe de mise à disposition, portée du système d'exploitation multi-session
- **Valeurs seuils :** Avertissement - 45 secondes, Critique - 60 secondes
### Durée d'ouverture de session (utilisateur)
Durée d'ouverture de session pour les ouvertures de session de l'utilisateur spécifié qui ont eu lieu au cours de la dernière heure.
### Index de l'évaluateur de charge
Valeur de l'index de l'évaluateur de charge au cours des 5 dernières minutes.
- Vérifiez dans Monitor les machines de système d'exploitation multi-session qui pourraient avoir une charge de pointe (charge maximale). Affichez à la fois le tableau de bord (échecs) et le rapport de l'index de l'évaluateur de charge des tendances.
**Conditions de stratégie intelligente :**
- **Portée :** Groupe de mise à disposition, portée du système d'exploitation multi-session
- **Valeurs seuils :** Avertissement - 80 %, Critique - 90 %
## Configurer les stratégies d'alerte avec des webhooks
Outre les notifications par e-mail, vous pouvez configurer des stratégies d'alerte avec des webhooks.
**Remarque:** Cette fonctionnalité nécessite la version 7.11 ou ultérieure du ou des Delivery Controller(s).
Vous pouvez configurer une stratégie d'alerte avec un rappel HTTP ou une requête HTTP POST à l'aide de cmdlets PowerShell. Elles sont étendues pour prendre en charge les webhooks.
Pour plus d'informations sur la création d'un nouveau workflow Octoblu et l'obtention de l'URL de webhook correspondante, consultez le [Octoblu Developer Hub](https://octoblu.readme.io/docs/api-guide).
Pour configurer une URL de webhook pour une nouvelle stratégie d'alerte ou pour une stratégie existante, utilisez les cmdlets PowerShell suivantes.
Créer une stratégie d'alerte avec une URL de webhook :
$policy = New-MonitorNotificationPolicy -Name
Ajouter une URL de webhook à une stratégie d'alerte existante :
Set-MonitorNotificationPolicy - Uid
Pour obtenir de l'aide sur les commandes **PowerShell**, utilisez l'aide PowerShell, par exemple :
Get-Help
Les notifications générées par la stratégie d'alerte déclenchent le webhook avec un appel POST à l'URL du webhook. Le message POST contient les informations de notification au format JSON :
{“NotificationId” : <Notification Id>,
“Target” : <Notification Target Id>,
“Condition” : <Condition that was violated>,
“Value” : <Threshold value for the Condition>,
“Timestamp”: <Time in UTC when notification was generated>,
“PolicyName”: <Name of the Alert policy>,
“Description”: <Description of the Alert policy>,
“Scope” : <Scope of the Alert policy>,
“NotificationState”: <Notification state critical, warning, healthy or dismissed>,
“Site” : <Site name>}
### Configurer les stratégies d'alerte avec ServiceNow
Vous pouvez configurer des stratégies d'alerte pour envoyer des notifications directement à ServiceNow (SNOW), permettant une intégration transparente avec vos workflows de gestion des services informatiques (ITSM). Cette intégration permet aux alertes générées dans Citrix Monitor d'être automatiquement transmises à ServiceNow pour un suivi centralisé, une escalade et une résolution des incidents.
#### Avantages de l'intégration ServiceNow
- **Gestion unifiée des alertes** : Créez, mettez à jour et gérez les incidents ServiceNow directement dans l'interface Citrix Monitor sans basculer entre les systèmes.
- **Configuration ITSM automatique** : Monitor récupère automatiquement la configuration ServiceNow requise, telle que les URL de webhook, réduisant ainsi la complexité de la configuration manuelle.
- **Réponse rationalisée aux incidents** : Les alertes sont transmises à ServiceNow pour un suivi et une résolution centralisés des incidents, améliorant ainsi l'efficacité opérationnelle.
#### Prérequis
Avant de configurer l'intégration ServiceNow, assurez-vous des éléments suivants :
- Une instance ServiceNow est configurée dans le service ITSM Adapter.
- Vous disposez des autorisations nécessaires pour gérer les stratégies d'alerte dans Monitor.
#### Vérifier l'état de l'intégration ServiceNow
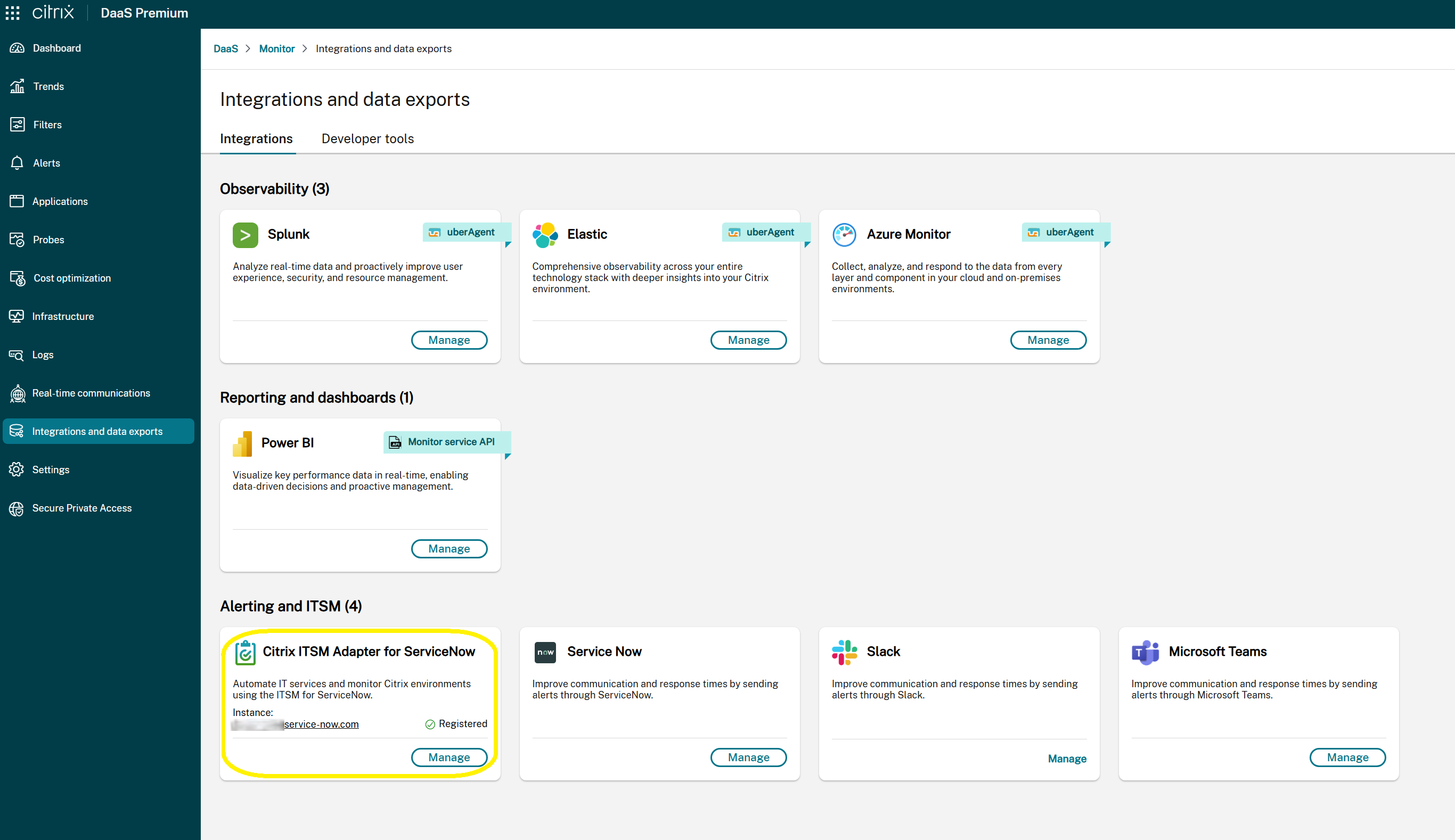
Vous pouvez consulter l’état de l’intégration avec le service ITSM Adapter sur la page **Surveiller** > **Intégrations et exportations de données**. Cette page affiche les informations suivantes :
- L’état actuel de l’intégration :
- **Démarrer** : indique que l’intégration d’ITSM Adapter n’a pas été configurée. Sélectionnez cette option pour lancer le processus de configuration initiale.
- **Gérer** : indique que l’intégration d’ITSM Adapter est active et opérationnelle. Sélectionnez cette option pour afficher ou modifier vos paramètres d’intégration ServiceNow.
- L’URL de l’instance ServiceNow associée (visible uniquement lorsqu’une instance ServiceNow a été configurée dans ITSM Adapter).
#### Configurer une stratégie d’alerte avec les notifications ServiceNow
Pour configurer une stratégie d’alerte afin d’envoyer des notifications à ServiceNow :
1. Accédez à **Alertes** > **Stratégie d’alertes Citrix** et sélectionnez la catégorie de stratégie (par exemple, Stratégie de système d’exploitation multisession).
1. Cliquez sur **Créer** pour créer une nouvelle stratégie ou sélectionnez une stratégie existante et cliquez sur **Modifier**.
1. Configurez les conditions de la stratégie selon vos besoins.
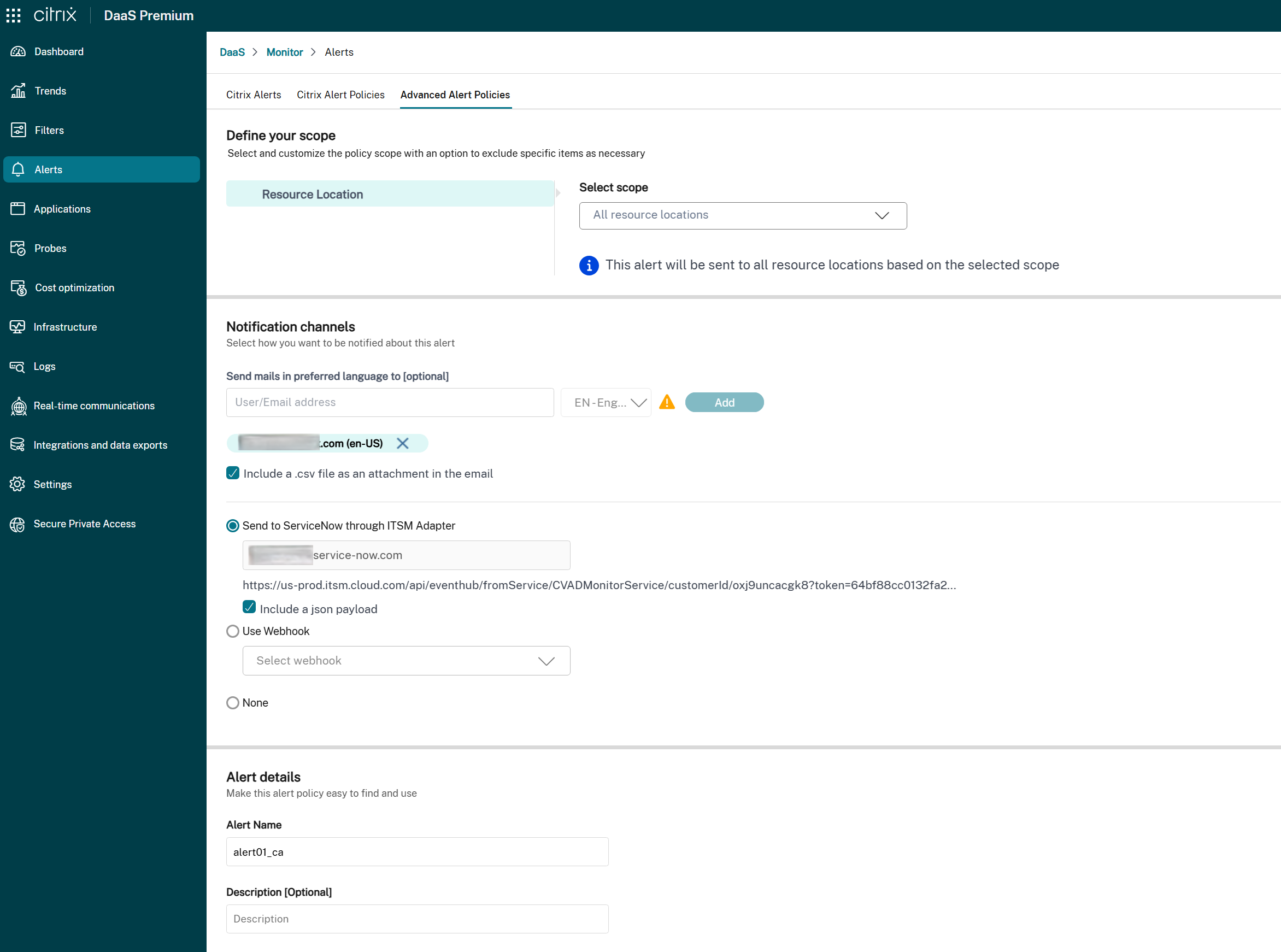
1. Dans la section **Préférences de notification**, recherchez l’option **Intégration ServiceNow** :
- **Si ITSM Adapter est disponible :**
- Cochez la case pour activer les notifications d’alerte via ServiceNow pour cette stratégie.
- L’URL de l’instance ServiceNow associée est affichée à titre de référence.
- Si la stratégie a déjà un webhook configuré, un message d’avertissement vous informe que l’activation de l’intégration ServiceNow remplace la configuration de webhook existante.
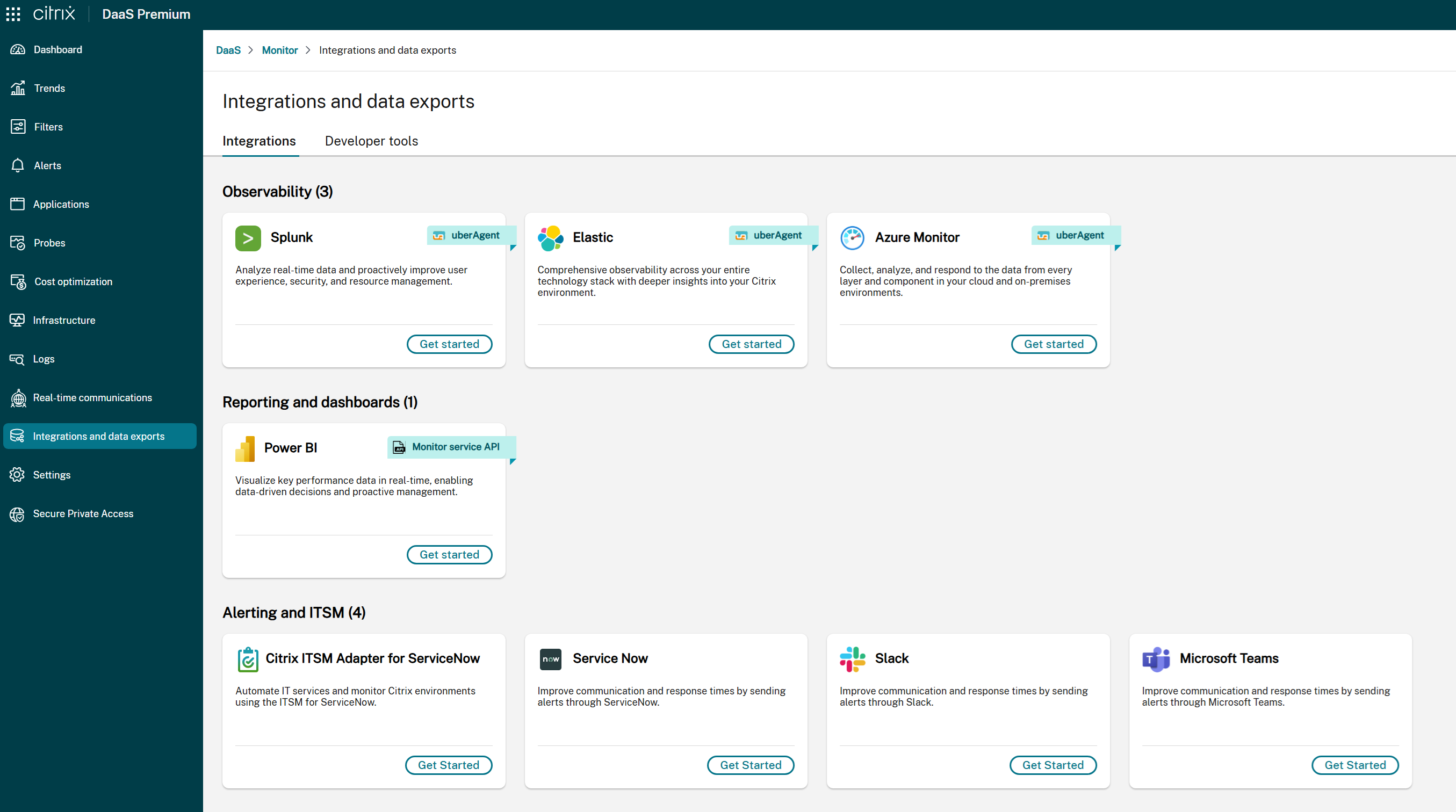
- **Si ITSM Adapter n’est pas disponible :**
- Un message indique que l’intégration ITSM n’est pas configurée actuellement.
- Cliquez sur **Démarrer** pour accéder à la configuration de l’intégration. Pour plus de détails, reportez-vous à la [documentation](https://docs.citrix.com/fr-fr/citrix-itsm-adapter-service/onboard).
1. Cliquez sur **Enregistrer** pour enregistrer la stratégie.
Une fois configurées, les alertes qui remplissent les conditions de la stratégie sont automatiquement transmises à ServiceNow, où elles peuvent être gérées comme des incidents ou des événements en fonction de votre configuration ITSM.
## Suppression en masse des alertes
Cette fonctionnalité optimise le processus de gestion des alertes pour les administrateurs, offrant une flexibilité et réduisant la fatigue liée aux alertes. Les administrateurs peuvent supprimer en masse les alertes en fonction de l’heure, du type ou de la catégorie, ce qui simplifie la gestion des alertes pendant la maintenance ou lors de l’utilisation d’hyperviseurs et d’autres environnements.
La suppression en masse des alertes aide les administrateurs à gérer leur charge de travail efficacement et les empêche d’être submergés par un volume élevé d’alertes.
### Étapes pour supprimer en masse les alertes
1. Accédez à l’onglet **Alertes** > **Alertes Citrix**. Les alertes sont affichées.
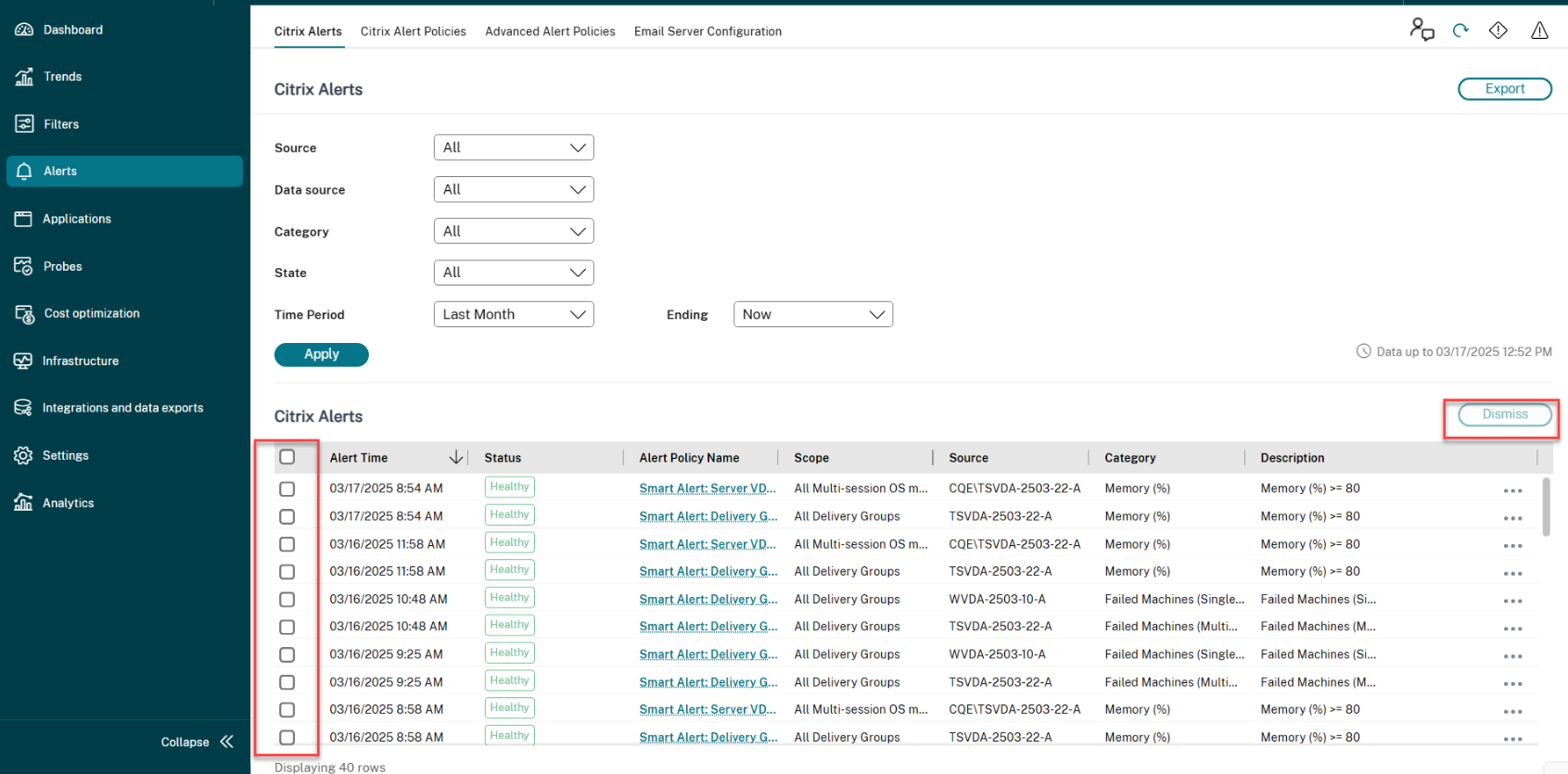
1. Sélectionnez une option parmi **Source**, **Catégorie**, **État** ou **Période** pour filtrer les alertes que vous souhaitez supprimer. Les alertes spécifiques sont affichées.
1. Cochez la case à côté d’une alerte spécifique ou en haut pour sélectionner toutes les alertes.
1. Cliquez sur **Ignorer**. Une notification apparaît pour confirmer la suppression des alertes.
1. Cliquez sur **Oui**. Les alertes sélectionnées sont marquées comme *ignorées* et l’état de l’alerte est mis à jour en conséquence.
## Configuration de webhook à l’aide du SDK PowerShell
La fonctionnalité de configuration de webhook à l’aide du SDK PowerShell permet aux administrateurs de créer, modifier, supprimer et lister des profils de webhook. Cette fonctionnalité offre une flexibilité dans la configuration des webhooks en permettant la spécification des en-têtes, des types d’authentification, des types de contenu, des charges utiles et des URL de webhook.
>**Remarque:**
>
> Le format de charge utile pris en charge est le texte et l’utilisateur final doit activer le texte dans son webhook.
Le dernier format de charge utile est :
{“text”: “This is a message from a Webex incoming webhook.”}
### Créer un webhook
Vous pouvez utiliser l’exemple de commande PowerShell suivant pour créer un profil de webhook :
**Créer un webhook sans en-tête d’autorisation :**
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add(“Content-Type”, “application/json”)
$payloads = ‘{ “text”: “$PAYLOAD” }’
$url = “
Add-MonitorWebhookProfile -Name “webhookprofile1” -Description “Description” -Url $url -Headers $headers -PayloadFormat $payloads -Platform Slack -Type Webhook -MethodType POST
**Créer un webhook avec en-tête d’autorisation :**
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add(“Content-Type”, “application/json”)
$headers.Add(“Authorization”, “Basic
$payloads = ‘{ “text”: “$PAYLOAD” }’
$url = “
Add-MonitorWebhookProfile -Name “webhookprofile1” -Description “Description” -Url $url -Headers $headers -PayloadFormat $payloads -Platform Slack -Type Webhook -MethodType POST
**Exemple:**
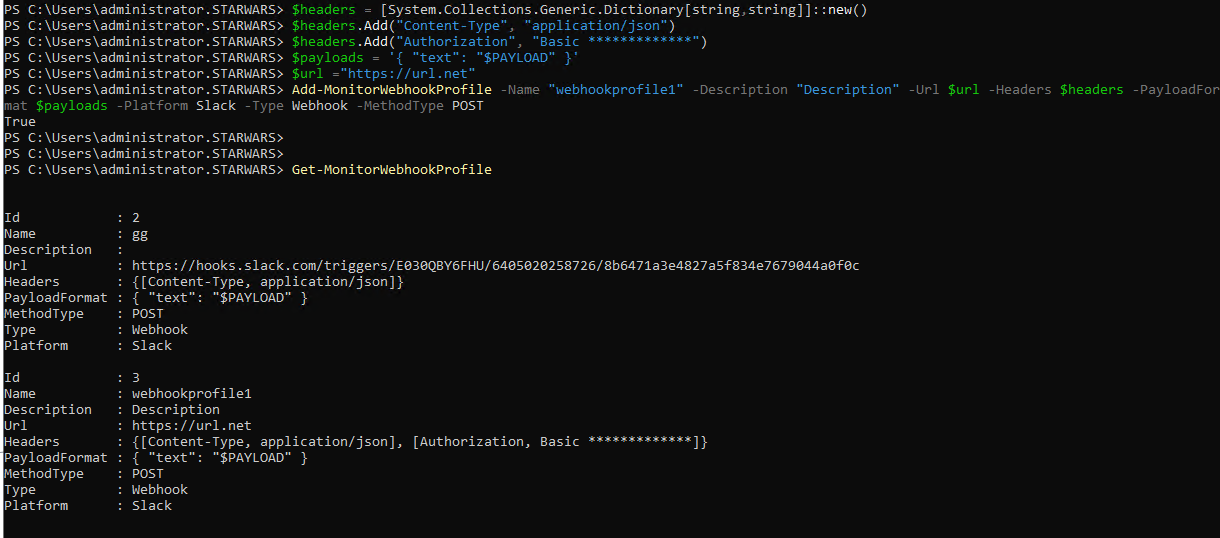
Une fois le profil créé, vous pouvez le vérifier dans la base de données. Vous pouvez également trouver le profil de webhook nouvellement créé sur la page **Alertes Citrix**.
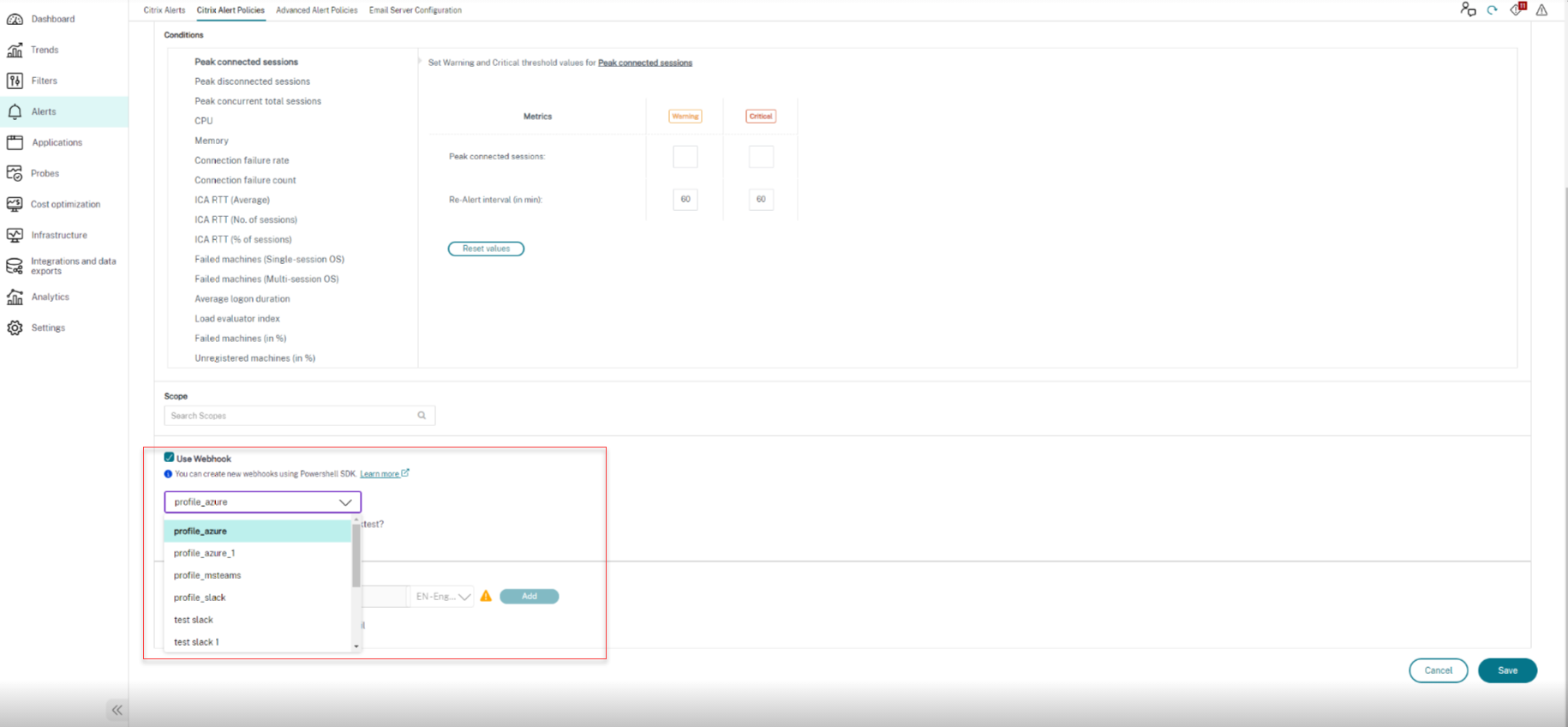
### Mettre à jour un profil de webhook
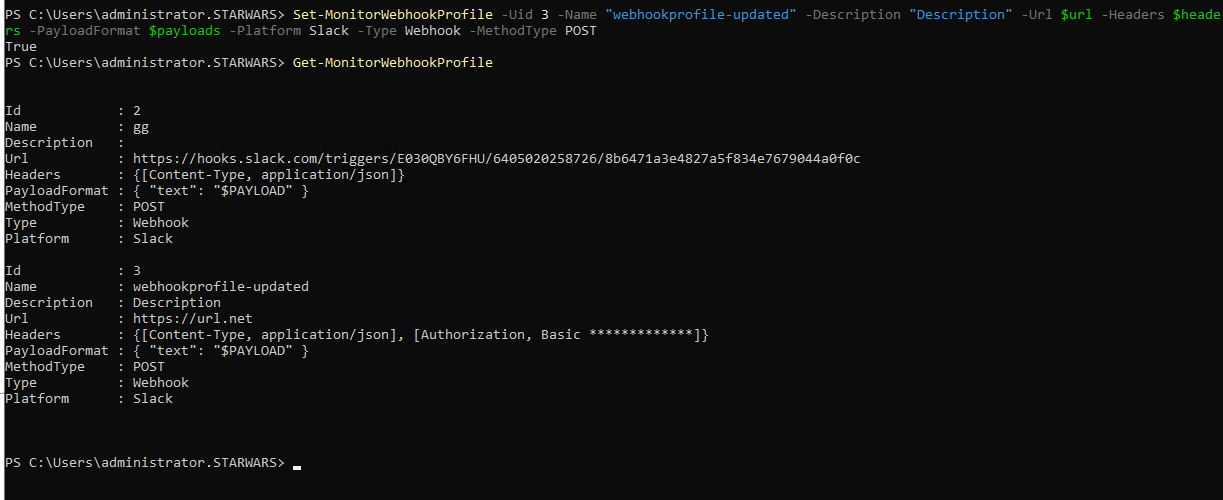
Vous pouvez utiliser l’exemple de commande PowerShell suivant pour mettre à jour un profil de webhook :
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add(“Content-Type”, “application/json”)
$payloads = ‘{ “text”: “$PAYLOAD” }’
$url = “
Set-MonitorWebhookProfile -Uid 1 -Name “profile_slack_citrix” -Description “webhook profile for citrix slack” -Url $url -Headers $headers -PayloadFormat $payloads -Platform Slack -Type Webhook -MethodType POST
### Obtenir une liste de tous les profils de webhook
Vous pouvez utiliser l'exemple de commande PowerShell suivant pour obtenir une liste de tous les profils de webhook disponibles :
Get-MonitorWebhookProfile
Get-MonitorWebhookProfile -Name ‘profile_msteams’
Get-MonitorWebhookProfile -Uid 1
### Supprimer un profil de webhook
Vous pouvez utiliser l'exemple de commande PowerShell suivant pour supprimer un profil de webhook :
Remove-MonitorWebhookProfile -Uid 1
>**Remarque:**
>
>Si un profil de webhook est mappé à une stratégie, il ne peut pas être supprimé. Pour contourner ce problème, vous devez d'abord supprimer le mappage du webhook de la stratégie.
### Créer une stratégie avec un profil de webhook
Vous pouvez utiliser l'exemple de commande PowerShell suivant pour créer une stratégie avec un profil de webhook :
New-MonitorNotificationPolicy -Name “Policy1” -Description “Policy Description” -Enabled $true -WebhookProfileId 1
### Mettre à jour une stratégie avec un profil de webhook
Vous pouvez utiliser l'exemple de commande PowerShell suivant pour mettre à jour une stratégie avec un profil de webhook :
$Policy = Set-MonitorNotificationPolicy -Uid 1 -WebhookProfileId 1
### Supprimer le mappage de webhook d'une stratégie
Vous pouvez utiliser l'exemple de commande PowerShell suivant pour supprimer le profil de webhook d'une stratégie :
$Policy = Set-MonitorNotificationPolicy -Uid 1 -WebhookProfileId 0
### Tester le profil de webhook
Vous pouvez utiliser l'exemple de commande PowerShell suivant pour tester le profil de webhook :
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add(“Content-Type”, “application/json”)
$headers.Add(“Authorization”, “Basic
$payloads = ‘{ “text”: “$PAYLOAD” }’
$url =”
Test-MonitorWebhookProfile -Url $url -Headers $headers -PayloadFormat $payloads
```
Surveillance des alertes d’échec de synchronisation de la configuration du cache d’hôte local
Le cache d’hôte local permet aux sessions utilisateur de se poursuivre même si les Cloud Connectors perdent la connectivité avec Citrix Cloud. Le cache utilisé par le cache d’hôte local est régulièrement synchronisé avec la base de données principale pour garantir des configurations à jour lorsque le mode cache d’hôte local est activé. Vous pouvez obtenir plus d’informations sur le cache d’hôte local et le processus de synchronisation de la configuration à l’adresse Cache d’hôte local. Si la synchronisation de la configuration échoue plus de trois fois consécutives, Citrix Monitor envoie une alerte d’avertissement à l’administrateur.
Une stratégie d’alerte prédéfinie nommée Cache d’hôte local - Échec de synchronisation de la configuration a été introduite dans Citrix Monitor pour informer les administrateurs des échecs de synchronisation de la configuration. Vous pouvez trouver la stratégie nouvellement introduite sous Monitor > Alertes Citrix. Vous pouvez modifier la stratégie prédéfinie pour ajouter ou modifier des destinataires d’e-mail ou des webhooks afin de recevoir des notifications proactives dans vos outils de gestion des alertes ou ITSM.
La portée de la stratégie d’alerte Cache d’hôte local - Échec de synchronisation de la configuration est limitée au site uniquement.
Surveillance des alertes d’hyperviseur
Monitor affiche des alertes pour surveiller l’état de santé de l’hyperviseur. Les alertes de Citrix Hypervisor™ et VMware vSphere aident à surveiller les paramètres et les états de l’hyperviseur. L’état de la connexion à l’hyperviseur est également surveillé pour fournir une alerte si le cluster ou le pool d’hôtes est redémarré ou indisponible.
Pour recevoir les alertes d’hyperviseur, assurez-vous qu’une connexion d’hébergement est créée dans l’onglet Gérer. Pour plus d’informations, consultez Connexions et ressources. Seules ces connexions sont surveillées pour les alertes d’hyperviseur. Le tableau suivant décrit les différents paramètres et états des alertes d’hyperviseur.
| Alerte | Hyperviseurs pris en charge | Déclenchée par | Condition | Configuration |
|---|---|---|---|---|
| Utilisation du CPU | Citrix Hypervisor, VMware vSphere | Hyperviseur | Le seuil d’alerte d’utilisation du CPU est atteint ou dépassé | Les seuils d’alerte doivent être configurés dans l’hyperviseur. |
| Utilisation de la mémoire | Citrix Hypervisor, VMware vSphere | Hyperviseur | Le seuil d’alerte d’utilisation de la mémoire est atteint ou dépassé | Les seuils d’alerte doivent être configurés dans l’hyperviseur. |
| Utilisation du réseau | Citrix Hypervisor, VMware vSphere | Hyperviseur | Le seuil d’alerte d’utilisation du réseau est atteint ou dépassé | Les seuils d’alerte doivent être configurés dans l’hyperviseur. |
| Utilisation du disque | VMware vSphere | Hyperviseur | Le seuil d’alerte d’utilisation du disque est atteint ou dépassé | Les seuils d’alerte doivent être configurés dans l’hyperviseur. |
| Connexion de l’hôte ou état d’alimentation | VMware vSphere | Hyperviseur | L’hôte hyperviseur a été redémarré ou est indisponible | Les alertes sont préintégrées dans VMware vSphere. Aucune configuration supplémentaire n’est nécessaire. |
| Connexion de l’hyperviseur indisponible | Citrix Hypervisor, VMware vSphere | Delivery Controller | La connexion à l’hyperviseur (pool ou cluster) est perdue, mise hors tension ou redémarrée. Cette alerte est générée toutes les heures tant que la connexion est indisponible. | Les alertes sont préintégrées avec le Delivery Controller. Aucune configuration supplémentaire n’est nécessaire. |
Remarque:
Pour plus d’informations sur la configuration des alertes, consultez Alertes Citrix XenCenter ou la documentation des alertes VMware vCenter.
La préférence de notification par e-mail peut être configurée sous Stratégie d’alertes Citrix > Stratégie de site > État de l’hyperviseur. Les conditions de seuil pour les stratégies d’alerte d’hyperviseur peuvent être configurées, modifiées, désactivées ou supprimées uniquement depuis l’hyperviseur et non depuis Monitor. Cependant, la modification des préférences d’e-mail et la suppression d’une alerte peuvent être effectuées dans Monitor.
Important:
- Toutes les alertes d’hyperviseur de plus d’un jour sont automatiquement ignorées.
- Les alertes déclenchées par l’hyperviseur sont récupérées et affichées dans Monitor. Cependant, les modifications du cycle de vie/état des alertes d’hyperviseur ne sont pas reflétées dans Monitor.
- Les alertes saines, ignorées ou désactivées dans la console de l’hyperviseur continueront d’apparaître dans Monitor et devront être ignorées explicitement.
- Les alertes ignorées dans Monitor ne sont pas automatiquement ignorées dans la console de l’hyperviseur.
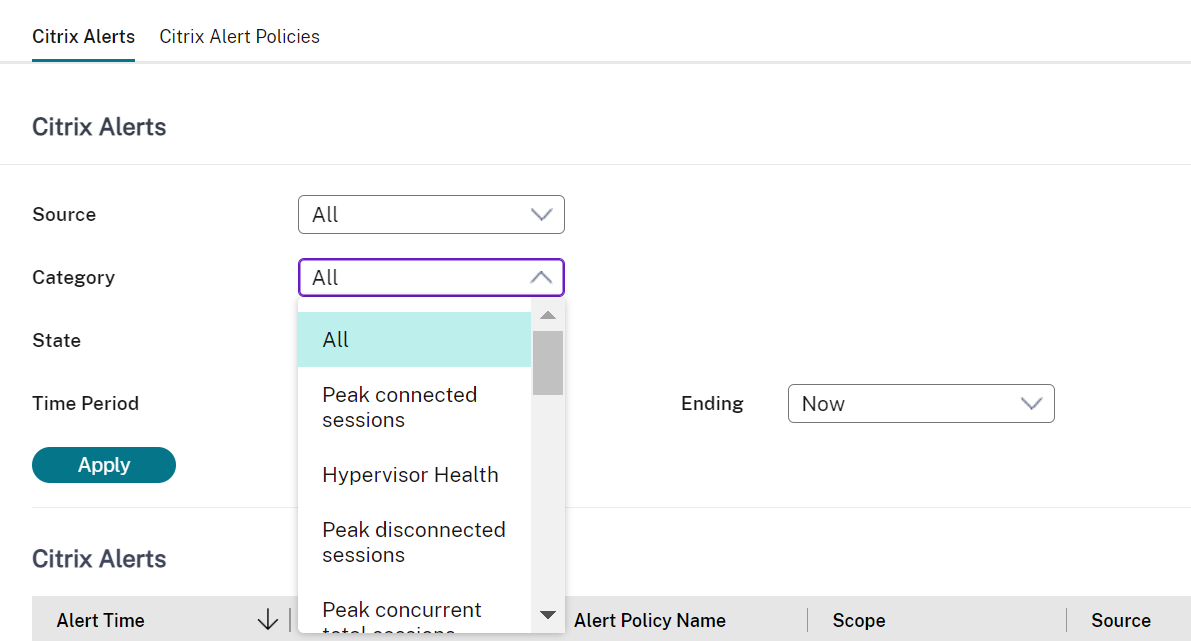
Une nouvelle catégorie d’alerte appelée État de l’hyperviseur a été ajoutée pour permettre de filtrer uniquement les alertes d’hyperviseur. Ces alertes sont affichées une fois que les seuils sont atteints ou dépassés. Les alertes d’hyperviseur peuvent être :
- Critique — le seuil critique de la stratégie d’alarme de l’hyperviseur est atteint ou dépassé
- Avertissement — le seuil d’avertissement de la stratégie d’alarme de l’hyperviseur est atteint ou dépassé
- Ignorée — l’alerte n’est plus affichée comme une alerte active