Alertas e notificações
Os alertas são exibidos no Director no painel e em outras exibições de alto nível com símbolos de alerta de aviso e críticos. Os alertas estão disponíveis para sites com licença Premium. Os alertas são atualizados automaticamente a cada minuto; você também pode atualizar os alertas sob demanda.
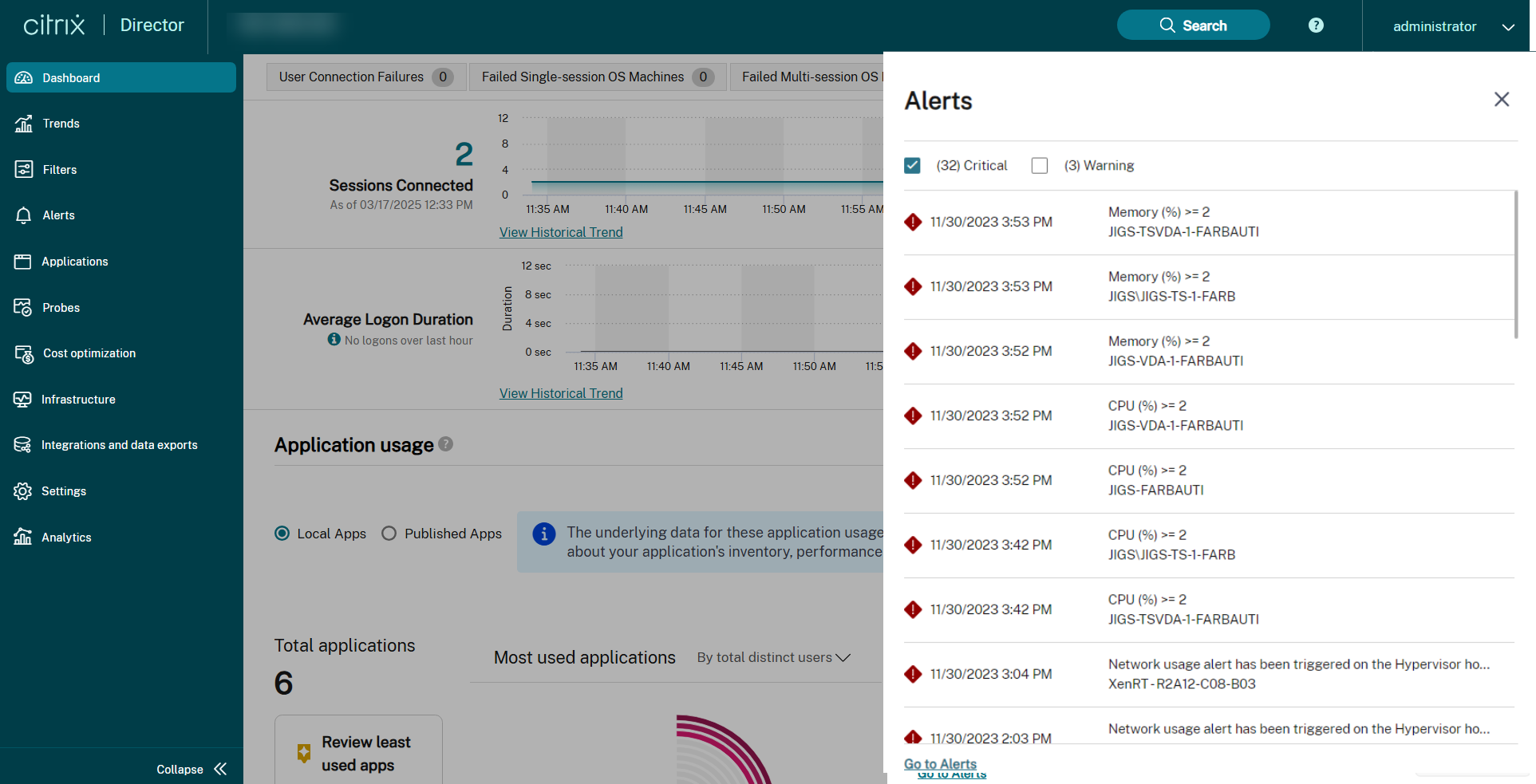
Um alerta de aviso (triângulo âmbar) indica que o limite de aviso de uma condição foi atingido ou excedido.
Um alerta crítico (círculo vermelho) mostra que o limite crítico de uma condição foi atingido ou excedido.
Você pode visualizar informações mais detalhadas sobre os alertas selecionando um alerta na barra lateral, clicando no link “Ir para Alertas” na parte inferior da barra lateral ou selecionando “Alertas” na parte superior da página do Director.
Na exibição “Alertas”, você pode filtrar e exportar alertas. Por exemplo, máquinas de SO de várias sessões com falha para um Grupo de Entrega específico no último mês, ou todos os alertas para um usuário específico. Para obter mais informações, consulte Exportar relatórios.
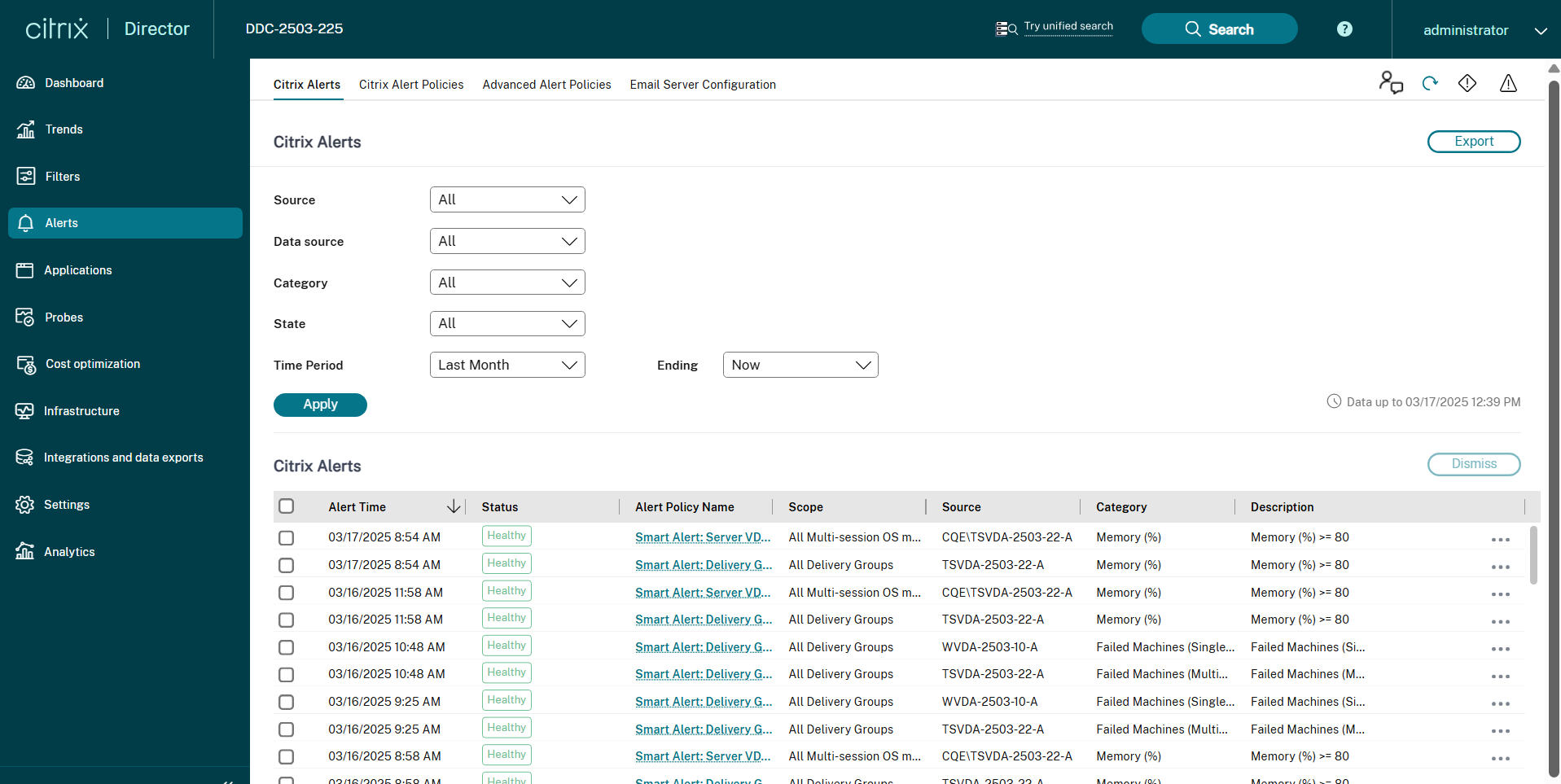
Alertas Citrix®
Os alertas Citrix são alertas monitorados no Director que se originam de componentes Citrix. Você pode configurar alertas Citrix no Director em “Alertas” > “Política de Alertas Citrix”. Como parte da configuração, você pode definir notificações a serem enviadas por e-mail para indivíduos e grupos quando os alertas excederem os limites que você configurou. Para obter mais informações sobre como configurar Alertas Citrix, consulte Criar políticas de alerta.
Nota:
Certifique-se de que seu firewall, proxy ou Microsoft Exchange Server não bloqueiem os alertas por e-mail.
Políticas de alerta inteligentes
Um conjunto de políticas de alerta integradas com valores de limite predefinidos está disponível para Grupos de Entrega e escopo de VDA de SO de várias sessões. Este recurso requer o(s) Delivery Controller(s) versão 7.18 ou posterior. Você pode modificar os parâmetros de limite das políticas de alerta integradas em “Alertas” > “Política de Alertas Citrix”. Essas políticas são criadas quando há pelo menos um destino de alerta — um Grupo de Entrega ou um VDA de SO de várias sessões — definido em seu site. Além disso, esses alertas integrados são adicionados automaticamente a um novo grupo de entrega ou a um VDA de SO de várias sessões.
Caso você atualize o Director e seu site, as políticas de alerta da sua instância anterior do Director são transferidas. As políticas de alerta integradas são criadas somente se não existirem regras de alerta correspondentes no banco de dados do Monitor.
Para os valores de limite das políticas de alerta integradas, consulte a seção Condições das políticas de alerta.
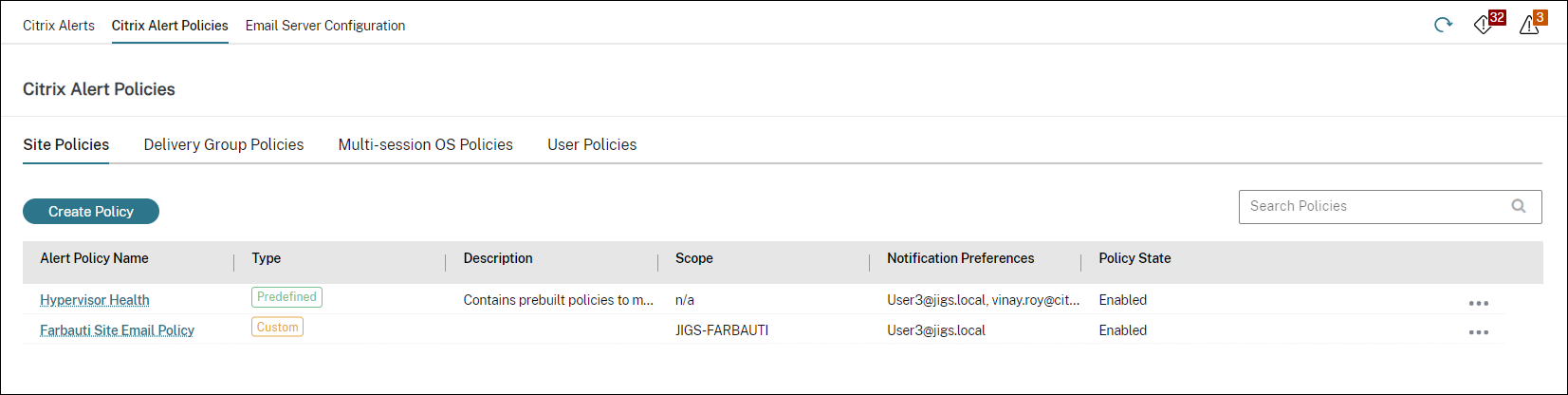
Políticas de alerta avançadas
O recurso de Notificação e Alerta Proativo do Director foi aprimorado para incluir uma nova estrutura de alerta chamada “Políticas de Alerta Avançadas”. Com este recurso, você pode criar alertas incluindo detalhes granulares para cada elemento ou condição, aumentando assim o controle sobre o escopo dos alertas. Atualmente, essas políticas incluem alertas para economia de custos e infraestrutura.
Com a introdução das políticas de alerta avançadas, que são alertas orientados por fonte de dados, você pode usar a filtragem de escopo de várias condições.
Este recurso ajuda a reduzir alertas excessivos que podem levar à diminuição da capacidade de resposta ou eficácia na resolução de problemas importantes. Esta política ajuda a medir a eficácia das políticas de alerta e o engajamento dos administradores.
Você pode criar uma política de alerta avançada na seção “Alertas” > “Política de alerta avançada” > “Criar Política”.
Você pode selecionar uma das seguintes fontes de dados:
- Máquinas
- Provisioning Service
- StoreFront™
- Delivery Controller™
Alertas para economia de custos
Você pode criar alertas para economia de custos que ajudam a otimizar os custos. Atualmente, você pode criar alertas para máquinas.
Para criar alertas em Máquinas, faça o seguinte:
- Clique na guia “Alertas” > “Políticas de Alerta Avançadas”. A página “Políticas de Alerta Avançadas” é exibida.
- Clique em “Criar Política”. A seção “Criar Políticas de Alerta Avançadas” é exibida.
-
Selecione “Máquinas” na lista suspensa “Fonte de dados”. A condição de economia de custos e os tipos de condição correspondentes são exibidos.
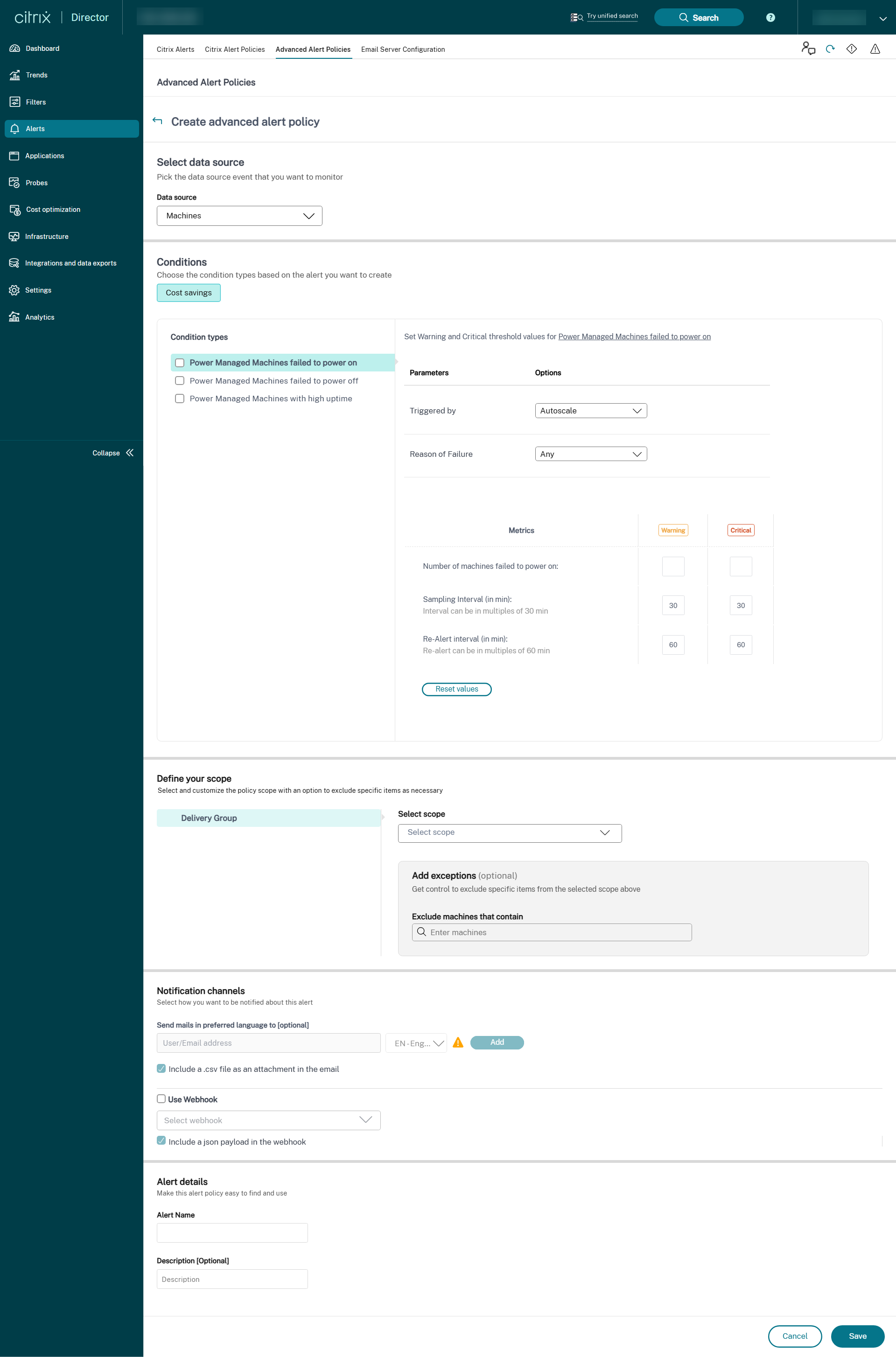
-
Selecione os seguintes tipos de condição conforme necessário:
- Máquinas gerenciadas por energia que falharam ao ligar
- Máquinas gerenciadas por energia que falharam ao desligar
- Máquinas gerenciadas por energia com alto tempo de atividade
- Selecione os parâmetros específicos e as opções correspondentes para cada uma das condições selecionadas.
-
Defina as métricas de Aviso e Crítico para o tipo de condição selecionado:
-
Para Máquinas gerenciadas por energia com alto tempo de atividade:
- Número de máquinas que excedem o limite de tempo de atividade
- Intervalo de re-alerta (em min), o intervalo pode ser um mínimo de 60 min
-
Para Máquinas gerenciadas por energia que falharam ao ligar e Máquinas gerenciadas por energia que falharam ao desligar:
- Número de máquinas que excedem o limite de tempo de atividade
- Intervalo de amostragem (em min), os intervalos podem ser múltiplos de 30 min
- Intervalo de re-alerta (em min), o re-alerta pode ser múltiplos de 60 min
-
- Agende intervalos de re-alerta para os alertas selecionados conforme necessário.
- Defina o escopo do alerta.
-
Defina os canais de notificação. Isso pode ser e-mail ou Webhook.
-
Você pode selecionar as seguintes caixas de seleção:
- Incluir um payload JSON como anexo no webhook
- Incluir um arquivo CSV como anexo no e-mail
Para obter mais informações, consulte Aprimoramentos no conteúdo do alerta.
-
- Insira os “Detalhes do alerta”, como “Nome do Alerta” e “Descrição” (opcional).
- Clique em “Salvar”. O alerta é criado.
Alertas para monitoramento de infraestrutura
Você pode criar alertas para monitorar a integridade dos seguintes componentes do Citrix Virtual Apps and Desktops™ suportados:
-
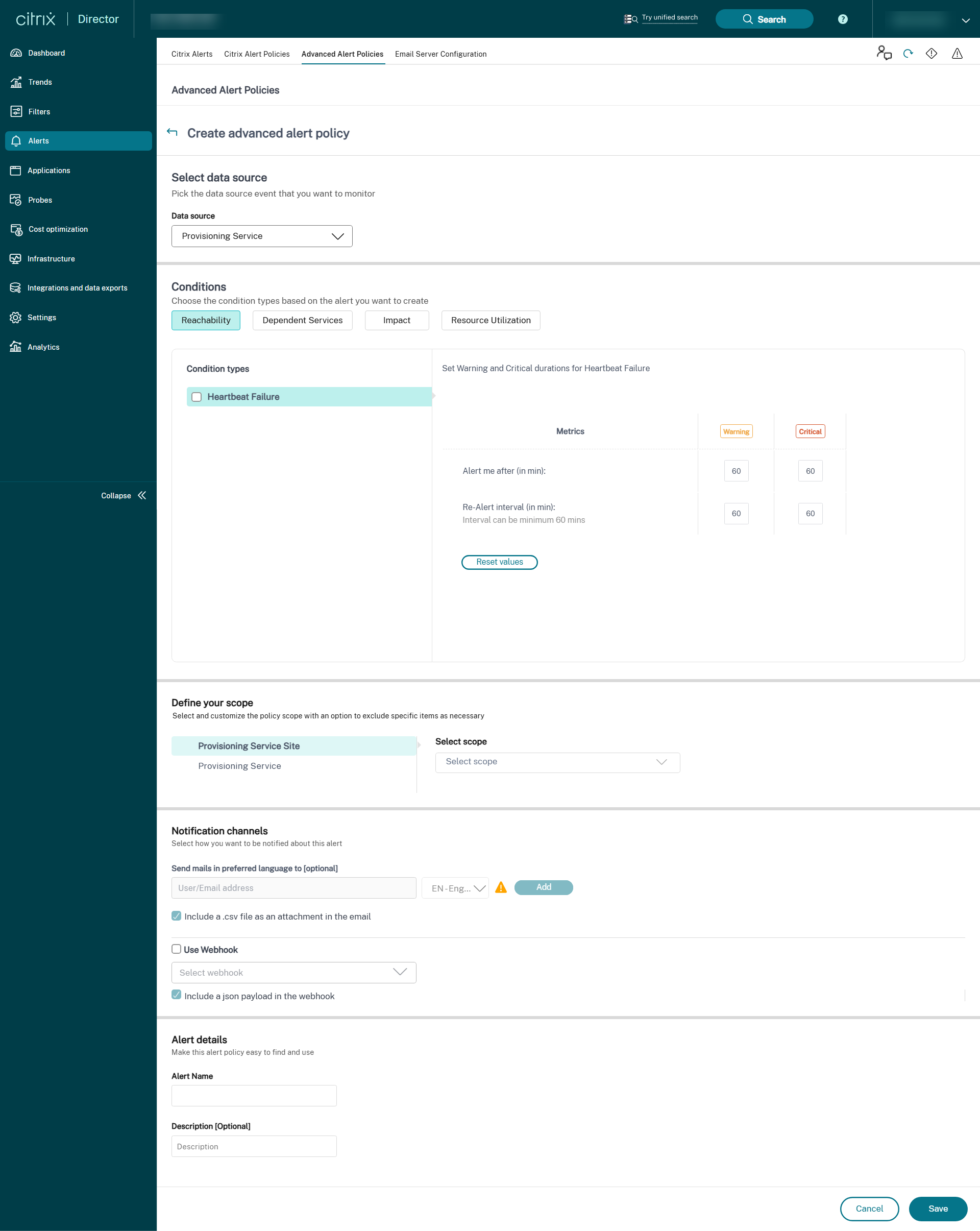
Provisioning Service
-
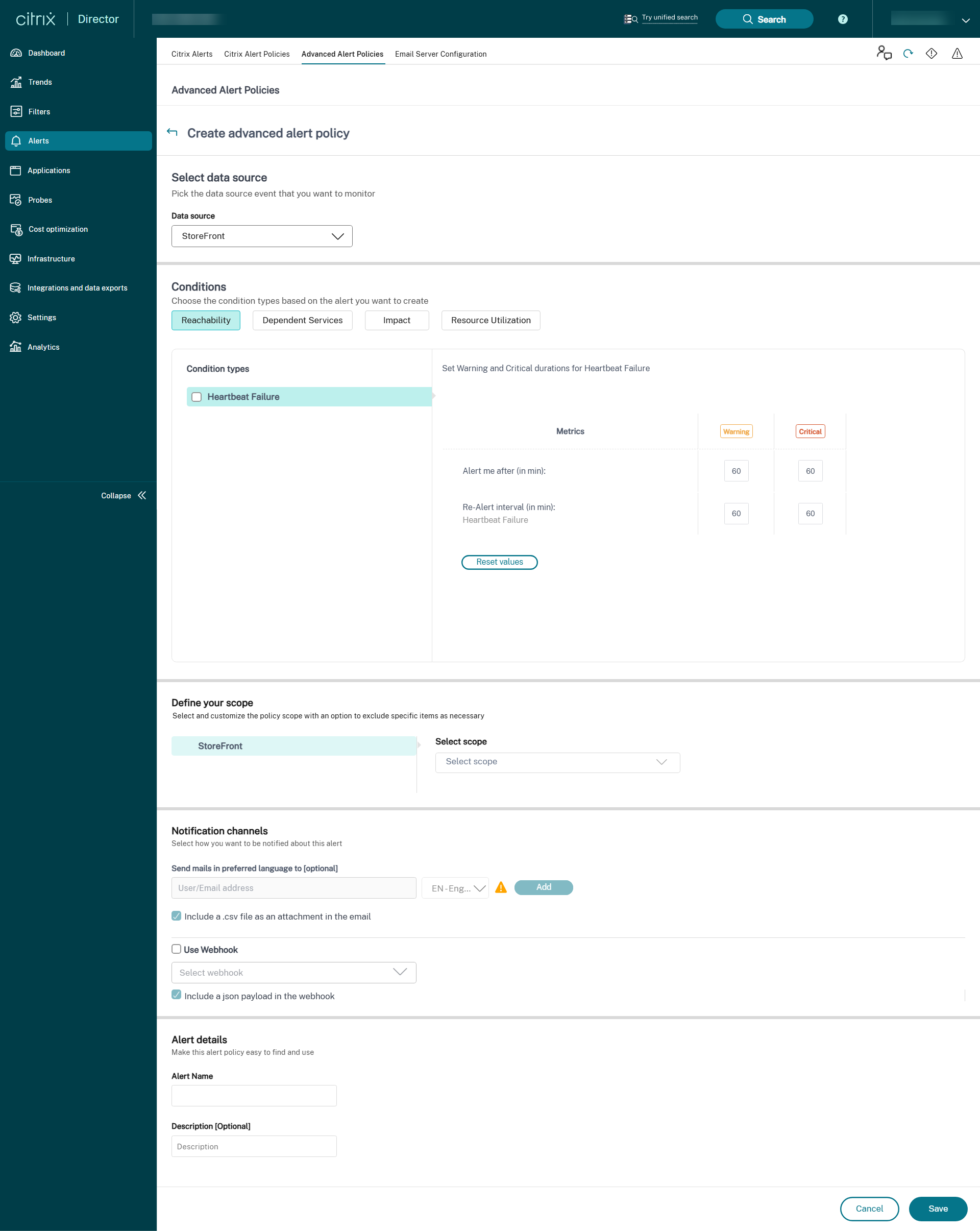
StoreFront
-
Delivery Controller
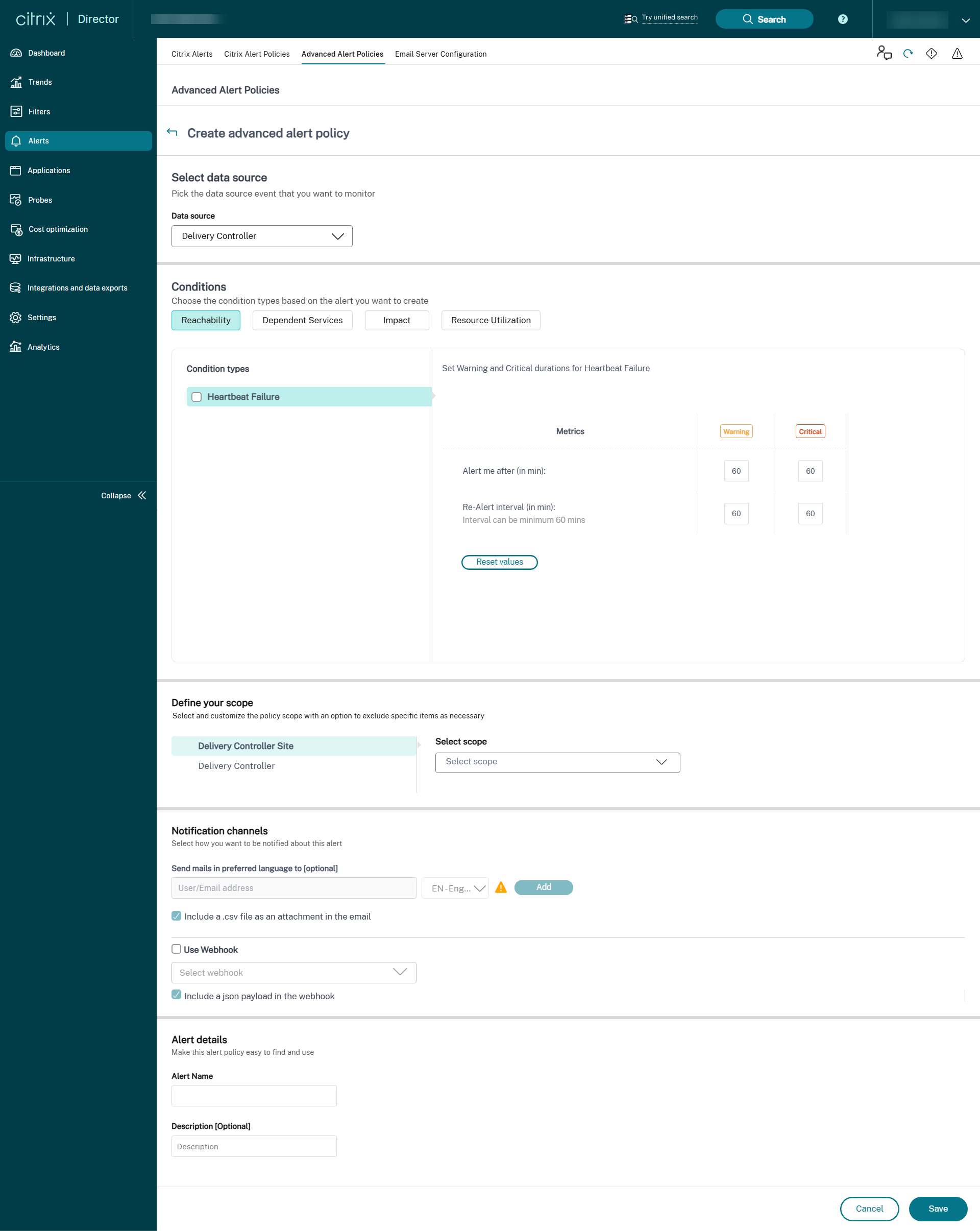
Uma vez concluída a configuração do Monitoramento de infraestrutura, você pode usar os dados de integridade disponíveis no Director para configurar alertas para qualquer componente necessário. Os administradores podem definir condições, escopos e meios de notificação para receber alertas importantes por e-mail ou um payload JSON por meio de webhooks. Para Provisioning Service e Delivery Controller, você pode selecionar o escopo dos alertas como nível de site ou nível de servidor individual. Por exemplo, no caso do Provisioning Service, se você selecionar “Todos os Provisioning Service”, você receberá apenas um único alerta para todo o site, mesmo que o site tenha dois servidores. Isso é considerado um alerta de nível de site. Os alertas gerados também estão disponíveis na seção “Alertas Citrix” para análise e gerenciamento.
Como parte da política de infraestrutura recém-introduzida, as condições de alerta são categorizadas em quatro seções, da seguinte forma:
- Acessibilidade
- Serviços dependentes
- Impacto
- Utilização de recursos
As condições dentro de cada categoria podem ser definidas com a gravidade “Crítico” e “Aviso” com base nas prioridades da sua organização. Você também pode agendar intervalos de re-alerta para esses alertas.
Você pode criar uma política de infraestrutura na seção “Alertas” > “Políticas de Alerta Citrix”. Você pode selecionar a categoria necessária e, em seguida, selecionar as condições necessárias para a política. Para obter mais informações sobre como criar uma política, consulte Criar políticas de alerta. Depois que a política é criada, você pode editar, excluir ou desabilitar a política na página Alertas Citrix.
Para obter mais detalhes sobre as condições suportadas em cada categoria e componente, consulte o seguinte:
- Métricas de integridade do Provisioning Service
- Métricas de integridade do StoreFront
- Métricas de integridade do Delivery Controller
Os seguintes dados são recebidos como um alerta por e-mail ou na página “Alerta Citrix”:
| Campo | Descrição |
|---|---|
| ID do Cliente | O ID do cliente do site. |
| Nível de alerta | Os valores possíveis são Crítico e Aviso. |
| Destino | O nome da máquina para a qual o alerta é acionado. |
| Hora | A hora em que o alerta é acionado. |
| Escopo | O escopo da política. |
| Política | O nome da política. |
| Descrição | A descrição do problema para o qual o alerta é acionado. |
Definir o escopo da política
Você pode definir o escopo do seu alerta e adicionar exceções. O alerta é gerado apenas para o escopo selecionado e o subescopo excluído usando “adicionar exceções” não é incluído na geração do alerta. Este recurso ajuda você a criar alertas em um nível granular.
Você pode criar notificações por e-mail ou por meio de URLs de webhook. Você também pode selecionar seu idioma preferido no qual gostaria de receber alertas. Você também pode selecionar uma opção para receber os parâmetros do alerta em um arquivo .CSV anexado para e-mail ou em um payload JSON por meio de uma URL de webhook. O anexo inclui detalhes dos parâmetros necessários. Para obter mais informações, consulte Aprimoramentos no conteúdo do alerta.
Os seguintes dados são recebidos como um alerta por e-mail ou na página “Alertas Citrix”:
| Campo | Descrição |
|---|---|
| ID do Cliente | O ID do cliente do site. |
| Nível de alerta | Este valor é o valor predefinido para cada condição de alerta. Os valores possíveis são Crítico e Aviso. |
| Condição | Este valor é a condição definida ao criar a política. Por exemplo, o número de máquinas não registradas é igual ou superior a 20. |
| Destino | O nome do grupo de entrega ou site para o qual o alerta é acionado. |
| Site | O nome do site. |
| Escopo | O escopo da política. Este valor também inclui o subescopo. |
| Política | O nome da política. |
| Descrição | A descrição do problema para o qual o alerta é acionado. |
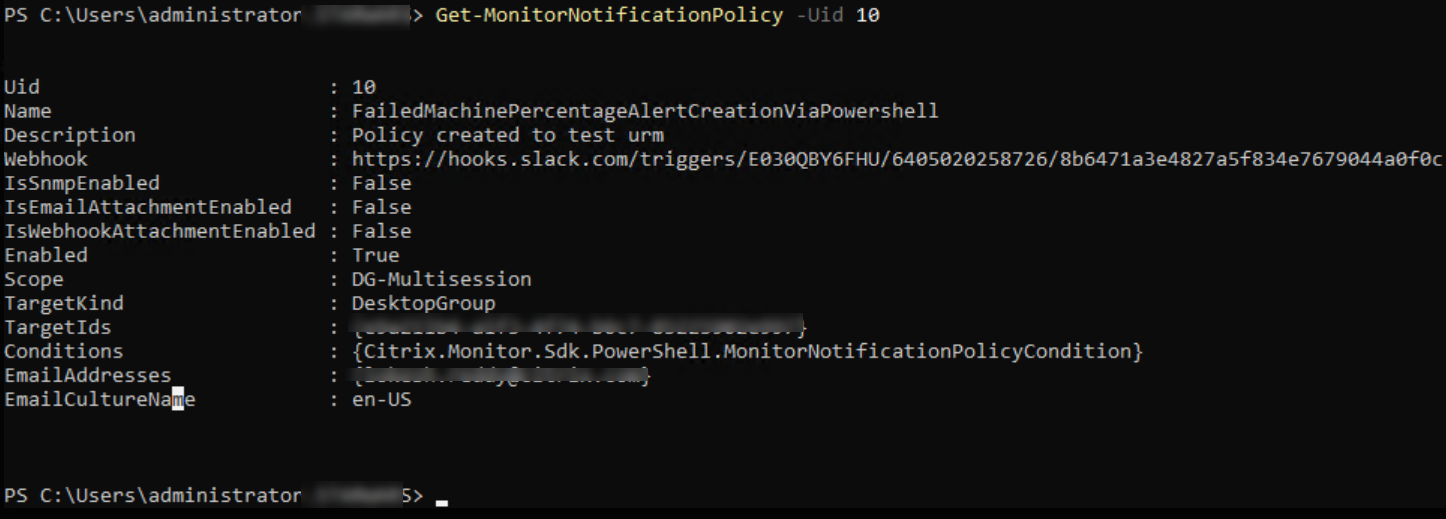
Como criar uma política de alerta avançada usando um script PowerShell?
Script PowerShell para criar uma política de alerta:
asnp Citrix.Monitor.*
# Add Parameters
$timeSpan = New-TimeSpan -Seconds 30
$alertThreshold = 1
$alarmThreshold = 2
# Add Target UID's
$targetIds = @()
$targetIds += "e9a211b4-a1f3-4f74-b6c7-85225902e997"
# Add email addresses
$emailaddress = @()
$emailaddress += "loki@abc.com"
# Create new policy
$policy = New-MonitorNotificationPolicy -Name "FailedMachinePercentageAlertCreationViaPowershell" -Description "Policy created to test urm" -Enabled $true
<!--NeedCopy-->
Substitua a seguinte linha pela condição correta para FailedMachinePercentage
Add-MonitorNotificationPolicyCondition -Uid $policy.Uid -ConditionType FailedMachinePercentage -AlertThreshold $alertThreshold -AlarmThreshold $alarmThreshold -AlertRenotification $timeSpan -AlarmRenotification $timeSpan
Add-MonitorNotificationPolicyTargets -Uid $policy.Uid -Scope "DG-Multisession" -TargetKind DesktopGroup -TargetIds $targetIds
$policy = Get-MonitorNotificationPolicy -Uid $policy.Uid
$policy
<!--NeedCopy-->
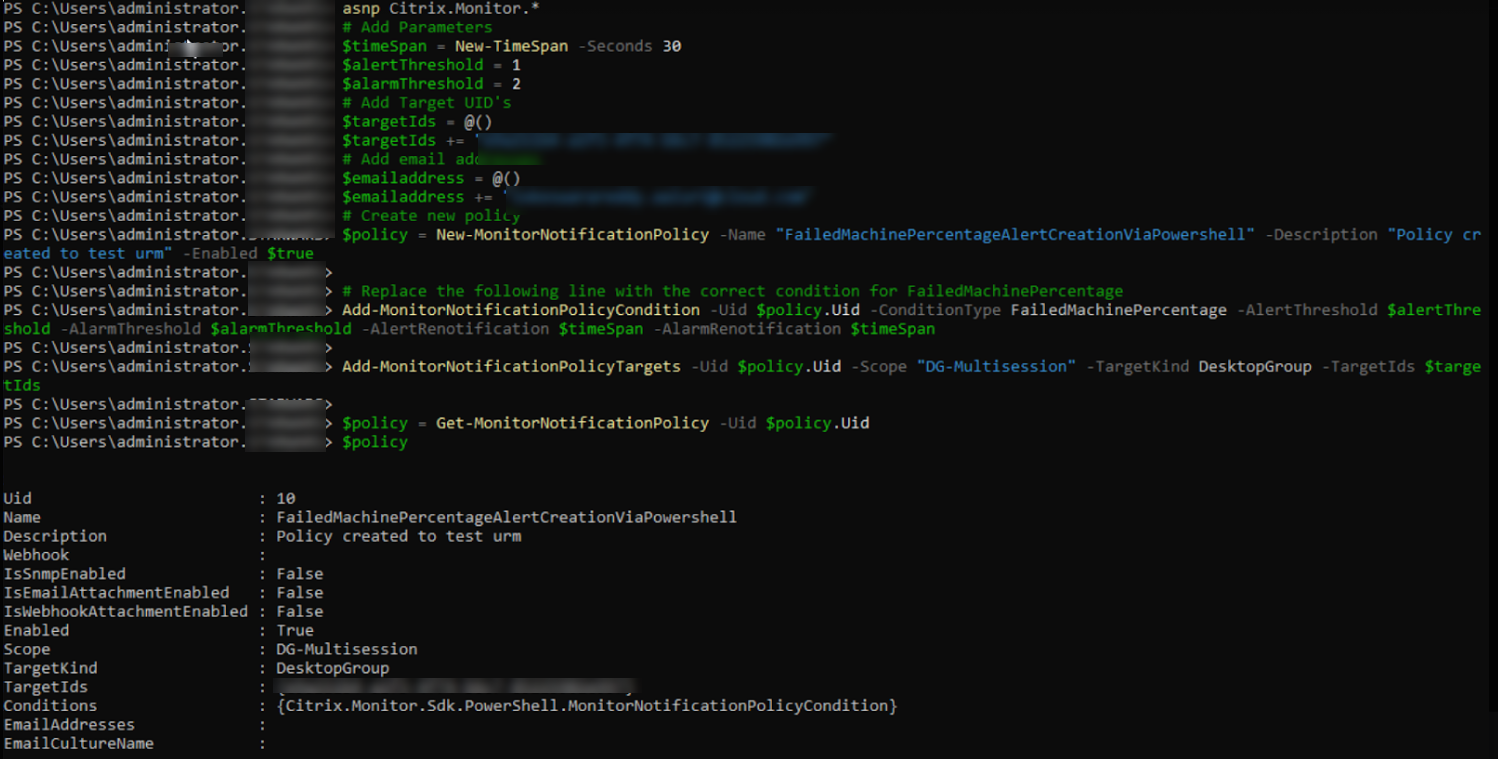
Na imagem anterior, você pode ver que a política foi criada e o Uid é 10.
Para adicionar e-mail à configuração
Set-MonitorNotificationEmailServerConfiguration -ProtocolType SMTP -ServerName NameOfTheSMTPServerOrIPAddress -PortNumber 80 -SenderEmailAddress loki@abc.com -RequiresAuthentication 0
<!--NeedCopy-->
Para adicionar e-mail à política
Add-MonitorNotificationPolicyEmailAddresses -Uid $policy.Uid -EmailAddresses $emailaddress -EmailCultureName "en-US"
<!--NeedCopy-->
Exemplo de script para adicionar e-mail:
Add-MonitorNotificationPolicyEmailAddresses -Uid 10 -EmailAddresses $emailaddress -EmailCultureName "en-US"
<!--NeedCopy-->

Para adicionar URL de Webhook à política
Set-MonitorNotificationPolicy –Uid $polcy.Uid –Webhook 'URL'
<!--NeedCopy-->

Exemplo de script para adicionar URL de webhook:
Set-MonitorNotificationPolicy –Uid 10 –Webhook 'https://hooks.slack.com/triggers/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'
<!--NeedCopy-->
Obter detalhes da política criada
Get-MonitorNotificationPolicy -Uid 10
<!--NeedCopy-->
Criar políticas de alerta
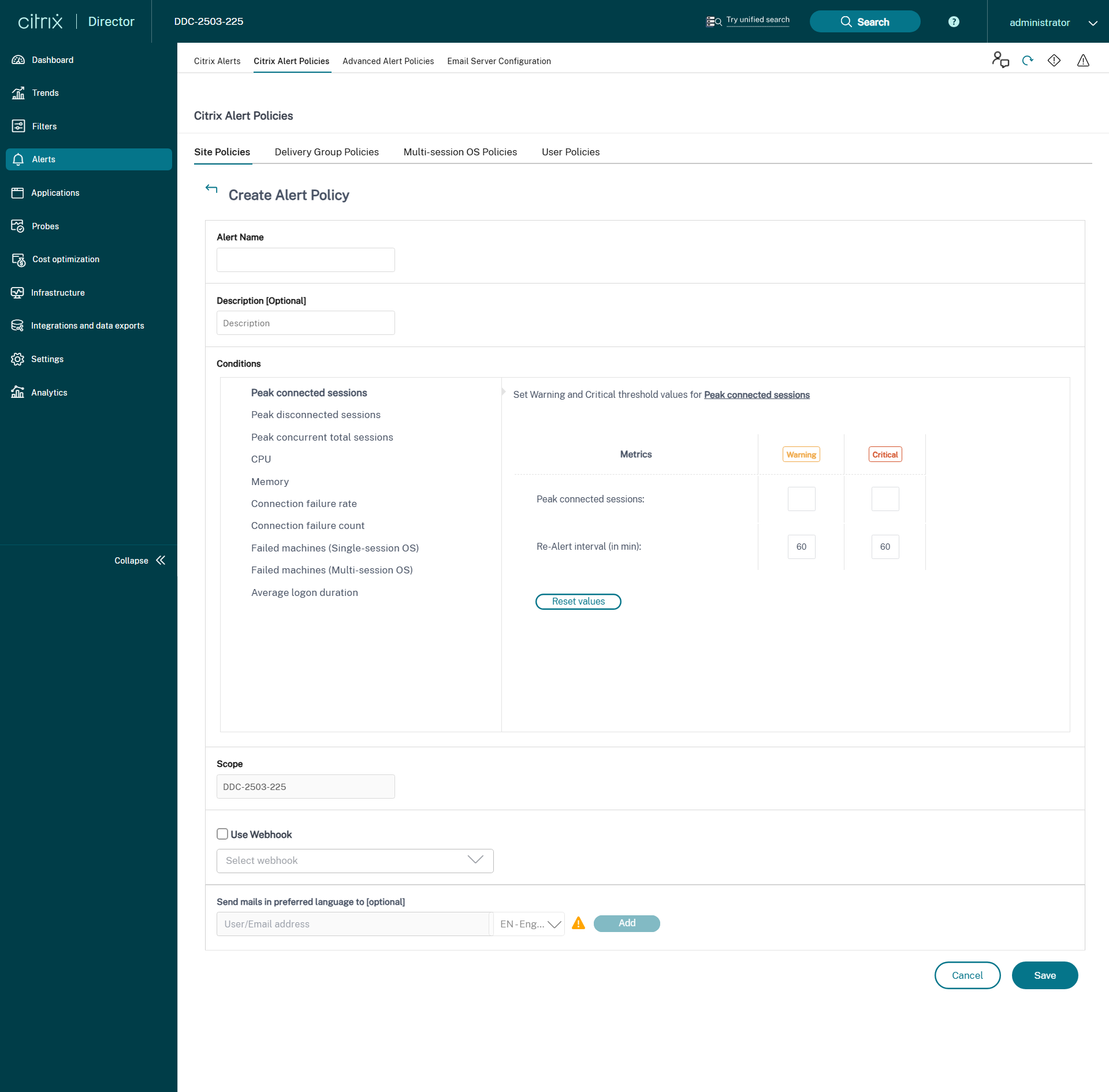
Para criar uma política de alerta, por exemplo, para gerar um alerta quando um conjunto específico de critérios de contagem de sessões for atendido:
- Vá para “Alertas” > “Política de Alertas Citrix” e selecione, por exemplo, Política de SO de Múltiplas Sessões.
- Clique em “Criar”.
- Nomeie e descreva a política e, em seguida, defina as condições que devem ser atendidas para que o alerta seja acionado. Por exemplo, especifique as contagens de Aviso e Crítico para Sessões Conectadas de Pico, Sessões Desconectadas de Pico e Sessões Totais Concorrentes de Pico. Os valores de Aviso não devem ser maiores que os valores Críticos. Para obter mais informações, consulte Condições das políticas de alerta.
- Defina o intervalo de re-alerta. Se as condições para o alerta ainda forem atendidas, o alerta será acionado novamente neste intervalo de tempo e, se configurado na política de alerta, uma notificação por e-mail será gerada. Um alerta ignorado não gera uma notificação por e-mail no intervalo de re-alerta.
- Defina o Escopo. Por exemplo, defina para um Grupo de Entrega específico.
- Nas preferências de Notificação, especifique quem deve ser notificado por e-mail quando o alerta for acionado. Você deve especificar um servidor de e-mail na guia “Configuração do Servidor de E-mail” para definir as preferências de Notificação por e-mail nas Políticas de Alerta.
- Você também pode receber o conteúdo do alerta em um anexo .CSV ou por meio do payload JSON. Para isso, selecione as seguintes caixas de seleção:
- “Incluir um payload JSON como anexo no webhook”
- “Incluir um arquivo CSV como anexo no e-mail”
Observação:
As opções para receber conteúdo de alerta por meio de anexo .CSV e payload JSON estão disponíveis apenas para alguns alertas atualmente. Para obter mais informações, consulte Aprimoramentos no conteúdo do alerta
- Você também pode receber o conteúdo do alerta em um anexo .CSV ou por meio do payload JSON. Para isso, selecione as seguintes caixas de seleção:
- Clique em “Salvar”.
A criação de uma política com 20 ou mais Grupos de Entrega definidos no Escopo pode levar aproximadamente 30 segundos para concluir a configuração. Um indicador de carregamento é exibido durante esse tempo.
A criação de mais de 50 políticas para até 20 Grupos de Entrega exclusivos (1000 destinos de Grupo de Entrega no total) pode resultar em um aumento no tempo de resposta (mais de 5 segundos).
Mover uma máquina que contém sessões ativas de um Grupo de Entrega para outro pode acionar alertas errôneos do Grupo de Entrega que são definidos usando parâmetros da máquina.
Observação:
Depois de excluir uma política de alerta, pode levar até 30 minutos para que as notificações de alerta geradas pela política parem.
Aprimoramentos no conteúdo do alerta
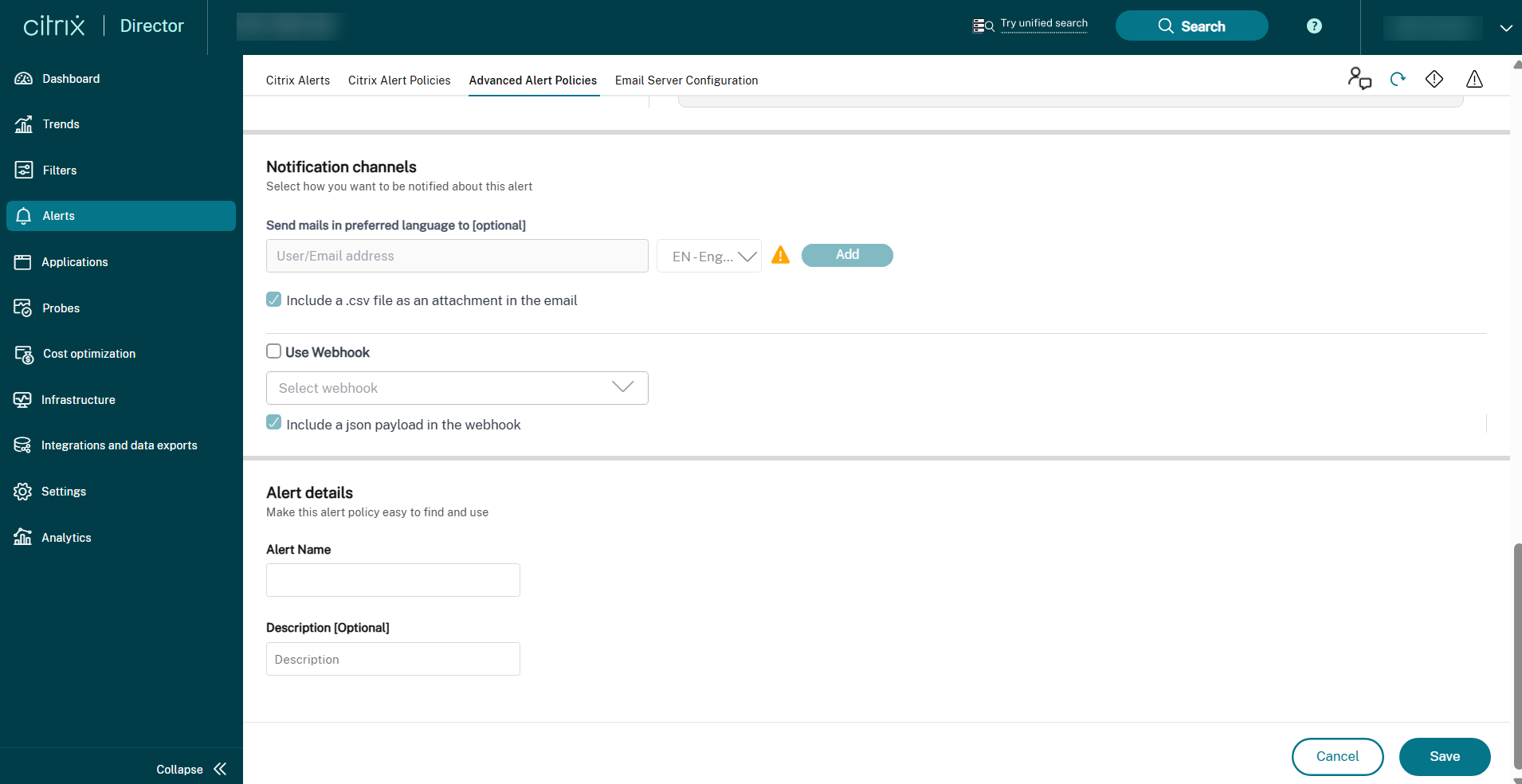
O recurso de alerta do Director foi aprimorado para incluir um anexo CSV e um payload JSON. Com esse aprimoramento, você pode obter detalhes do alerta em um anexo CSV por e-mail ou como um payload JSON se houver um webhook. Usando este anexo CSV ou payload JSON, você pode receber conteúdo enriquecido em um nível detalhado, auxiliando na rápida identificação e resolução de problemas.
Atualmente, este aprimoramento está disponível apenas nos seguintes alertas:
- Tempo de atividade da máquina
- Ações de inicialização com falha
- Ações de desligamento com falha
- Máquinas não registradas (%)
Para usar este recurso, navegue até o alerta e selecione as seguintes caixas de seleção:
- “Incluir um payload JSON como anexo no webhook”
- “Incluir um arquivo CSV como anexo no e-mail”
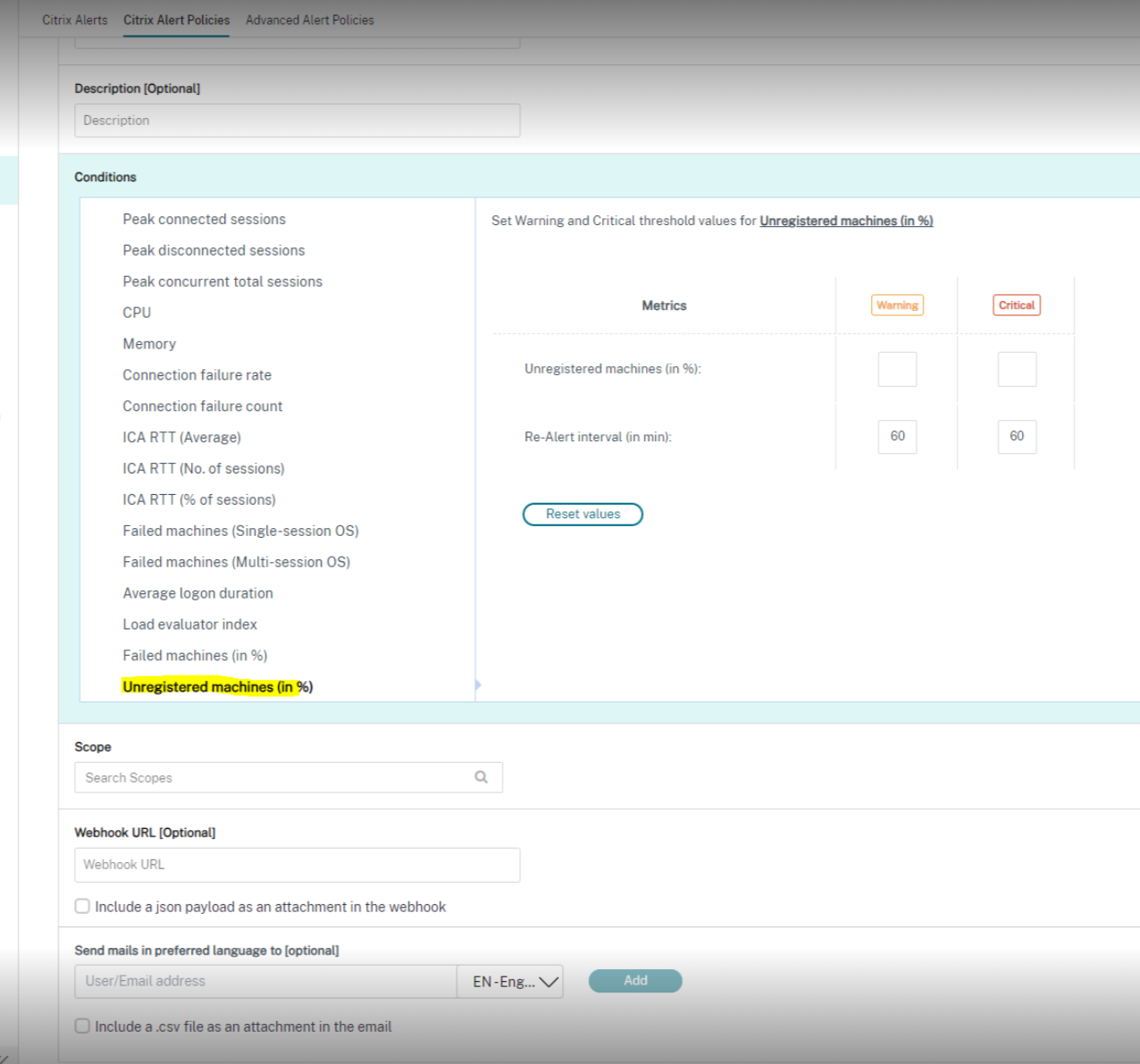
A seguir, uma captura de tela da seção “Políticas de Alerta Citrix”:
Aqui está uma captura de tela da seção “Políticas de Alerta Avançadas”:
Anexo CSV
A tabela a seguir fornece as colunas do anexo .CSV para todos os alertas suportados:
| Coluna | Alerta aplicável |
|---|---|
| Nome da Máquina, Endereço IP e Nome do Grupo de Entrega | Tempo de atividade da máquina, Ação de desligamento com falha e Ação de inicialização com falha, e Máquinas não registradas (%) |
| Estado de Registro Atual, Data da Falha, Estado de Falha e Estado do Ciclo de Vida | Máquina não registrada (%) |
| Motivo da Falha da Última Ação de Energia, Acionada Por Última Ação de Energia, Tipo da Última Ação de Energia e Data de Conclusão da Última Ação de Energia | Ação de desligamento com falha e Ação de inicialização com falha |
| Estado de Energia, Data de Ligação e Tempo Total de Atividade em Minutos | Tempo de atividade da máquina |
Payload do Webhook
Alerta de Porcentagem de Máquinas Não Registradas
{
"text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Unregistered machines (in %)\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"CurrentRegistrationState\":\"Unregistered\",\"FailureDate\":\"<Date of Failure>\",\"FaultState\":\"<Fault State of the Machine>\",\"LifecycleState\":\"<Lifecycle state of the Machine>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"CurrentRegistrationState\":\"Unregistered\",\"FailureDate\":\"<Date of Failure>\",\"FaultState\":\"<Fault State of the Machine>\",\"LifecycleState\":\"<Lifecycle state of the Machine>\"}]}"
}
<!--NeedCopy-->
Alerta de Ações de Inicialização com Falha
{
"text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Failure To PowerOn Action\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure, HypervisorRateLimitExceeded, UnknownError, Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User, Administrator, Auto-Scale, Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure, HypervisorRateLimitExceeded, UnknownError, Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User, Administrator, Auto-Scale, Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"}]}"
}
<!--NeedCopy-->
Alerta de Ações de Desligamento com Falha
{
"text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Failure To PowerOff Action\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IPV4 Address of the Machine>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure,HypervisorRateLimitExceeded,UnknownError,Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User,Administrator,Auto-Scale,Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IPV4 Address of the Machine>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"LastPowerActionFailureReason\":\"<HypervisorReportedFailure,HypervisorRateLimitExceeded,UnknownError,Power Action Type>\",\"LastPowerActionTriggeredBy\":\"<End-User,Administrator,Auto-Scale,Schedule>\",\"LastPowerActionType\":\"<PowerOn/PowerOff>\",\"LastPowerActionCompletedDate\":\"<Time string Eg: 2024-05-15T15:04:27.723>\"}]}"
}
<!--NeedCopy-->
Alerta de Tempo de Atividade da Máquina
{
"text": "{\"Address\":\"<Webhook URL>\",\"NotificationId\":\"<NotificationGUID>\",\"NotificationState\":\"NotificationActive\",\"Priority\":\"<Critical/Warning>\",\"Target\":\"<DeliveryGroupName>\",\"Condition\":\"Machine Uptime Alert\",\"Value\":\"<Value Set as Threshold>\",\"Timestamp\":\"<Timestamp string Eg: April 25, 2024 9:33 PM (UTC +5)>\",\"PolicyName\":\"<Alert Policy Name>\",\"Description\":\"<Alert Policy Description>\",\"Scope\":\"DeliveryGroup\",\"Site\":\"<Name of the Site>\",\"AttachmentData\":[{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"PowerState\":\"<On/Off>\",\"PoweredOnDate\":\"2024-05-15T15:04:27.723\",\"TotalUptimeInMinutes\":180},{\"MachineName\":\"<Name of the Machine>\",\"IPAddress\":\"<IP Address>\",\"DeliveryGroupName\":\"<Name of the DeliveryGroup>\",\"PowerState\":\"<ON/OFF>\",\"PoweredOnDate\":\"2024-05-15T15:04:27.723\",\"TotalUptimeInMinutes\":\"<Uptime Duration>\"}]}"
}
<!--NeedCopy-->
Condições das políticas de alerta
Encontre abaixo as categorias de alerta, as ações recomendadas para mitigar o alerta e as condições de política incorporadas, se definidas. As políticas de alerta incorporadas são definidas para intervalos de alerta e re-alerta de 60 minutos.
Sessões Conectadas de Pico
- Verifique a visualização de Tendências de Sessão do Director para sessões conectadas de pico.
- Verifique se há capacidade suficiente para acomodar a carga da sessão.
- Adicione novas máquinas, se necessário
Sessões Desconectadas de Pico
- Verifique a visualização de Tendências de Sessão do Director para sessões desconectadas de pico.
- Verifique se há capacidade suficiente para acomodar a carga da sessão.
- Adicione novas máquinas, se necessário.
- Faça logoff das sessões desconectadas, se necessário
Sessões Totais Concorrentes de Pico
- Verifique a visualização de Tendências de Sessão no Director para sessões concorrentes de pico.
- Verifique se há capacidade suficiente para acomodar a carga da sessão.
- Adicione novas máquinas, se necessário.
- Faça logoff das sessões desconectadas, se necessário
CPU
A porcentagem de uso da CPU indica o consumo geral da CPU no VDA, incluindo o dos processos. Você pode obter mais informações sobre a utilização da CPU por processos individuais na página “Detalhes da máquina” do VDA correspondente.
- Vá para “Detalhes da Máquina” > “Visualizar Utilização Histórica” > “10 Principais Processos”, identifique os processos que consomem a CPU. Certifique-se de que a política de monitoramento de processos esteja habilitada para iniciar a coleta de estatísticas de uso de recursos em nível de processo.
- Encerre o processo, se necessário.
- Encerrar o processo causa a perda de dados não salvos.
-
Se tudo estiver funcionando conforme o esperado, adicione recursos de CPU adicionais no futuro.
Observação:
A configuração de política “Habilitar monitoramento de recursos” é permitida por padrão para o monitoramento de contadores de desempenho de CPU e memória em máquinas com VDAs. Se essa configuração de política estiver desabilitada, os alertas com condições de CPU e memória não serão acionados. Para obter mais informações, consulte Configurações da política de monitoramento
Condições da política inteligente:
- Escopo: Grupo de Entrega, escopo de SO de Múltiplas Sessões
- Valores de limite: Aviso - 80%, Crítico - 90%
Memória
A porcentagem de uso da Memória indica o consumo geral de memória no VDA, incluindo o dos processos. Você pode obter mais informações sobre o uso da memória por processos individuais na página “Detalhes da máquina” do VDA correspondente.
- Vá para “Detalhes da Máquina” > “Visualizar Utilização Histórica” > “10 Principais Processos”, identifique os processos que consomem memória. Certifique-se de que a política de monitoramento de processos esteja habilitada para iniciar a coleta de estatísticas de uso de recursos em nível de processo.
- Encerre o processo, se necessário.
- Encerrar o processo causa a perda de dados não salvos.
-
Se tudo estiver funcionando conforme o esperado, adicione memória adicional no futuro.
Observação:
A configuração de política “Habilitar monitoramento de recursos” é permitida por padrão para o monitoramento de contadores de desempenho de CPU e memória em máquinas com VDAs. Se essa configuração de política estiver desabilitada, os alertas com condições de CPU e memória não serão acionados. Para obter mais informações, consulte Configurações da política de monitoramento
Condições da política inteligente:
- Escopo: Grupo de Entrega, escopo de SO de Múltiplas Sessões
- Valores de limite: Aviso - 80%, Crítico - 90%
Taxa de Falha de Conexão
Porcentagem de falhas de conexão na última hora.
- Calculado com base no total de falhas em relação ao total de tentativas de conexão.
- Verifique a visualização de Tendências de Falhas de Conexão do Director para eventos registrados no log de Configuração.
- Determine se os aplicativos ou desktops estão acessíveis.
Contagem de Falhas de Conexão
Número de falhas de conexão na última hora.
- Verifique a visualização de Tendências de Falhas de Conexão do Director para eventos registrados no log de Configuração.
- Determine se os aplicativos ou desktops estão acessíveis.
ICA® RTT (Média)
Tempo médio de ida e volta do ICA.
- Verifique o Citrix ADM para obter um detalhamento do RTT do ICA para determinar a causa raiz. Para obter mais informações, consulte a documentação do Citrix ADM.
- Se o Citrix ADM não estiver disponível, verifique a exibição “Detalhes do Usuário” do Director para o RTT do ICA e a Latência, e determine se é um problema de rede ou um problema com aplicativos ou desktops.
RTT do ICA (Nº de Sessões)
Número de sessões que excedem o tempo de ida e volta (RTT) do ICA limite.
- Verifique o Citrix ADM para o número de sessões com RTT do ICA alto. Para obter mais informações, consulte a documentação do Citrix ADM.
-
Se o Citrix ADM não estiver disponível, trabalhe com a equipe de rede para determinar a causa raiz.
Condições da política inteligente:
- Escopo: Grupo de Entrega, escopo de SO de múltiplas sessões
- Valores limite: Aviso - 300 ms para 5 ou mais sessões, Crítico - 400 ms para 10 ou mais sessões
RTT do ICA (% de Sessões)
Porcentagem de sessões que excedem o tempo médio de ida e volta (RTT) do ICA.
- Verifique o Citrix ADM para o número de sessões com RTT do ICA alto. Para obter mais informações, consulte a documentação do Citrix ADM.
- Se o Citrix ADM não estiver disponível, trabalhe com a equipe de rede para determinar a causa raiz.
RTT do ICA (Usuário)
Tempo de ida e volta (RTT) do ICA aplicado às sessões iniciadas pelo usuário especificado. O alerta é acionado se o RTT do ICA for maior que o limite em pelo menos uma sessão.
Máquinas com Falha (SO de sessão única)
Número de máquinas de SO de sessão única com falha. As falhas podem ocorrer por vários motivos, conforme mostrado nas exibições “Painel” e “Filtros” do Director.
-
Execute os diagnósticos do Citrix Scout para determinar a causa raiz.
Condições da política inteligente:
- Escopo: Grupo de Entrega, escopo de SO de múltiplas sessões
- Valores limite: Aviso - 1, Crítico - 2
Máquinas com Falha (SO de múltiplas sessões)
Número de máquinas de SO de múltiplas sessões com falha. As falhas podem ocorrer por vários motivos, conforme mostrado nas exibições “Painel” e “Filtros” do Director.
-
Execute os diagnósticos do Citrix Scout para determinar a causa raiz.
Condições da política inteligente:
- Escopo: Grupo de Entrega, escopo de SO de múltiplas sessões
- Valores limite: Aviso - 1, Crítico - 2
Máquinas com Falha (em %)
A porcentagem de máquinas de SO de sessão única e de múltiplas sessões com falha em um grupo de entrega, calculada com base no número de máquinas com falha. Esta condição de alerta permite configurar limites de alerta como uma porcentagem de máquinas com falha em um grupo de entrega e é calculada a cada 30 segundos. As falhas podem ocorrer por vários motivos, conforme mostrado nas exibições “Painel” e “Filtros” do Director. Execute os diagnósticos do Citrix Scout para determinar a causa raiz. Para obter mais informações, consulte Solucionar problemas do usuário.
Ação de ligar com falha e ação de desligar com falha
Número de ações de ligar com falha e número de ações de desligar com falha em um grupo de entrega, calculado com base no número de Máquinas Gerenciadas por Energia que falharam ao ligar ou desligar. Esta condição de alerta permite configurar limites de alerta como o número de Máquinas Gerenciadas por Energia que falharam ao ligar ou desligar em um grupo de entrega e é calculada a cada 30 minutos.
O administrador pode configurar os seguintes parâmetros para esses alertas na política de alerta avançada:
- Acionado por: O que acionou a ação de energia
- Motivo da falha: Por que a ação falhou
- Limite: Número limite de máquinas que falharam na ação de energia para acionar a política
- Intervalo de amostragem: O intervalo no qual a ação de energia com falha deve ser verificada
- Intervalo de re-alerta: Após quanto tempo o alerta deve ser reenviado
As falhas podem ocorrer por vários motivos, conforme mostrado nas exibições “Painel” e “Filtros” do Director. Execute os diagnósticos do Citrix Scout para determinar a causa raiz. Para obter mais informações, consulte Solucionar problemas do usuário.
Máquinas não Registradas (em %)
Uma máquina é considerada não registrada quando se torna instável devido a uma reinicialização ou quando há um problema de comunicação entre o controlador de entrega e as máquinas virtuais. As Máquinas não Registradas (em %) representam a porcentagem de máquinas de SO de sessão única e de múltiplas sessões não registradas em um grupo de entrega, calculada com base no número de máquinas não registradas. Esta condição de alerta permite configurar valores limite de aviso e crítico como uma porcentagem de máquinas não registradas em um grupo de entrega. Você pode definir um intervalo para re-alerta. Você também pode adicionar um e-mail para receber uma notificação quando as condições forem atendidas para Máquinas não Registradas (em %). Quando o valor limite crítico ou de aviso é excedido, alertas e e-mails são gerados. Você pode visualizar os alertas em Alertas do Citrix. Você pode filtrá-lo pela categoria Máquinas não Registradas (em %) e para o estado e tempo necessários.
Você também pode receber detalhes do alerta em um anexo CSV se houver um e-mail ou por meio de um payload JSON se houver um webhook.
Nota:
O valor crítico deve ser maior que o valor de aviso.
Condições da política:
- Escopo: Grupo de Entrega de SO de sessão única e de múltiplas sessões
- Valores limite: Aviso e Crítico
Alerta de tempo de atividade da máquina
O tempo de atividade da máquina em um grupo de entrega é calculado com base no número de horas por dia, horas por semana ou horas por mês para uma máquina que está ligada em um grupo de entrega. Esta condição de alerta permite configurar limites de alerta como as horas em que uma máquina é ligada em um grupo de entrega. Os alertas de tempo de atividade da máquina funcionam da seguinte forma no caso de:
- Horas por dia - Você pode especificar o número de horas em que uma máquina é ligada por dia e é calculado a cada 30 minutos. O número máximo de horas por dia que você pode definir é de 24 horas.
- Horas por semana - Você pode especificar o número de horas em que uma máquina é ligada por semana e é calculado a cada seis horas. O número máximo de horas por semana que você pode definir é de 168 horas.
- Horas por mês - Você pode especificar o número de horas em que uma máquina é ligada por mês e é calculado uma vez por dia. O número máximo de horas por mês é de 720 horas. O valor mínimo do intervalo de re-alerta que você pode definir é de 60 minutos. Você pode inserir o número de máquinas que excedem o valor limite de tempo de atividade da máquina na seção de alertas de Aviso e Crítico. Você também pode adicionar exceções para quaisquer máquinas.
Por exemplo, se houver cinco grupos de entrega adicionados para este alerta e se no primeiro grupo de entrega e no quarto grupo de entrega, o número de máquinas exceder os valores limite de aviso ou crítico, o alerta será acionado separadamente para o primeiro grupo de entrega e para o quarto grupo de entrega.
Este alerta ajuda os administradores a analisar o tempo de atividade das máquinas e, com base nesta análise, os administradores podem ajudar na otimização dos custos. Você também pode receber detalhes do alerta em um anexo CSV se houver um e-mail ou por meio de um payload JSON se houver um webhook.
Duração Média do Logon
Duração média do logon para logons que ocorreram na última hora.
- Verifique o “Painel” do Director para obter métricas atualizadas sobre a duração do logon. Muitos usuários fazendo logon em um curto período de tempo podem aumentar a duração do logon.
-
Verifique a linha de base e o detalhamento dos logons para identificar a causa. Para obter mais informações, consulte Diagnosticar problemas de logon do usuário
Condições da política inteligente:
- Escopo: Grupo de Entrega, escopo de SO de múltiplas sessões
- Valores limite: Aviso - 45 segundos, Crítico - 60 segundos
Duração do Logon (Usuário)
Duração do logon para logons do usuário especificado que ocorreram na última hora.
Índice do Avaliador de Carga
Valor do Índice do Avaliador de Carga nos últimos 5 minutos.
-
Verifique o Director para Máquinas de SO de múltiplas sessões que possam ter uma carga de pico (Carga Máxima). Visualize tanto o “Painel” (falhas) quanto o relatório de “Tendências do Índice do Avaliador de Carga”.
Condições da política inteligente:
- Escopo: Grupo de Entrega, escopo de SO de múltiplas sessões
- Valores limite: Aviso - 80%, Crítico - 90%
Configurar políticas de alerta com webhooks
Além das notificações por e-mail, você pode configurar políticas de alerta com webhooks.
Nota: Este recurso requer o(s) Delivery Controller(s) versão 7.11 ou posterior.
Você pode configurar uma política de alerta com um retorno de chamada HTTP ou um POST HTTP usando cmdlets do PowerShell. Eles foram estendidos para oferecer suporte a webhooks.
Para obter informações sobre a criação de um novo fluxo de trabalho do Octoblu e a obtenção da URL de webhook correspondente, consulte o Octoblu Developer Hub.
Para configurar uma URL de webhook para uma nova política de alerta ou para uma política existente, use os seguintes cmdlets do PowerShell.
Crie uma nova política de alertas com uma URL de webhook:
$policy = New-MonitorNotificationPolicy -Name <Policy name> -Description <Policy description> -Enabled $true -Webhook <Webhook URL>
<!--NeedCopy-->
Adicione uma URL de webhook a uma política de alertas existente:
Set-MonitorNotificationPolicy - Uid <Policy id> -Webhook <Webhook URL>
<!--NeedCopy-->
Para obter ajuda sobre os comandos do PowerShell, use a ajuda do PowerShell, por exemplo:
Get-Help <Set-MonitorNotificationPolicy>
<!--NeedCopy-->
As notificações geradas a partir da política de alerta acionam o webhook com uma chamada POST para a URL do webhook. A mensagem POST contém as informações de notificação no formato JSON:
{"NotificationId" : \<Notification Id\>,
"Target" : \<Notification Target Id\>,
"Condition" : \<Condition that was violated\>,
"Value" : \<Threshold value for the Condition\>,
"Timestamp": \<Time in UTC when notification was generated\>,
"PolicyName": \<Name of the Alert policy\>,
"Description": \<Description of the Alert policy\>,
"Scope" : \<Scope of the Alert policy\>,
"NotificationState": \<Notification state critical, warning, healthy or dismissed\>,
"Site" : \<Site name\>}
<!--NeedCopy-->
Descarte de alertas em massa
Este recurso otimiza o processo de gerenciamento de alertas para administradores, proporcionando flexibilidade e reduzindo a fadiga de alertas. Os administradores podem descartar alertas em massa com base no tempo, tipo ou categoria, simplificando o gerenciamento de alertas durante a manutenção ou ao lidar com hipervisores e outros ambientes.
O descarte de alertas em massa ajuda os administradores a gerenciar sua carga de trabalho de forma eficiente e os impede de serem sobrecarregados por um alto volume de alertas.
Etapas para dispensar alertas em massa
-
Vá para a guia Alertas > Alertas do Citrix. Os alertas são exibidos.
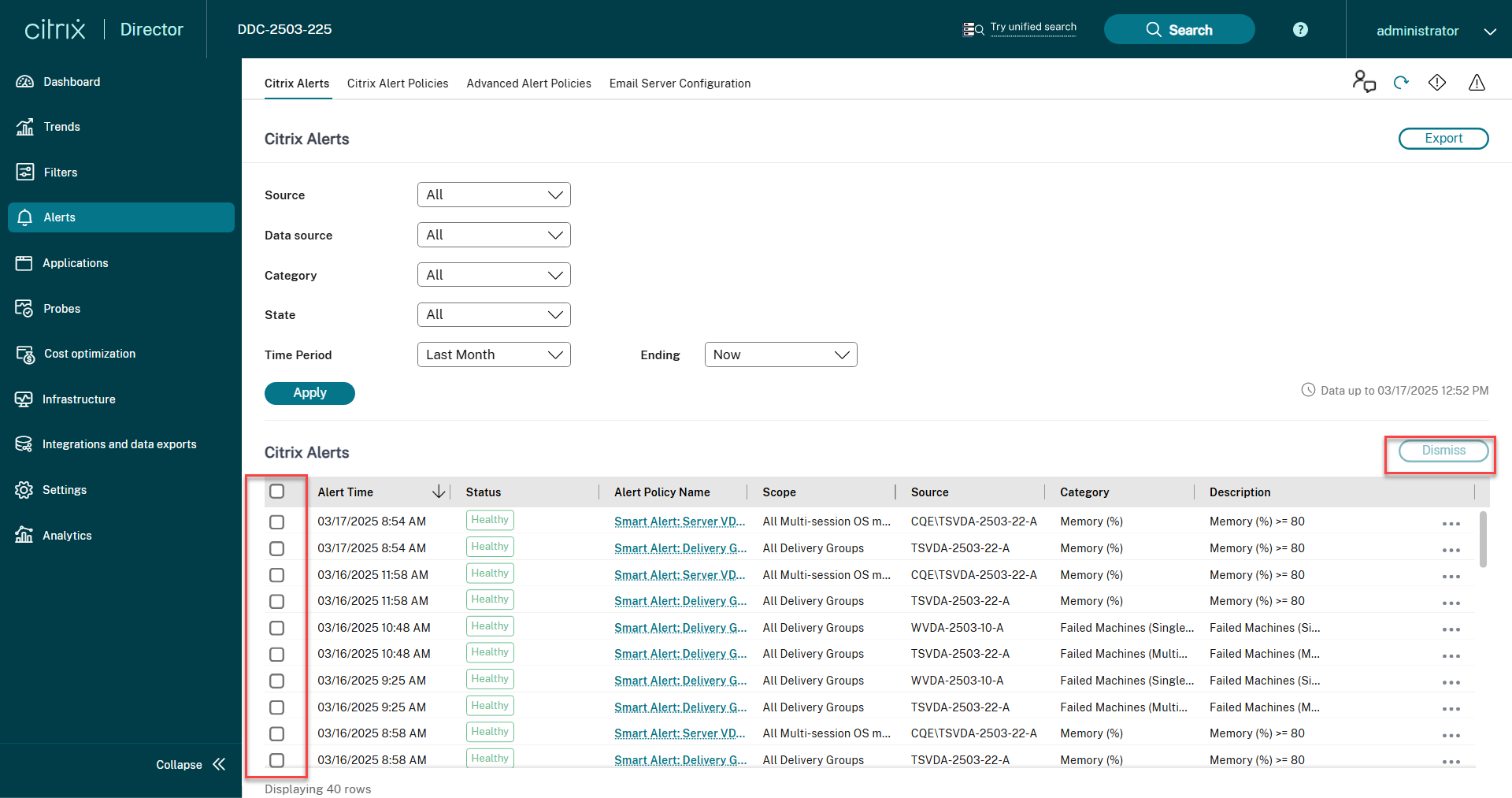
- Selecione uma opção em Origem, Categoria, Estado ou Período para filtrar os alertas que você deseja dispensar. Os alertas específicos são exibidos.
- Marque a caixa de seleção ao lado de um alerta específico ou na parte superior para selecionar todos os alertas.
- Clique em “Dispensar”. Uma notificação aparece para confirmar a dispensa dos alertas.
- Clique em “Sim”. Os alertas selecionados são marcados como dispensados e o status do alerta é atualizado de acordo.
Configuração de webhook usando o SDK do PowerShell
O recurso de configuração de webhook usando o SDK do PowerShell permite que os administradores criem, modifiquem, excluam e listem perfis de webhook. Esse recurso oferece flexibilidade na configuração de webhooks, permitindo a especificação de cabeçalhos, tipos de autenticação, tipos de conteúdo, payloads e URLs de webhook.
Nota:
O formato de payload compatível é texto, e o usuário final deve habilitar o texto em seu webhook.
O formato de payload mais recente é:
{"text": "This is a message from a Webex incoming webhook."}
<!--NeedCopy-->
Criar um webhook
Você pode usar o seguinte comando de exemplo do PowerShell para criar um perfil de webhook:
Para criar um webhook sem cabeçalho de autorização:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$payloads = '{ "text": "$PAYLOAD" }'
$url = "<Fill this field with the required URL>"
Add-MonitorWebhookProfile -Name "profile_slack" -Description "webhook profile for slack" -Url $url -Headers $headers -PayloadFormat $payloads
<!--NeedCopy-->
Para criar um webhook com cabeçalho de autorização:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$headers.Add("Authorization", "Basic <Fill this field with the authorization token>")
$payloads = '{ "text": "$PAYLOAD" }'
$url = "<Fill this field with the required URL>"
Add-MonitorWebhookProfile -Name "profile_azure" -Description "webhook profile for azure function with Authentication" -Url $url -Headers $headers -PayloadFormat $payloads
<!--NeedCopy-->
Depois que o perfil for criado, você poderá verificá-lo no banco de dados. Além disso, você pode encontrar o perfil de webhook recém-criado na página Alertas do Citrix.
Atualizar um perfil de webhook
Você pode usar o seguinte comando de exemplo do PowerShell para atualizar um perfil de webhook:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$payloads = '{ "text": "$PAYLOAD" }'
$url = "<Fill this field with the required URL>"
Set-MonitorWebhookProfile -Uid 1 -Name "profile_slack_citrix" -Description "webhook profile for citrix slack" -Url $url -Headers $headers -PayloadFormat $payloads
<!--NeedCopy-->
Obter uma lista de todos os perfis de webhook
Você pode usar o seguinte comando de exemplo do PowerShell para obter uma lista de todos os perfis de webhook disponíveis:
Get-MonitorWebhookProfile
Get-MonitorWebhookProfile -Name 'profile_msteams'
Get-MonitorWebhookProfile -Uid 1
<!--NeedCopy-->
Remover um perfil de webhook
Você pode usar o seguinte comando de exemplo do PowerShell para remover um perfil de webhook:
Remove-MonitorWebhookProfile -Uid 1
<!--NeedCopy-->
Nota:
Se um perfil de webhook estiver mapeado para alguma política, ele não poderá ser removido. Como solução alternativa, você deve primeiro remover o mapeamento do webhook da política.
Criar uma política com perfil de webhook
Você pode usar o seguinte comando de exemplo do PowerShell para criar uma política com perfil de webhook:
New-MonitorNotificationPolicy -Name "Policy1" -Description "Policy Description" -Enabled $true -WebhookProfileId 1
<!--NeedCopy-->
Atualizar uma política com perfil de webhook
Você pode usar o seguinte comando de exemplo do PowerShell para atualizar uma política com perfil de webhook:
$Policy = Set-MonitorNotificationPolicy -Uid 1 -WebhookProfileId 1
<!--NeedCopy-->
Remover mapeamento de webhook de uma política
Você pode usar o seguinte comando de exemplo do PowerShell para remover o perfil de webhook de uma política:
$Policy = Set-MonitorNotificationPolicy -Uid 1 -WebhookProfileId 0
<!--NeedCopy-->
Testar perfil de webhook
Você pode usar o seguinte comando de exemplo do PowerShell para testar o perfil de webhook:
$headers = [System.Collections.Generic.Dictionary[string,string]]::new()
$headers.Add("Content-Type", "application/json")
$headers.Add("Authorization", "Basic <Fill this with authorization token>")
$payloads = '{ "text": "$PAYLOAD" }'
$url ="<Fill this field with the required URL>"
Test-MonitorWebhookProfile -Url $url -Headers $headers -PayloadFormat $payloads
<!--NeedCopy-->
Monitoramento de alertas do hypervisor
O Director exibe alertas para monitorar a integridade do hypervisor. Alertas do XenServer® e VMware vSphere ajudam a monitorar parâmetros e estados do hypervisor. O status da conexão com o hypervisor também é monitorado para fornecer um alerta se o cluster ou pool de hosts for reiniciado ou estiver indisponível.
Para receber alertas do hypervisor, certifique-se de que uma conexão de hospedagem seja criada no Web Studio. Para obter mais informações, consulte Conexões e recursos. Somente essas conexões são monitoradas para alertas do hypervisor.
Esses alertas são exibidos quando os limites são atingidos ou excedidos. Os alertas do hypervisor podem ser:
- Crítico — limite crítico da política de alarme do hypervisor atingido ou excedido
- Aviso — limite de aviso da política de alarme do hypervisor atingido ou excedido
- Dispensado — alerta não é mais exibido como um alerta ativo
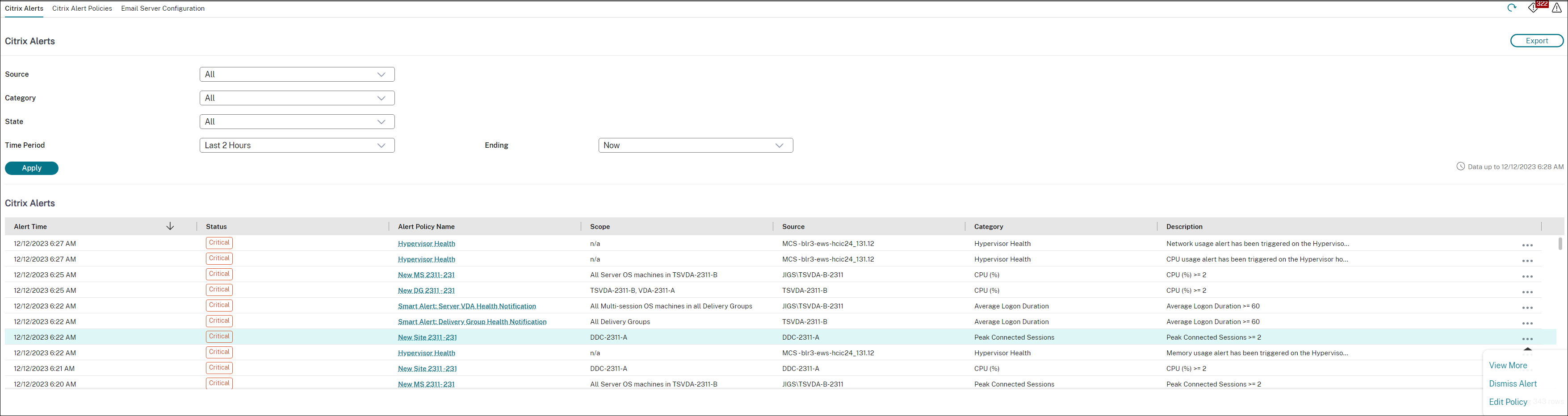
Este recurso requer o Delivery Controller versão 7 1811 ou posterior. Se você estiver usando uma versão mais antiga do Director com sites 7 1811 ou posterior, somente a contagem de alertas do hypervisor será exibida. Para visualizar os alertas, você deve atualizar o Director.
A tabela a seguir descreve os vários parâmetros e estados dos alertas do Hypervisor.
| Alerta | Hypervisores compatíveis | Acionado por | Condição | Configuração |
|---|---|---|---|---|
| Uso da CPU | XenServer, VMware vSphere | Hypervisor | O limite de alerta de uso da CPU é atingido ou excedido | Os limites de alerta devem ser configurados no Hypervisor. |
| Uso da memória | XenServer, VMware vSphere | Hypervisor | O limite de alerta de uso da memória é atingido ou excedido | Os limites de alerta devem ser configurados no Hypervisor. |
| Uso da rede | XenServer, VMware vSphere | Hypervisor | O limite de alerta de uso da rede é atingido ou excedido | Os limites de alerta devem ser configurados no Hypervisor. |
| Uso do disco | VMware vSphere | Hypervisor | O limite de alerta de uso do disco é atingido ou excedido | Os limites de alerta devem ser configurados no Hypervisor. |
| Conexão do host ou estado de energia | VMware vSphere | Hypervisor | O host do hypervisor foi reiniciado ou está indisponível | Os alertas são pré-construídos no VMware vSphere. Nenhuma configuração adicional é necessária. |
| Conexão do hypervisor indisponível | XenServer, VMware vSphere | Delivery Controller | A conexão com o hypervisor (pool ou cluster) é perdida, desligada ou reiniciada. Este alerta é gerado a cada hora enquanto a conexão estiver indisponível. | Os alertas são pré-construídos com o Delivery Controller. Nenhuma configuração adicional é necessária. |
Nota:
Para obter mais informações sobre a configuração de alertas, consulte Alertas do Citrix XenCenter ou verifique a documentação de alertas do VMware vCenter.
A preferência de notificação por e-mail pode ser configurada em Política de Alertas do Citrix > Política do Site > Integridade do Hypervisor. As condições de limite para políticas de alerta do Hypervisor podem ser configuradas, editadas, desabilitadas ou excluídas somente do hypervisor e não do Director. No entanto, a modificação das preferências de e-mail e a dispensa de um alerta podem ser feitas no Director. Você pode desabilitar o alerta se sua função não envolver o monitoramento da infraestrutura.
Importante:
- Os alertas acionados pelo Hypervisor são buscados e exibidos no Director. No entanto, as alterações no ciclo de vida/estado dos alertas do Hypervisor não são refletidas no Director.
- Os alertas que estão saudáveis, dispensados ou desabilitados no console do Hypervisor continuam a aparecer no Director e devem ser dispensados explicitamente.
- Os alertas dispensados no Director não são dispensados automaticamente no console do Hypervisor.
Tratamento aprimorado de alertas de balanceamento de carga vertical e horizontal
Anteriormente, quando você definia UseVerticalScalingForRdsLaunches como verdadeiro e configurava a política “Número máximo de sessões” no Studio, as máquinas passavam para o estado de “Capacidade máxima”. O Director acionava alertas para “Capacidade máxima” independentemente de o limite ter sido atingido devido ao balanceamento de carga vertical ou horizontal. Não havia como distinguir entre balanceamento de carga vertical e horizontal ao encontrar erros específicos, como “Carga máxima atingida”. Isso causava alertas desnecessários para o comportamento esperado em cenários de escalonamento vertical, desperdiçando seu tempo e criando confusão.
Agora, quando o balanceamento de carga vertical está ativo e uma máquina atinge seu limite de sessão, ela passa para um novo estado: “Capacidade máxima para escalonamento vertical”. O Director não gera mais alertas para esse novo estado. Os alertas são acionados apenas para “Capacidade máxima” em cenários de balanceamento de carga horizontal. Você pode visualizar o novo estado nas páginas Filtros e Relatórios personalizados, facilitando a distinção entre condições esperadas e excepcionais. Esse aprimoramento ajuda você a evitar alertas desnecessários e a se concentrar em problemas reais, otimizando o monitoramento e a solução de problemas. Ele se aplica quando você configura UseVerticalScalingForRdsLaunches usando Set-BrokerSite e define a política “Número máximo de sessões” no Studio.
Neste artigo
- Alertas Citrix®
- Políticas de alerta inteligentes
- Políticas de alerta avançadas
- Criar políticas de alerta
- Condições das políticas de alerta
- Configurar políticas de alerta com webhooks
- Descarte de alertas em massa
- Configuração de webhook usando o SDK do PowerShell
- Monitoramento de alertas do hypervisor