Arquitectura de Splunk con la aplicación de complemento de Citrix Analytics
Splunk sigue una arquitectura que contiene los tres niveles siguientes:
- Recopilación
- Indexación
- Búsqueda
Splunk admite una amplia gama de mecanismos de recopilación de datos que ayudan a ingestar datos en Splunk fácilmente, de modo que se puedan indexar y poner a disposición para la búsqueda. Este nivel no es más que tu reenviador pesado o reenviador universal.
Debes instalar la aplicación de complemento en la capa del reenviador pesado en lugar de en la capa del reenviador universal. Esto se debe a que, con algunas excepciones para datos bien estructurados (como json, csv, tsv), el reenviador universal no analiza las fuentes de registro en eventos, por lo que no puede realizar ninguna acción que requiera comprender el formato de los registros.
También incluye una versión reducida de Python, lo que la hace incompatible con cualquier aplicación de entrada modular que requiera una pila completa de Splunk para funcionar. El reenviador pesado no es más que tu nivel de recopilación.
La diferencia clave entre un reenviador universal y un reenviador pesado es que el reenviador pesado contiene la canalización de análisis completa, realizando las mismas funciones que realiza un indexador sin escribir ni indexar eventos en el disco. Esto permite que el reenviador pesado comprenda y actúe sobre eventos individuales, como el enmascaramiento de datos, el filtrado y el enrutamiento basado en los datos del evento. Dado que la aplicación de complemento tiene una instalación completa de Splunk Enterprise, puede alojar entradas modulares que requieren una pila completa de Python para una recopilación de datos adecuada, o actuar como un punto de conexión para el Recopilador de eventos HTTP (HEC) de Splunk.
Una vez que se recopilan los datos, se indexan o procesan y se almacenan de una manera que los hace buscables.
La forma principal en que los clientes exploran sus datos es a través de la búsqueda. Una búsqueda se puede guardar como un informe y usarse para alimentar los paneles del panel de control. Las búsquedas extraen información de tus datos.
En general, la aplicación de complemento de Splunk se implementa en el nivel de recopilación (a nivel de Splunk Enterprise), mientras que nuestra aplicación de paneles de control se implementa en la capa de búsqueda (a nivel de Splunk Cloud). En una configuración local simple, puedes tener estos tres niveles en un único host de Splunk (conocido como implementación de servidor único).
El nivel de recopilación es una forma mucho mejor de usar la aplicación de complemento para Splunk. Hay dos formas de instalar la aplicación de complemento. Puedes instalarla en el nivel de recopilación dentro del entorno del cliente o puedes instalarla en el administrador de entradas de datos dentro de la instancia de Splunk Cloud.
Consulta el siguiente diagrama para comprender la arquitectura de implementación de Splunk con nuestra aplicación de complemento:
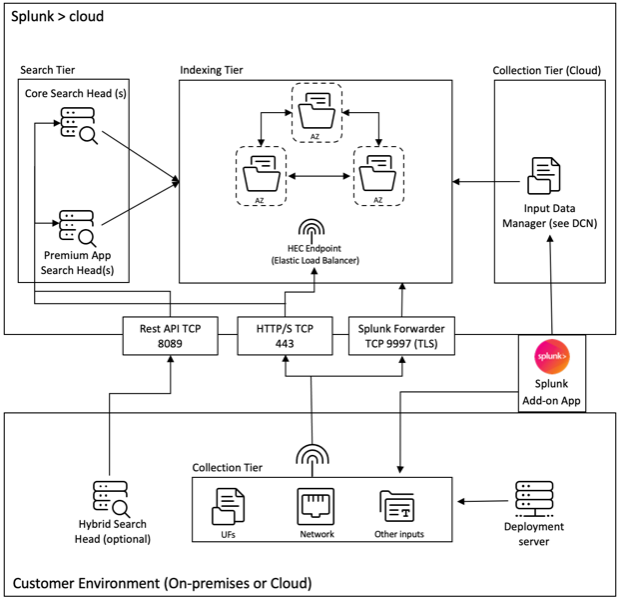
El Administrador de entradas de datos (IDM) que se muestra en el diagrama anterior es la implementación administrada por Splunk Cloud de un Nodo de recopilación de datos (DCN) que solo admite entradas con script y modulares. Para necesidades de recopilación de datos más allá de eso, puedes implementar y administrar un DCN en tu entorno usando un reenviador pesado de Splunk.
Splunk permite recopilar, indexar y buscar datos de varias fuentes. Una forma de recopilar datos es a través de API, lo que permite a Splunk acceder a los datos almacenados en otros sistemas o aplicaciones. Estas API pueden incluir REST, servicios web, JMS y/o JDBC como mecanismo de consulta. Splunk y cualquier desarrollador externo ofrecen una gama de aplicaciones que permiten interacciones de API a través del marco de entrada modular de Splunk. Estas aplicaciones suelen requerir una instalación completa del software Splunk Enterprise para funcionar correctamente.
Para facilitar la recopilación de datos a través de API, es común implementar un reenviador pesado como DCN. Los reenviadores pesados son agentes más potentes que los reenviadores universales, ya que contienen la canalización de análisis completa y pueden comprender y actuar sobre eventos individuales. Esto les permite recopilar datos a través de API y procesarlos antes de reenviarlos a una instancia de Splunk para su indexación.
Para comprender más sobre la arquitectura de alto nivel de una implementación de Splunk Cloud, consulta Splunk Validated Architectures.