洞察
“洞察”面板提供有关环境中会话失败或缓慢的信息。借助这些洞察深入研究特定指标有助于更快地排查和解决会话失败或缓慢问题。故障洞察尤其有助于管理员提高会话可用性,这是决定用户体验的重要因素。这些洞察旨在帮助主动监视用户体验。因此,系统会显示当前故障的洞察(每 15 分钟刷新一次)。
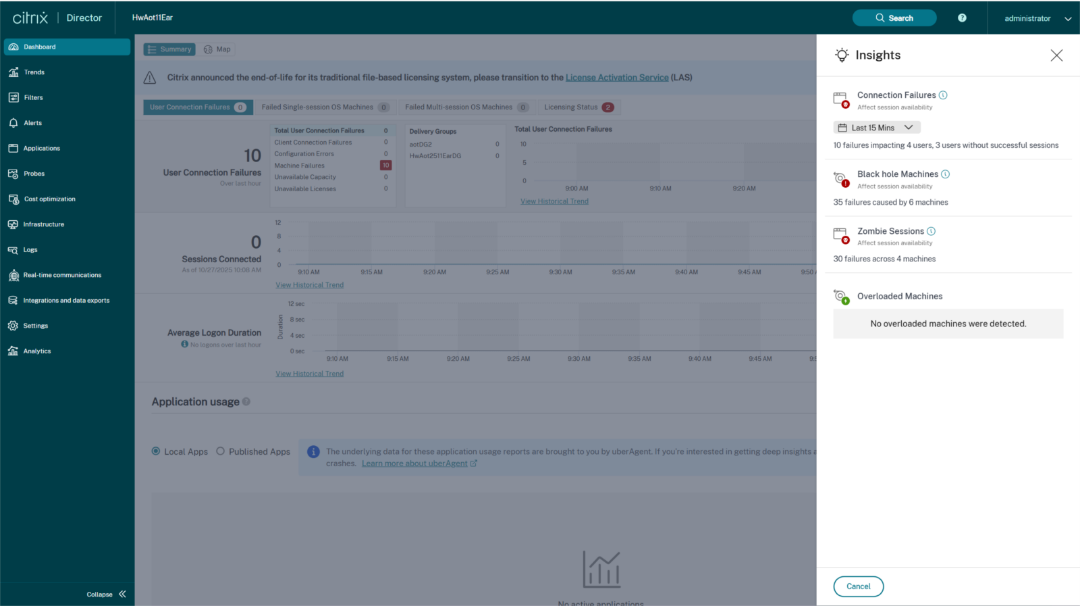
单击“控制板”中的洞察图标,将显示洞察窗格,其中包含有关洞察的详细信息以及深入到“计算机”或“连接”视图的选项。管理员还可以从面板导航到警报配置。
此面板上提供黑洞计算机、僵尸会话、过载计算机和会话故障洞察。展开每个洞察时,都会显示指向失败会话或托管这些会话的计算机的链接。这将转到包含失败计算机或会话的“筛选器”视图。单击特定计算机或会话以查看详细指标时,可以从此处进一步深入。
-
每个洞察的展开视图显示了针对站点、交付组、单会话或多会话操作系统计算机检测到的主要故障模式。这些模式旨在帮助管理员发现是否存在遇到此问题的特定用户群。如果系统由于分布式用户群而无法突出显示任何模式,建议深入进行自我分析。此外,还会显示建议用于排查和解决问题的操作。
-
黑洞计算机
- 环境中的某些计算机虽然已注册且看起来正常,但可能无法为其代理的会话提供服务,从而导致故障。未能为四个或更多连续会话请求提供服务的计算机称为黑洞计算机。这些故障的原因与可能影响计算机的各种因素有关,例如 RDS 许可证不足、间歇性网络问题或计算机上的瞬时负载。这些故障不包括由于容量或许可证可用性导致的故障。环境中存在黑洞计算机增加了会话故障,导致会话可用性不佳。“黑洞计算机”洞察显示环境中识别出的黑洞计算机数量。
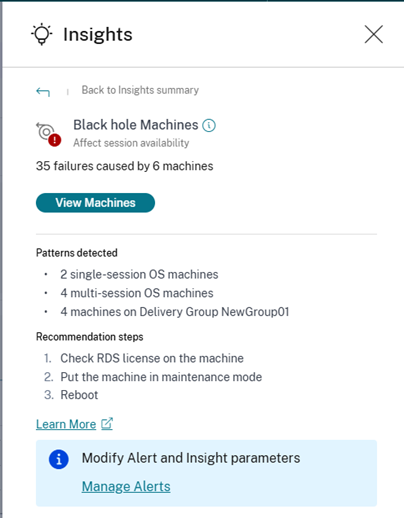
黑洞计算机的建议操作:
- 检查计算机上的 RDS 许可证
- 将计算机置于维护模式
-
重新启动
-
“检测到的模式”部分显示了在黑洞计算机中观察到的主要模式,具体取决于以下条件:
- 运行单会话或多会话操作系统的黑洞计算机数量
-
受影响计算机数量最多的交付组
-
僵尸会话
- “僵尸会话”子窗格显示有关环境中因僵尸会话而发生的会话故障的信息。僵尸会话是单会话操作系统计算机上已放弃的会话,导致在该计算机上启动新会话失败。尝试在此计算机上启动会话会因“容量不可用”错误而失败。在终止已放弃的会话之前,所有将来的会话启动尝试都将失败。僵尸会话洞察旨在帮助发现具有已放弃会话的这些计算机并主动缓解这些故障。
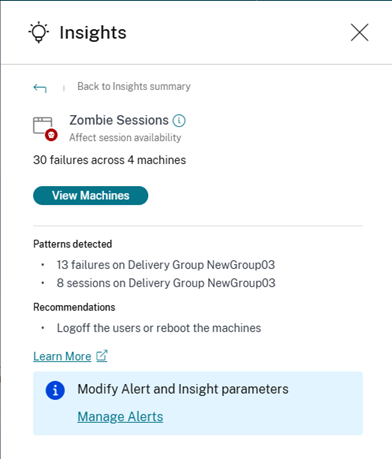
僵尸会话的建议操作:
- 您可以使用适用于 Citrix DaaS 站点的 Monitor 将用户从僵尸会话中注销。
-
您可以重新启动包含僵尸会话的计算机。
-
“检测到的模式”部分显示了在僵尸会话中观察到的主要模式,具体取决于以下条件:
- 受影响计算机数量最多的交付组
-
受影响会话数量最多的交付组
-
过载计算机
- “过载计算机”洞察可让您了解导致体验不佳的过载资源。持续出现 CPU 峰值或高内存使用率(或两者兼有)且持续 5 分钟或更长时间的计算机,如果可能导致用户体验不佳,则被视为过载。
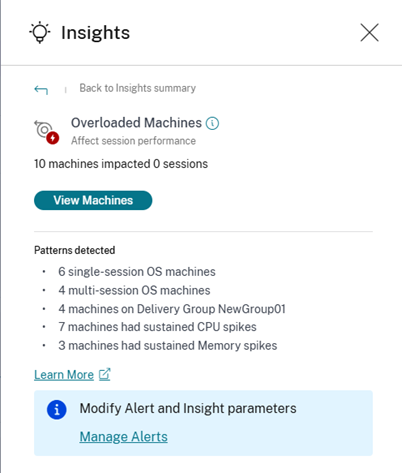
“检测到的模式”部分显示了在过载计算机中观察到的主要模式,具体取决于以下条件:
- 运行单会话或多会话操作系统的过载计算机数量
- 受影响计算机数量最多的交付组
- 具有持续内存或 CPU 峰值的过载计算机数量
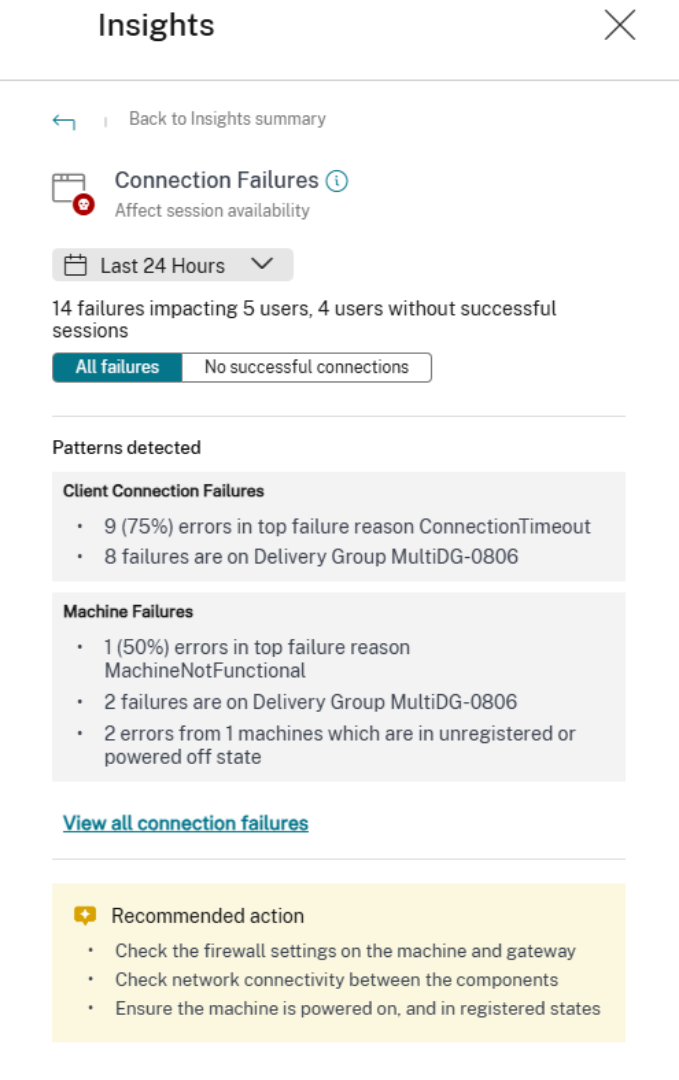
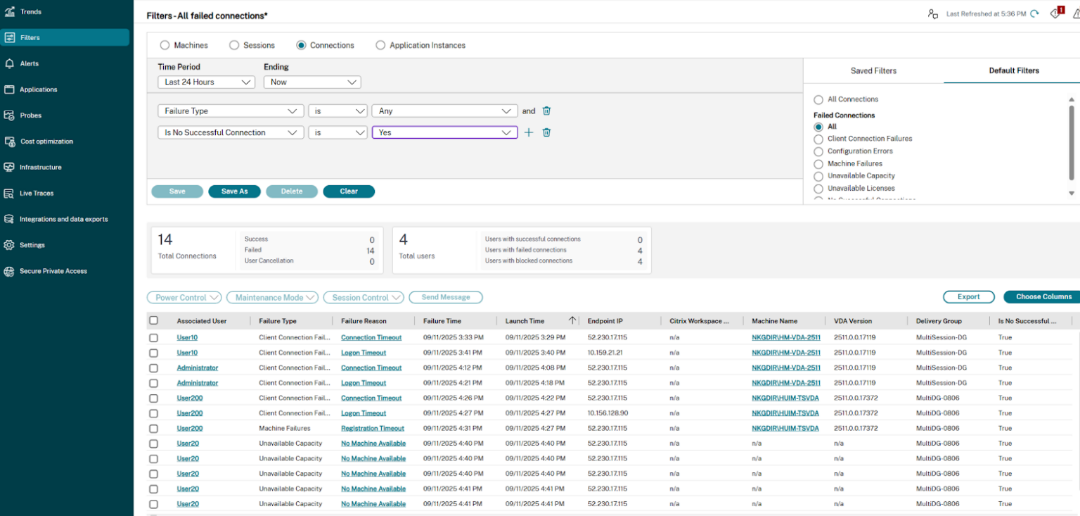
连接故障
“连接故障”洞察列出了由于从端点(用户启动会话的位置)到计算机(代理会话的位置)之间的问题而导致的会话故障数量。这些故障可能由于各种原因而发生,例如防火墙配置不正确、网络通信问题或计算机不可用。
-
-
连接故障的两个类别是:
- 客户端连接故障 — 列出端点上发生通信错误的会话。
- 计算机故障 — 列出计算机上发生错误的会话。
此外,“连接故障”子面板显示以下建议以解决错误。
- 检查计算机和网关上的防火墙设置。
- 检查组件之间的网络连接。
- 确保计算机已开机并处于已注册状态。
故障被分组以识别被阻止的用户,即在选定时间段内连接失败后未成功进行任何会话的用户。突出显示了这两种故障类别的模式。单击详细信息将打开“连接”视图,该视图经过筛选,可显示在选定时间内由于环境中错误而失败的所有会话。此视图有助于分析失败的各个会话并找出可能的根本原因。
筛选器视图
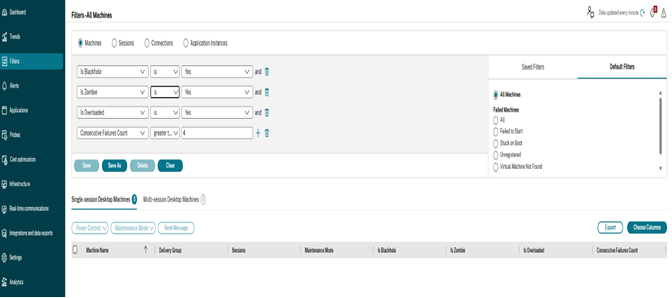
以下是“筛选器”->“计算机”下的“计算机”视图中添加的新筛选器和列:
- 连续故障计数:计算机报告的连续会话启动失败次数
- 是否为黑洞:计算机是否已被识别为黑洞计算机
- 是否为僵尸:计算机是否已被识别为僵尸计算机
- 是否过载:计算机是否已被识别为过载计算机
以下是“筛选器”->“连接”下的“连接”视图中添加的新筛选器和列:
警报
系统中有 3 个新的“高级警报策略”可用并默认启用,通过在识别出黑洞、僵尸或过载计算机(跨所有交付组)时主动发出警报来帮助管理员。
注意:
在当前版本中,“高级警报策略”不支持连接失败。

管理默认策略
为了最大限度地发挥诊断洞察的价值,以下是有关默认警报策略的几个要点:
- 自定义:管理员可以自定义这些默认策略的警报策略参数、范围或通知操作。
- 限制:您无法更改条件或删除默认策略。
- 启用/禁用:可以根据需要禁用或启用策略。
- 通知:默认策略未配置通知;它们只会导致UI 警报。我们强烈建议管理员更新这些策略上的通知首选项。
注意:
洞察面板本身依赖于已启用的策略。如果禁用默认策略且没有启用自定义策略,则洞察面板将停止刷新。
更新警报参数也会改变仪表板上相应洞察的计算。
创建自定义策略
您可以为这些洞察创建额外的自定义策略。如果创建自定义策略,我们建议修改默认策略的范围,以排除您的自定义策略所涵盖的任何交付组。这可以防止重叠和潜在的重复警报。
警报通知
以下是针对洞察提出的“Citrix 警报”的快速视图:
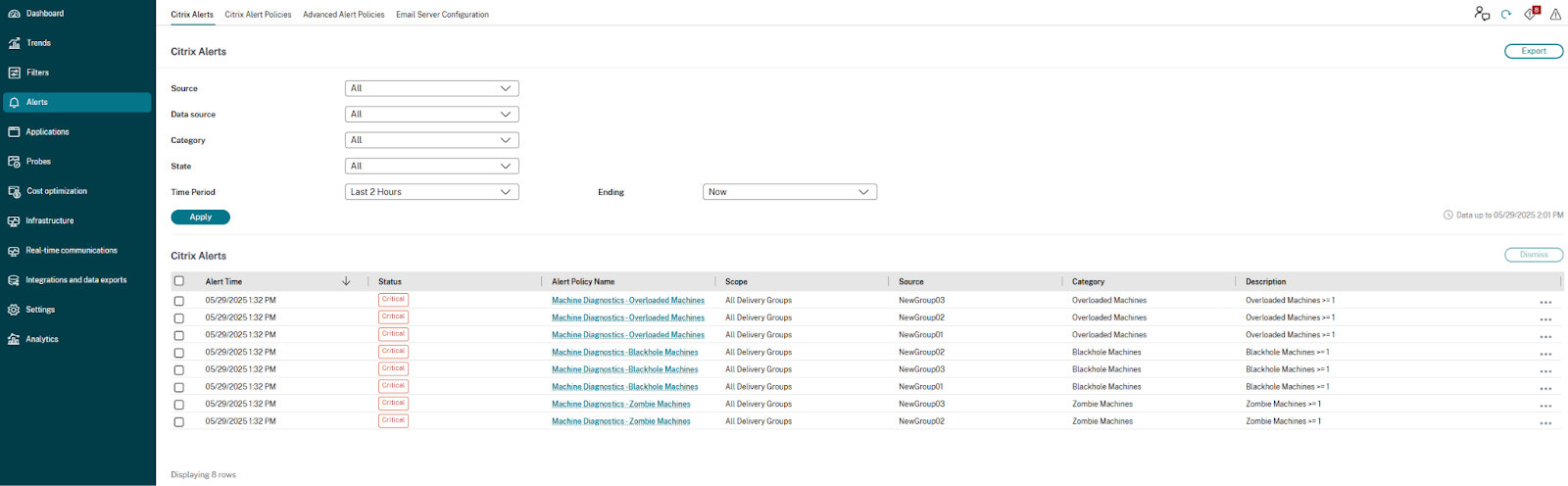
黑洞计算机警报
监视器每 15 分钟扫描一次黑洞计算机,并向管理员发送警报,以主动缓解用户面临的会话失败。默认情况下,未能处理四个或更多连续会话请求的计算机被称为黑洞计算机。可以为选定的警报自定义警报条件和重新警报间隔。
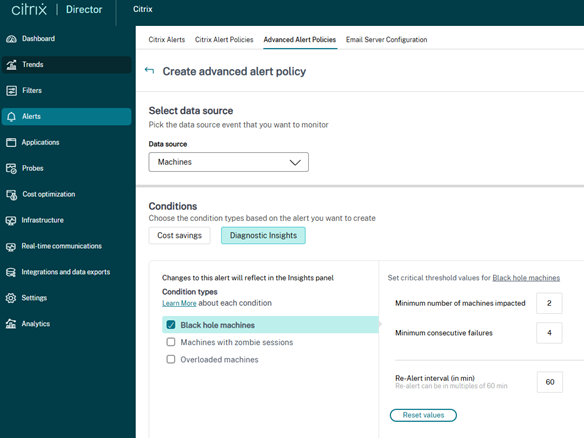
导致会话失败的计算机详细信息将通过警报电子邮件或 Webhook 有效负载发送。必须启用黑洞计算机警报策略才能接收这些通知。
僵尸会话计算机警报
当在 15 分钟间隔内环境中检测到具有僵尸会话的新计算机时,将生成僵尸会话计算机警报。
管理员可以自定义僵尸会话计算机警报的警报条件。
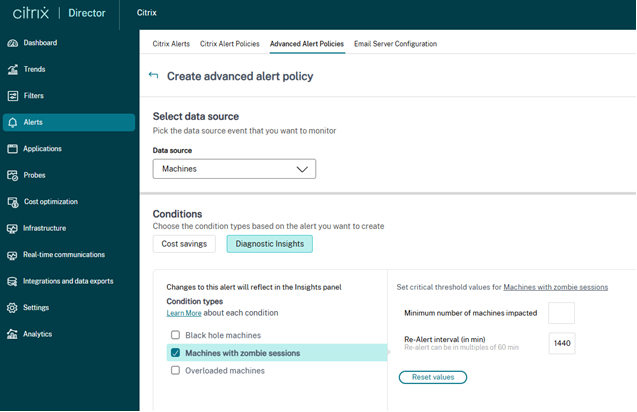
导致僵尸会话和失败的计算机详细信息将通过警报电子邮件或 Webhook 有效负载发送。
过载计算机警报
在配置的采样间隔内,经历持续 CPU 峰值、高内存使用率或两者兼有的计算机被视为过载。
管理员可以自定义过载计算机警报的警报条件和重新警报首选项。
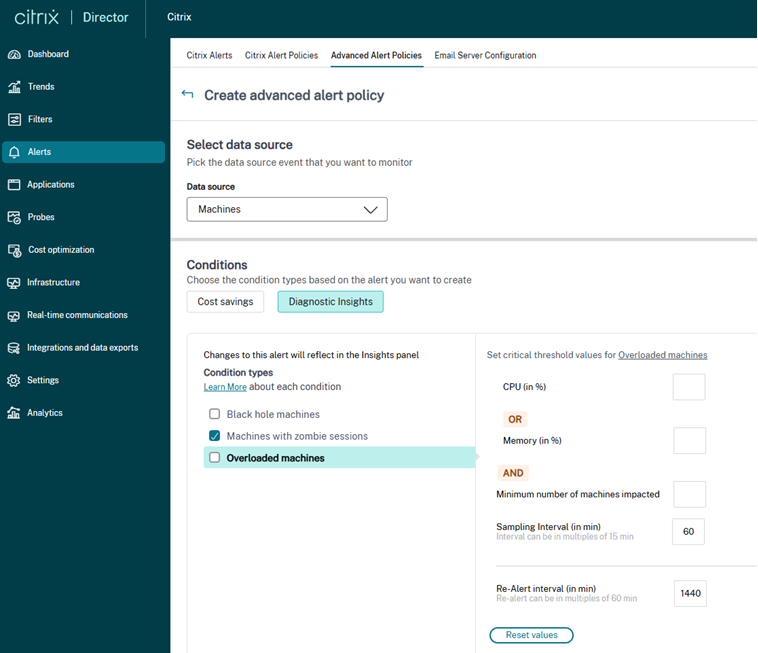
重新警报
对于特定的洞察警报,在配置的重新警报间隔内的通知行为是增量的。如果在此间隔期间识别出新的问题计算机,则重新警报电子邮件或 Webhook 将仅包含这些新计算机。每当重新警报间隔(默认情况下为 24 小时)到期时,将发送一个完整警报,其中列出给定交付组的所有问题计算机。